

このガイドでは、次のことを学びます:-Tulipにデータを保存する場合と外部システムに保存する場合 - 他のシステムからデータを引き出す方法 - Tulipとシステムを統合するために必要なもの
業務では、Tulipや外部の複数のソースからデータを取得することがよくあります。外部データソースの場合は、チューリップ経由で接続する必要があります。
Establishing secure data connections may require IT personnel.
データをTulipに保存する場合と外部システムに保存する場合
Tulipでは、2つの場所にデータを保存できます:
- テーブル
- コンプリート
チューリップのデータ(工程データ、作業指示、設備など)は、デジタル業務から直接更新されます。
しかし、生産工程で参照するデータが別の場所に保存されている場合はどうでしょうか?これには以下が含まれます:
- ERP/WMSシステム
- レガシーMES
- データベース
- PLM(部品表など)
- 品質管理システム(QMS)
外部データとのやり取りは、データの使用目的(API/SQLデータベースへのデータの読み書きや、生産参照用の管理データの閲覧など)に応じて、さまざまな方法で行うことができます。
単一の真実源は、正確でリアルタイムなデータに不可欠な要素である。ソース・オブ・トゥルースは、データが複数の場所で重複したり表現されたりしないことを保証します。
外部システムは、デジタル・ワークフローのコンテキストのために、明確な要件、ビジネス指標、または顧客データを提供します。
この図は、TulipとERPのデータの分離を示しています。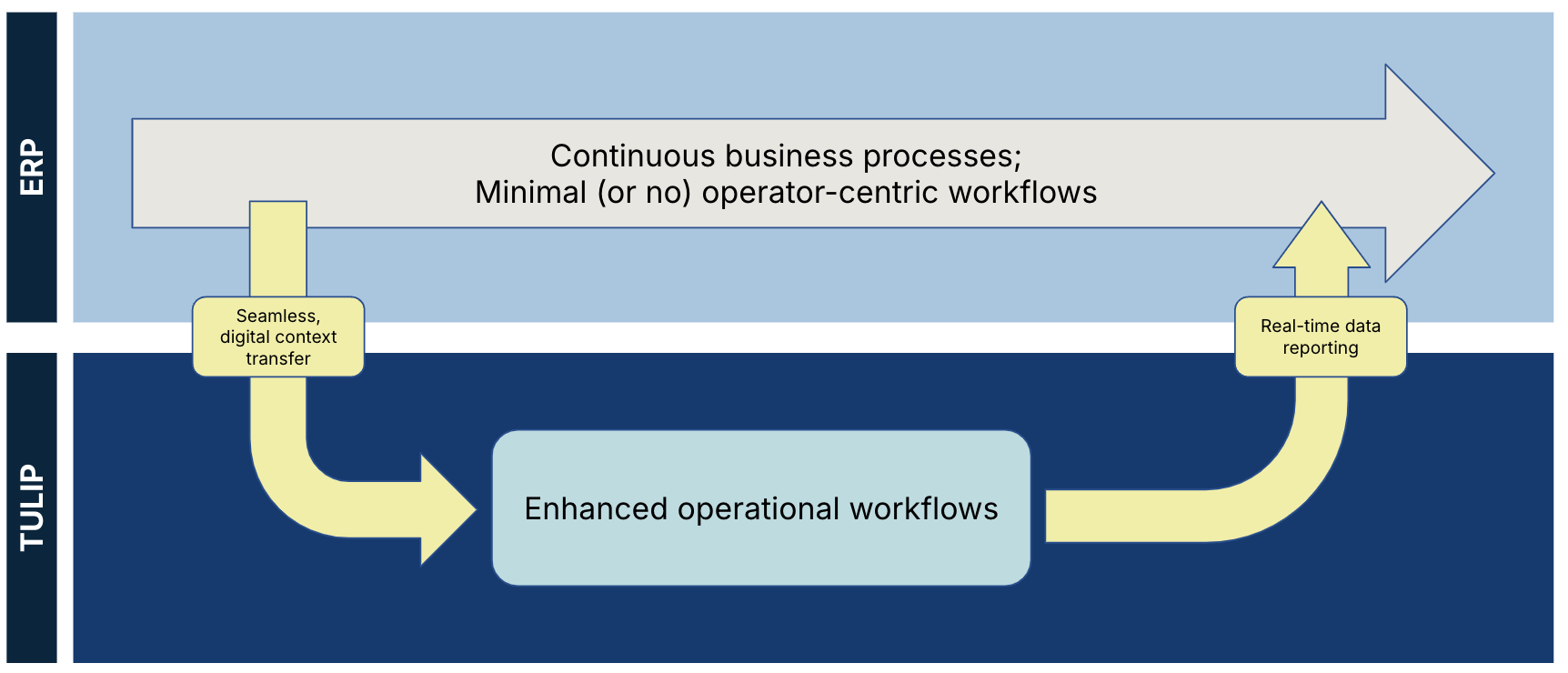
外部ソースからのデータは、必要に応じてのみ使用すべきです。これは、Tulipのデータが外部ソースからの情報を補完している間に、別のシステムが生産のためのコンテキスト情報を提供できることを意味します。
統合せずにソリューションから最小限の価値しか得られていないか**?**
統合は、価値の階層を解き放つものであるべきだが、潜在的な価値にとって不可欠なものではない。
例ERPからの作業指示
- 作業指示はERPに保存されている
- チューリップの管理アプリがERPから作業指示を取得
- 管理アプリが作業指示のレコードをチューリップのテーブルに作成し、生産データを保存する
- 作業指示と組み立てアプリは、作業指示テーブルに生産データを取り込み、完成品に準拠したプロセスデータを取り込む
オープンなエコシステム
オープン・エコシステムは、組織独自のニーズに対応するために、複数の接続されたソリューションを活用します。Tulipのオープンエコシステムアプローチは、1つのシステムをすべてに使用するのではなく、トップダウンの管理よりもComposabilityを優先します。
下図は、チューリップのデジタル機能が他のシステムとどのように統合されているかを示しています。
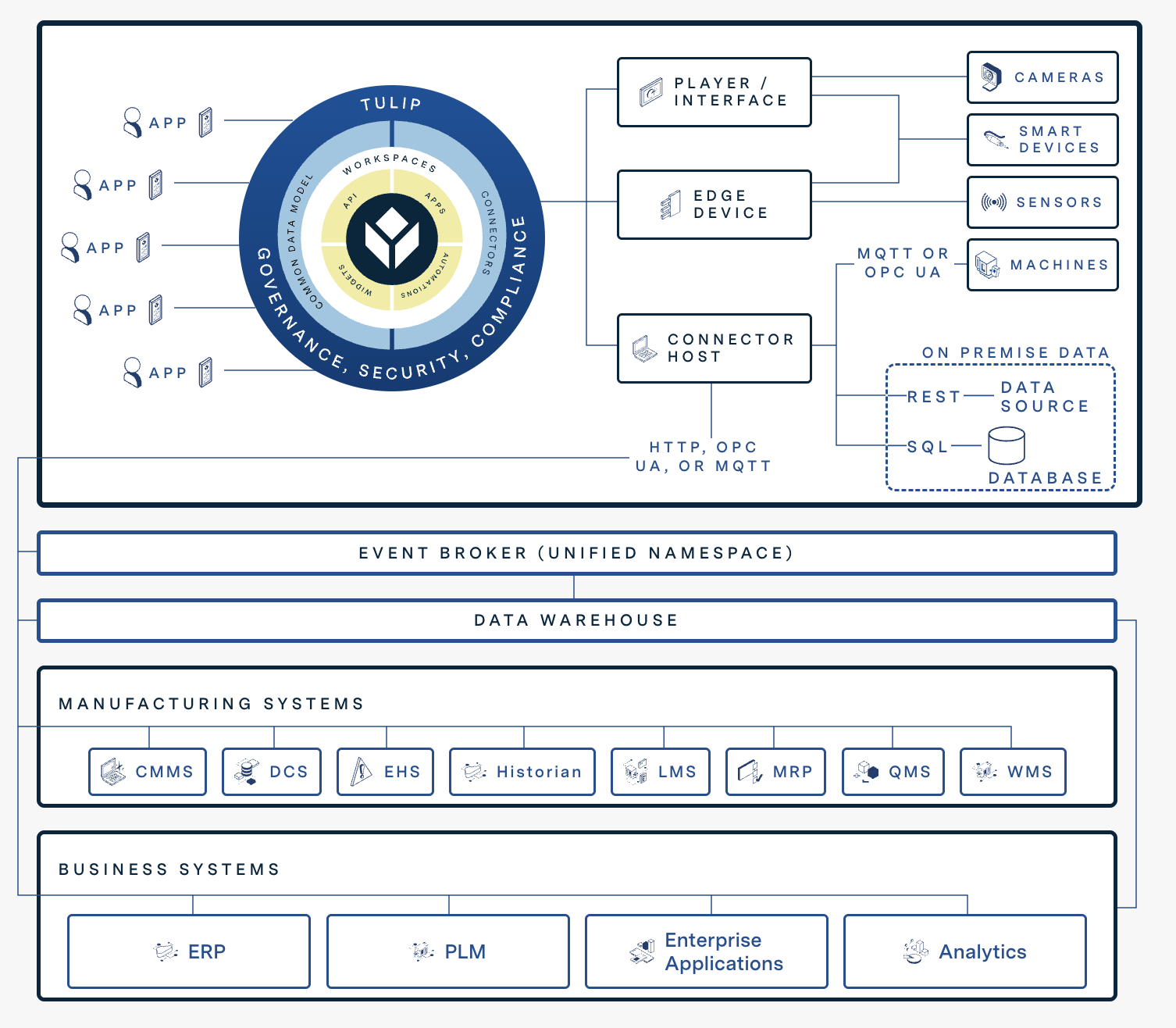 {高さ="" 幅=""}
{高さ="" 幅=""}
システム統合
システム統合は通常、導入時の最初のステップにある必要はありません。Tulipでは、まずシステム統合なしで最小限の価値ある製品を構築し、必要に応じて調整することを推奨しています。これは、システム統合のセットアップに数ヶ月かかることがあるためです。
チューリップとのシステム統合には通常、次の3つの要素が関係します。 - システム自体の能力とパラメーター - 貴社のIT環境の複雑さ - システムを扱うITチームの能力
統合はオール・オア・ナッシングではありません。アプリで業務コンテキストを提供するために必要な最小限のデータを定義することに集中すべきです。
下図は、Tulipとの典型的なERP統合を示しています。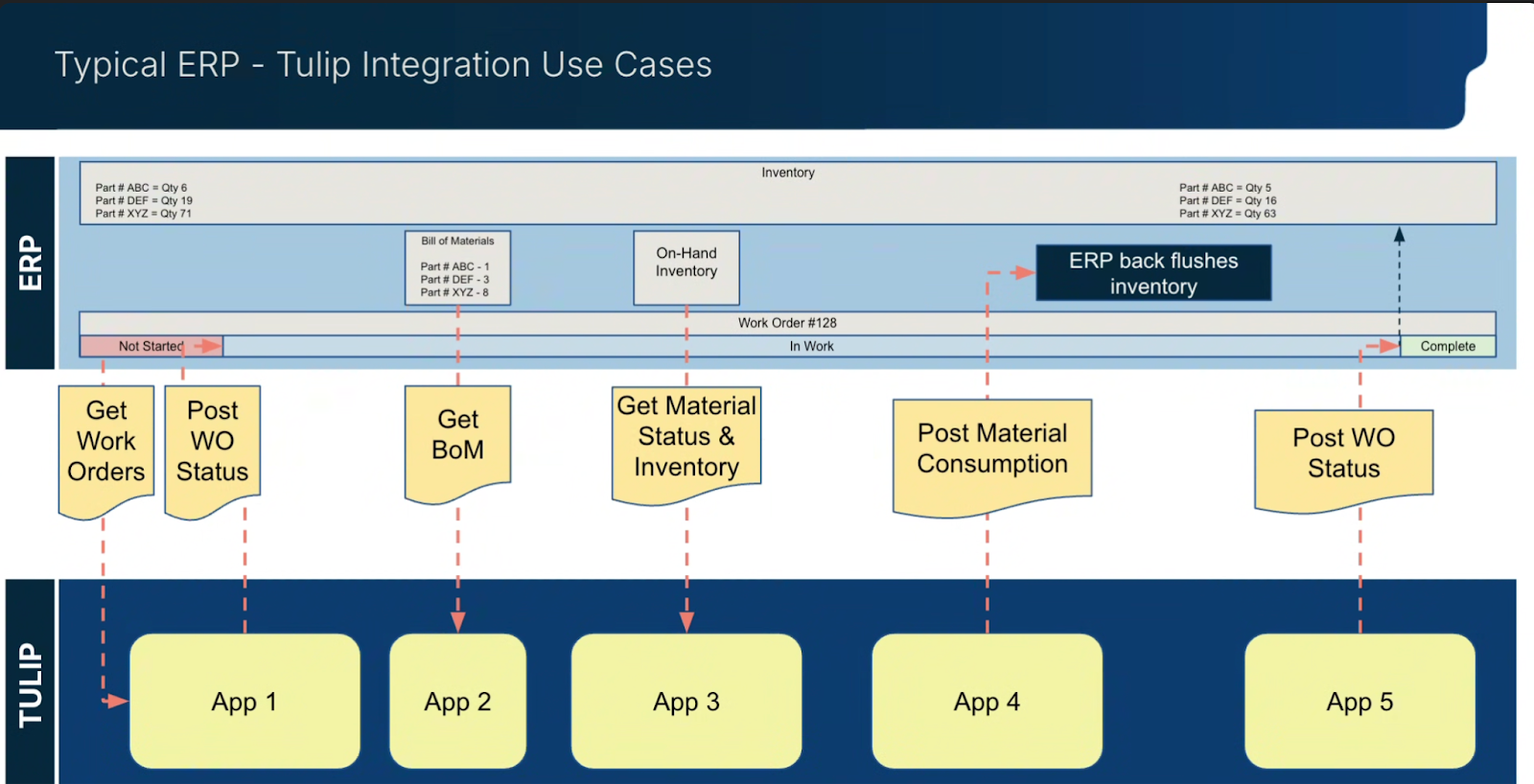
統合の計画方法については、こちらをご覧ください。
統合データの流れ
Tulipが外部システムと「会話」する方法は、次のように設定します。* コネクタは、システムへの「アクセス」を取得するために安全なパラメータを使用します。* コネクタ関数は、システムとの間で情報をコマンドします。* トリガーアクション(App Editorで作成)は、コネクタ関数を実行します(例:ボタン押下時)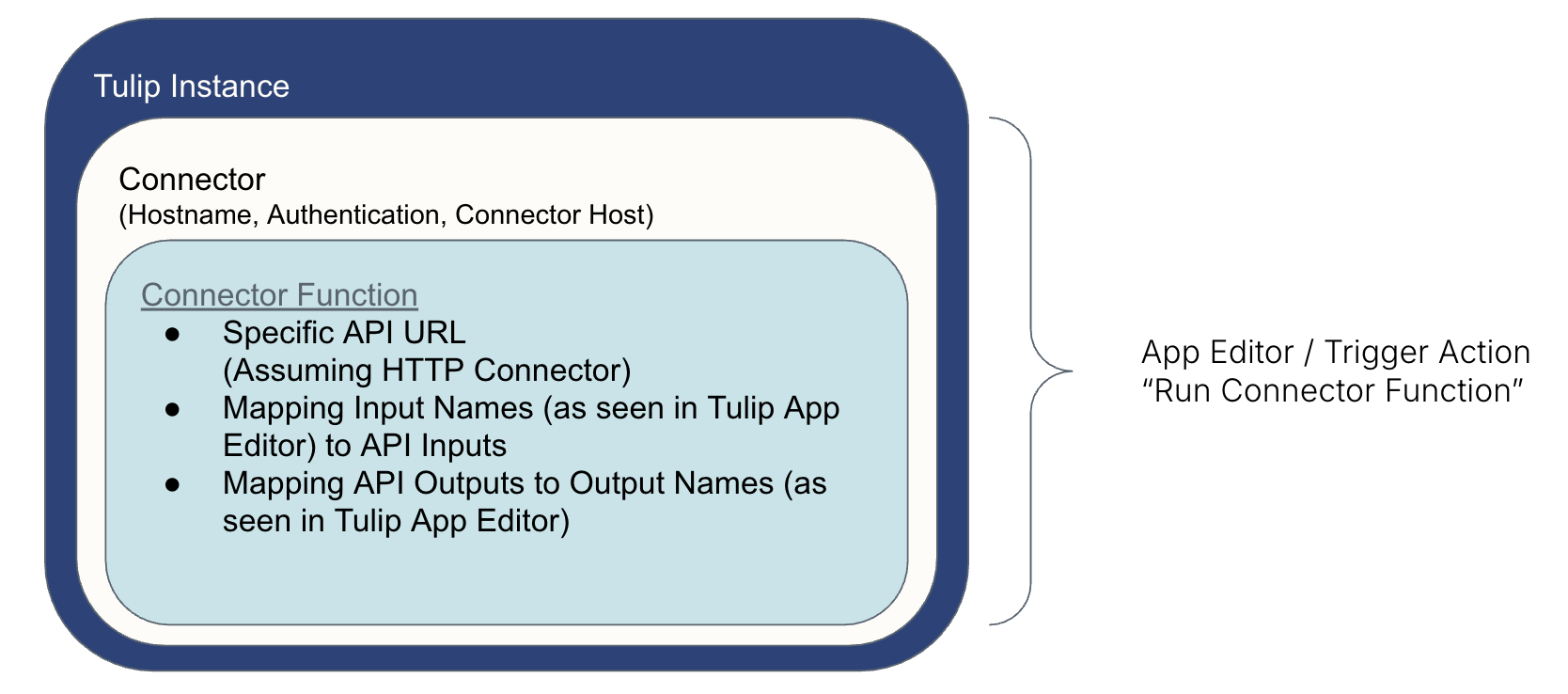
どのようにシステムに接続するのか?
これらの接続を可能にする機能を探り、分解してみましょう。
コネクタ
コネクタは、Tulipとサードパーティシステム間の接続を作成するためのTulipのフレームワークです。アプリケーションで外部システムのデータを表示、管理、対話するための強力な統合機能です。
コネクタの用途
コネクタは、Tulipが外部システムと通信する方法です。スタック内のツールと、アプリケーションで必要とされる統合の度合いによって、コネクタの使い方が決まります。
コネクタの使用例には次のようなものがあります:* 真の情報源から情報を取得する(例:ERPからの作業指示)* 材料の消費量を投稿する(例:ERPへ)* Slackメッセージを送信する
コネクタの仕組み
コネクターは、Tulipとサードパーティシステム間の接続を確立します。コネクターは、データのトランザクションを可能にする方向性と認証を処理します。
データのトランザクションは、コネクタホストを通して可能になります。コネクタホストは、チューリップが外部システムと接続することを可能にし、両者間の直接リンクとして機能します。Tulipはクラウドコネクタホストを提供していますが、オンプレミスのコネクタホストを使用することもできます。
コネクタホストについてはこちらをご覧ください。
コネクタホストが接続を確立する間、コネクタファンクションはコネクタに情報の引き出し、テーブルへの書き込み、既存データの編集などの処理を行わせます。コネクタファンクションは、コネクタホストを経由するサードパーティシステムにアクションを要求します。
また、クエリパラメータやレスポンスなど、返されるデータを指示するファンクションへの変更を設定することもできます。glossary.JSON}}の予備知識は必要ありませんが、Dot Notationや一般的なデータ構造などの側面に精通していると、コネクタ関数をより理解するのに役立ちます。
コネクタの種類
接続できるさまざまなシステムを理解するために、異なるソースから情報を抽出する3つの異なるタイプのコネクタがあることに注意することが重要です:
HTTP
HTTPコネクタは、外部APIからデータにアクセスします。最もよく使われるコネクタです。HTTPコネクターは、RESTやSOAPを含むほとんどのタイプのHTTP APIとインターフェースできます。
HTTP コネクタの関数は、以下のAPI Call タイプのAPI Call を実行できます:
- GET
- HEAD
- POST
- PUT
- バッチ
- 削除
SQL
SQL コネクタは外部データベースからデータにアクセスします。SQLコネクタを使用すると、テーブルデータを変更したり、データを取得したり、既存のデータセットを操作したりできます。
Tulipは以下のSQLコネクタをサポートしています:
- Microsoft SQL Server
- PostgreSQL
- MySQL
- オラクル
インスタンスのコネクターページからHTTPコネクターとSQLコネクターにアクセスしてください。
 {高さ="" 幅=""}。
{高さ="" 幅=""}。
MQTT
マシンモニタリングのためにMQTTブローカーに接続します。Tulipは、自社製品からMQTTブローカーにネイティブにデータを公開でき、統合ネームスペースやエンタープライズ・イベント・バスにシームレスに統合できます。
MQTTコネクター機能には、次のフィールドを定義できます: - サービス品質 - トピック - メッセージの保持 - ペイロード - ユーザー定義入力
エッジ接続
これらのマシンの中にはエッジ・デバイスが含まれています:
テーブルAPI
コネクターを使って、TulipアプリはHTTPまたはSQLクエリーを開始できます。Tulip APIを使用すると、外部システムからTulipと通信し、統合することができます。このAPIは、他のシステムからTulipにデータを取り込み、他のシステムに書き込むことができます。テーブルAPIは以下のような様々な機能を持っています:* テーブルレコードの更新* テーブルの作成* テーブルレコードの数の検索
Tulip APIは現在、Tulipテーブルでのみ動作します。テーブルAPIを使用するには、APIがどのように動作するかについての基本的な理解が必要です。
ここからTulip APIドキュメントにアクセスしてください。
テーブルAPIの使い方を練習するには、Tulip Universityのコースを受講してください:機能ディープダイブ:テーブルAPI
次のステップ
お探しのものは見つかりましたか?
community.tulip.coに質問を投稿したり、他の人が同じような質問に直面していないか確認することができます!