Streamline fetching data from Tulip to Snowflake for broader analytics and integrations opportunities
Purpose
This guide walks through step by step how to fetch data from Tulip tables into Snowflake via Microsoft Fabric (Azure Data Factory).
A high-level architecture is listed below:
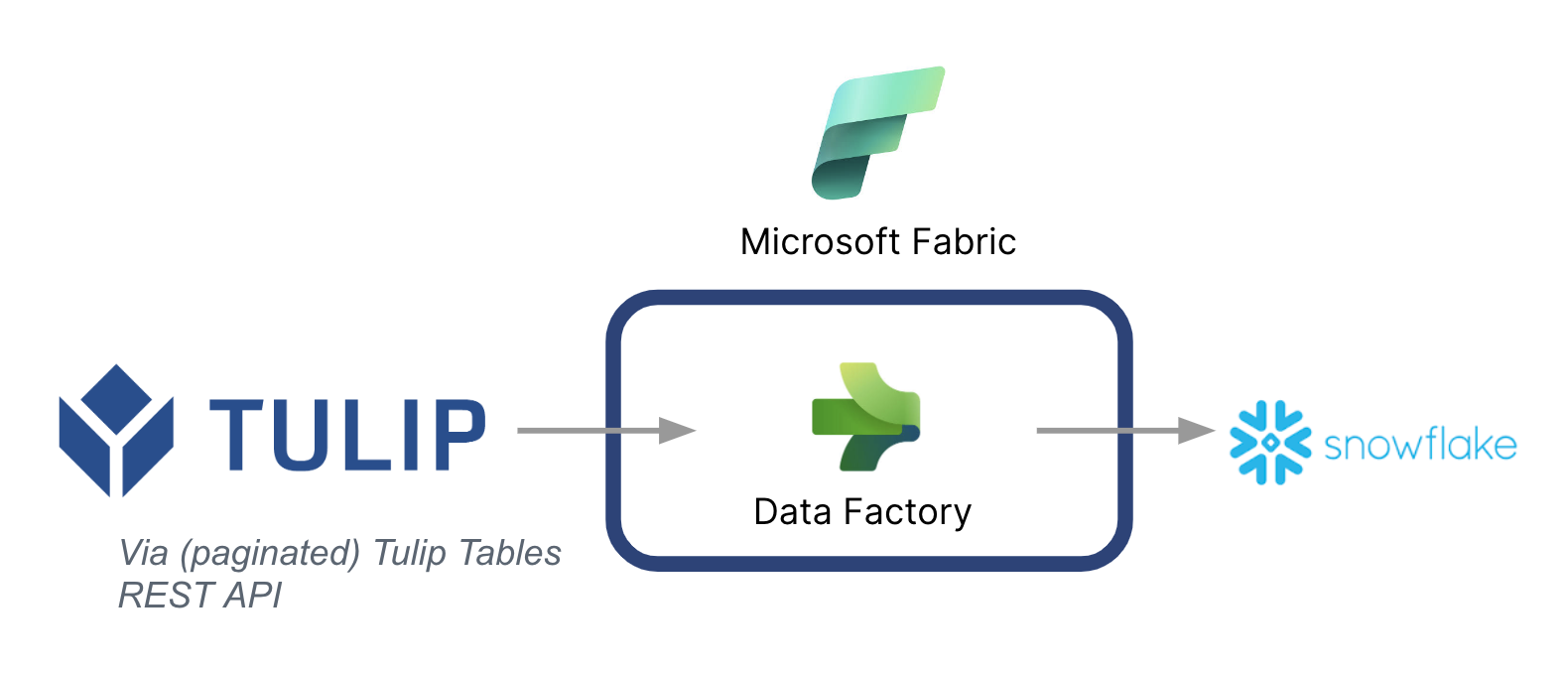
It's critical to note that Microsoft can be used as a data pipeline to sync data from Tulip to other data sources -- Even non-Microsoft data sources.
Microsoft Fabric Context
Microsoft Fabric includes all the relevant tools for end-to-end data ingestion, storage, analysis, and visualization.
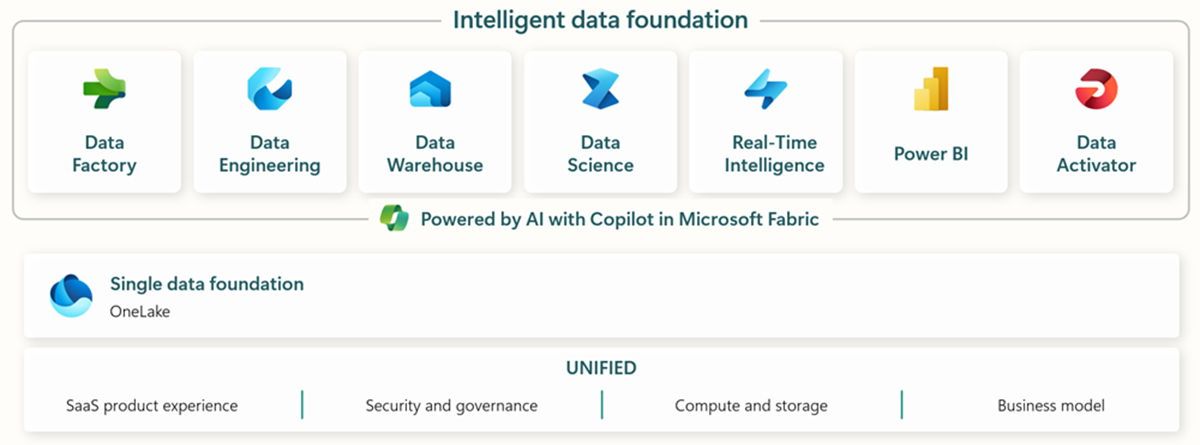
Specific services are summarized below:
- Data Factory - ingest, copy, or extract data from other systems
- Data Engineering - transform and manipulate data
- Data Warehouse - store data on a SQL Data Warehouse
- Data Science - Analyze data with hosted notebooks
- Real Time Analytics - Make use of streaming analytics and visualization tools under a single framework of Fabric
- PowerBI - Enable enterprise insights with PowerBI for business intelligence
Check out this link for more information on Microsoft Fabric
However, specific capabilities can also be used in conjunction with other data clouds. For example, Microsoft Data Factory can work with the following non-Microsoft data stores:
- Google BigQuery
- Snowflake
- MongoDB
- AWS S3
Check out this link for more context
Value Creation
This guide presents a simple way to batch fetch data from Tulip into Snowflake for broader enterprise-wide analytics. If you are using Snowflake to store other enterprise data, this can be a great way to contextualize it with data from the shop floor to make better data-driven decisions.
Setup Instructions
Create a data pipeline on Data Factory (In Fabric) and make the source REST and the sink Snowflake
Source Config:
- On Fabric homepage, go to Data Factory
- Create a new Data Pipeline on Data Factory
- Start with the "Copy Data Assistant" to streamline creation process
- Copy Data Assistant Details:
- Data Source: REST
- Base URL: https://[instance].tulip.co/api/v3
- Authentication type: Basic
- Username: API Key from Tulip
- Password: API Secret from Tulip
- Relative URL: tables/[TABLE_UNIQUE_ID]/records?limit=100&offset={offset}
- Request: GET
- Pagination Option Name: QueryParameters.{offset}
- Pagination Option Value: RANGE:0:10000:100
- Note: Limit can be lower than 100 if needed, but the increment in the pagination needs to match
- Note: the Pagination Value for the range needs to be greater than the number of records in the table
Sink (Destination) Config:
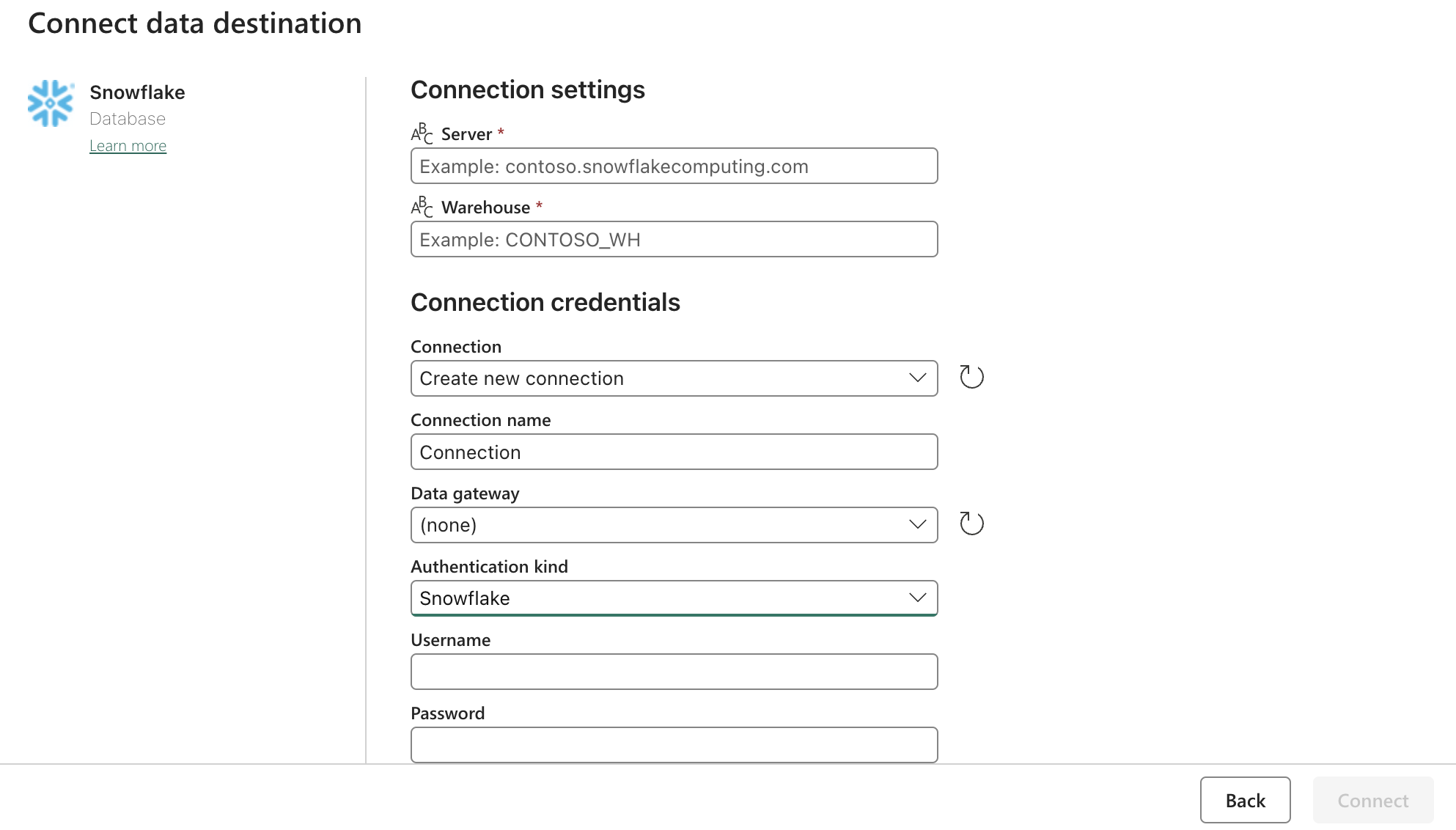
Update the Snowflake OAuth2.0 settings with form above. Then configure the triggers to be on a relevant action, manual, or timer.
Next Steps
Once this is done, explore additional features such as data cleaning inside of fabric using data flows. This can reduce data errors prior to loading it in other locations such as Snowflake