

In questa guida imparerete:- Quando archiviare i dati in Tulip rispetto a un sistema esterno- Come estrarre i dati da altri sistemi- Cosa serve per integrare un sistema con Tulip
Le operazioni spesso attingono dati da più fonti, sia in Tulip che esterne. Per le fonti di dati esterne, è necessario collegarsi tramite Tulip.
Establishing secure data connections may require IT personnel.
Quando archiviare i dati in Tulip rispetto a un sistema esterno
In Tulip, è possibile memorizzare i dati in due luoghi:
- Tabelle
- Completamenti
I dati di Tulip (ad esempio, dati di processo, istruzioni di lavoro, attrezzature) vengono aggiornati direttamente dalle operazioni digitali.
Ma che dire dei dati a cui si fa riferimento in produzione e che sono archiviati altrove? Questi dati possono includere:
- Sistemi ERP/WMS
- MES tradizionali
- database
- PLM (ad esempio per la distinta base)
- Sistema di gestione della qualità (QMS)
È possibile interagire con i dati esterni in vari modi, a seconda dell'uso che se ne fa (ad esempio, lettura e scrittura di dati su database API/SQL o visualizzazione di dati di gestione per riferimento alla produzione).
Una singola fonte di verità è un componente essenziale per ottenere dati accurati e in tempo reale. Una fonte di verità garantisce che i dati non siano duplicati o rappresentati in più luoghi.
Sia i dati Tulip che i dati esterni sono rispettive fonti di verità e nessuno dei due dovrebbe essere sostituito o replicato: - un sistema esterno fornisce requisiti chiari, metriche aziendali o dati dei clienti per il contesto del flusso di lavoro digitale; - i dati Tulip contengono dati operativi e di processo per il reporting in tempo reale.
Questo diagramma mostra la separazione dei dati da Tulip e da un ERP: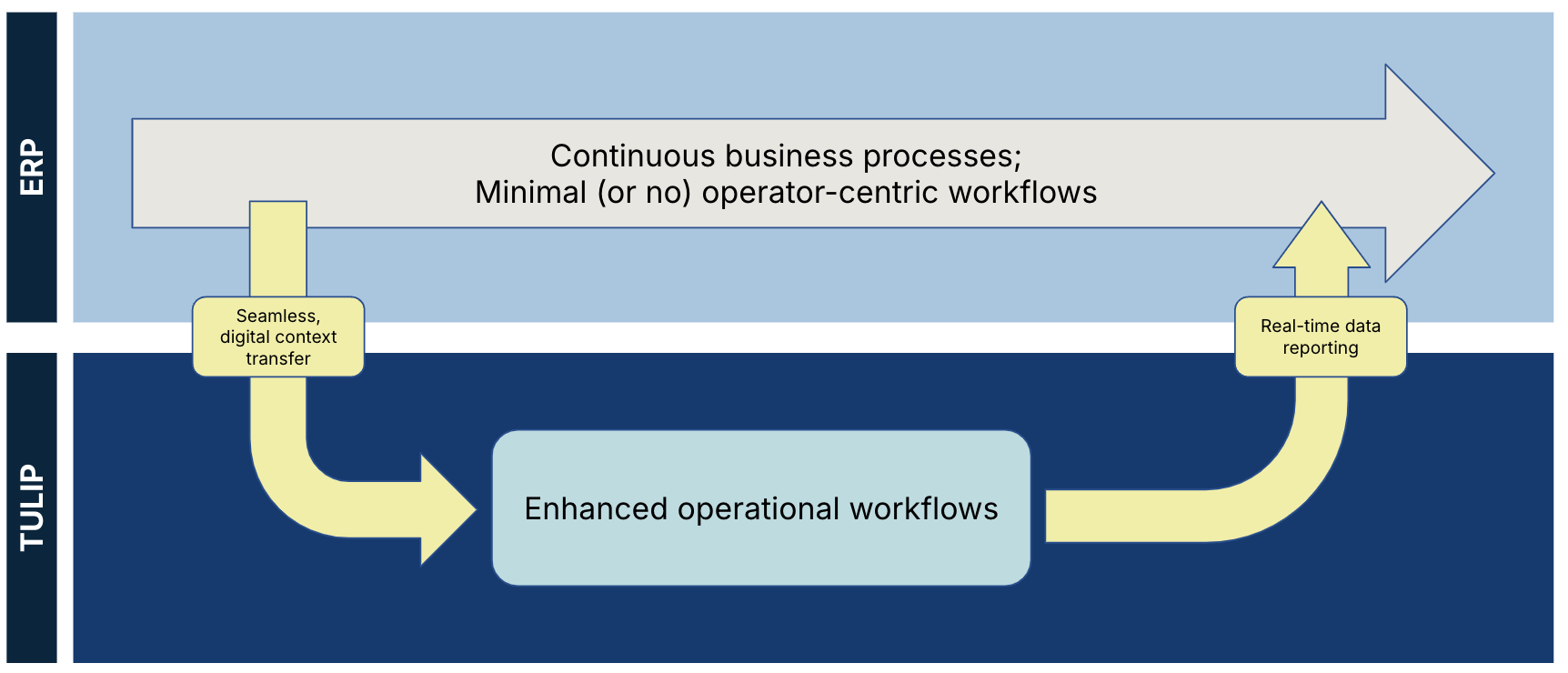
I dati provenienti da fonti esterne dovrebbero essere utilizzati solo in caso di necessità. Questa pratica significa che un altro sistema può fornire informazioni contestuali per la produzione mentre i dati di Tulip migliorano le informazioni provenienti da una fonte esterna.
Come si fa a sapere se si devono usare dati esterni?- Si ottiene un valore minimo dalla soluzione senza integrazione? - Si è in grado di integrare rapidamente (meno di un mese)?
Le integrazioni dovrebbero sbloccare un livello di valore, ma in genere non sono essenziali per il valore potenziale.
Esempio: Ordini di lavoro da un ERP
- Gli ordini di lavoro sono archiviati in un ERP
- Un'applicazione di gestione Tulip recupera l'ordine di lavoro dall'ERP
- L'applicazione di gestione crea un record dell'ordine di lavoro in una tabella Tulip per memorizzare i dati di produzione.
- Le applicazioni per le istruzioni di lavoro e l'assemblaggio acquisiscono i dati di produzione nella tabella degli ordini di lavoro e i dati di processo conformi nelle compilazioni.
Ecosistema aperto
Un ecosistema aperto sfrutta soluzioni multiple e connesse per soddisfare le esigenze specifiche di un'organizzazione. Piuttosto che utilizzare un sistema per tutto, l'approccio di Tulip all'ecosistema aperto dà la priorità alla Composability rispetto al controllo dall'alto verso il basso.
Il diagramma seguente mostra come le funzionalità digitali di Tulip si integrano con altri sistemi.
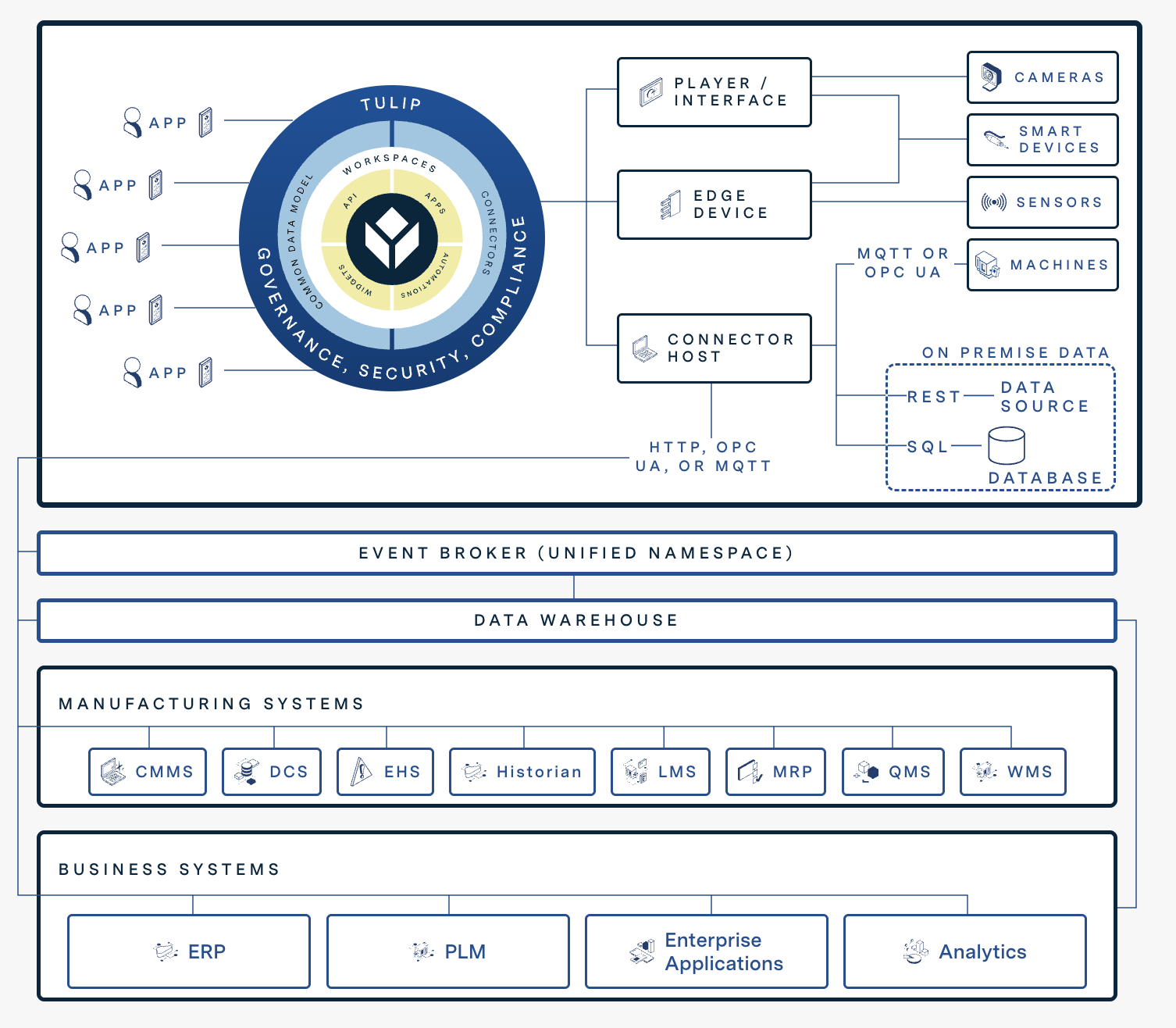
Integrazione del sistema
Le integrazioni di sistema in genere non devono essere presenti nella prima fase della distribuzione. Tulip consiglia di creare prima il prodotto di valore minimo senza integrazione di sistema e poi di apportare le modifiche necessarie. Questo perché le integrazioni di sistema possono richiedere fino a diversi mesi di lavoro.
L'integrazione di un sistema con Tulip è solitamente legata a tre fattori: - le capacità e i parametri del sistema stesso; - la complessità dell'ambiente IT della vostra azienda; - le capacità del vostro team IT di lavorare con il sistema.
Le integrazioni non sono tutto o niente: è necessario concentrarsi sulla definizione dei dati minimi necessari per fornire un contesto operativo in un'applicazione.
Il diagramma seguente mostra una tipica integrazione ERP con Tulip: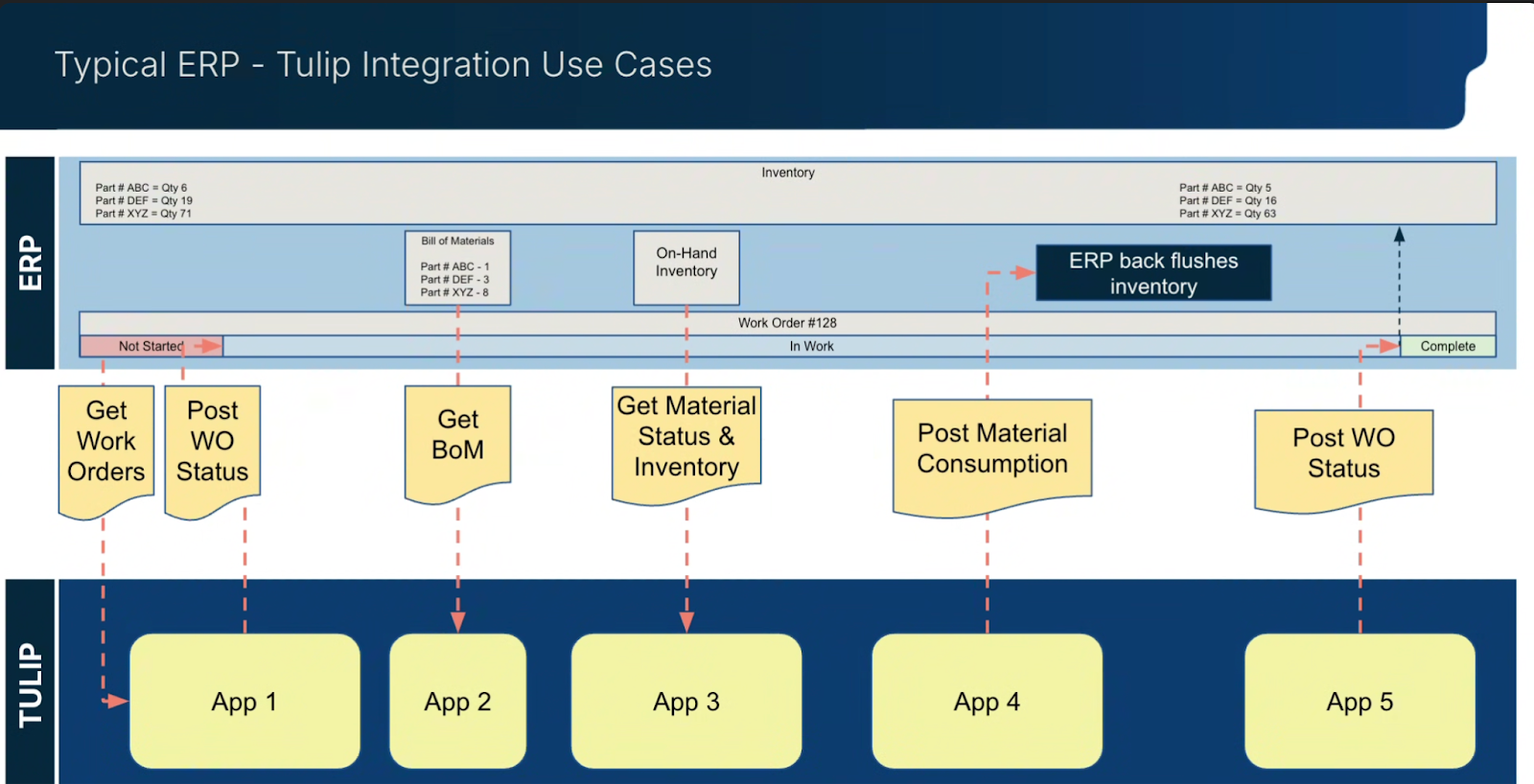
Per saperne di più su come pianificare un'integrazione , cliccate qui.
Flusso di dati dell'integrazione
Il modo in cui Tulip "parla" con un sistema esterno è con la seguente configurazione:* Un connettore utilizza parametri sicuri per ottenere "l'accesso" al sistema* Una funzione del connettore comanda le informazioni da/al sistema* Un'azione di trigger (creata nell'App Editor) esegue la funzione del connettore (ad esempio alla pressione di un pulsante)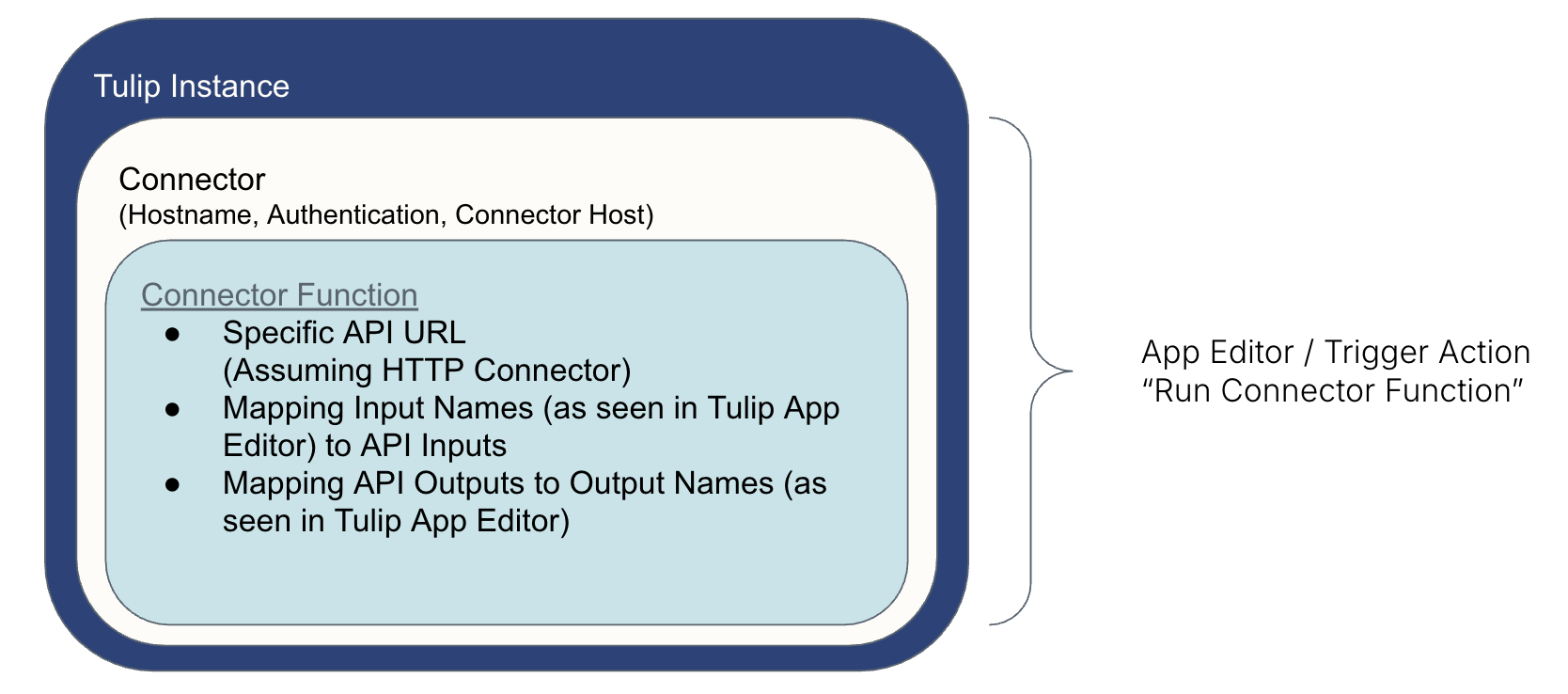
Come ci si collega a un sistema?
Esploriamo e analizziamo le caratteristiche che rendono possibili queste connessioni.
Connettori
I connettori sono la struttura di Tulip per creare connessioni tra Tulip e sistemi di terze parti. Sono potenti integrazioni per visualizzare, gestire e interagire con i dati di sistemi esterni nelle applicazioni.
Per cosa usare i connettori
I connettori sono il modo in cui Tulip parla con i sistemi esterni. Gli strumenti presenti nel vostro stack e il grado di integrazione richiesto nelle vostre applicazioni determinano l'uso dei connettori.
Alcuni casi d'uso dei connettori sono:* Ottenere informazioni da una fonte di verità (ad esempio, gli ordini di lavoro dall'ERP)* Registrare il consumo di materiale (ad esempio, all'ERP)* Inviare un messaggio Slack
Come funzionano i connettori
I connettori stabiliscono una connessione tra Tulip e un sistema di terze parti. Gestiscono la direzione e l'autenticazione che consente la transazione dei dati.
La transazione dei dati è resa possibile da un host del connettore. Gli host del connettore consentono a Tulip di connettersi con sistemi esterni, agendo come un collegamento diretto tra i due. Tulip fornisce un host connettore nel cloud, ma è possibile utilizzare anche un host connettore in sede.
Per saperne di più sugli host connettore , cliccate qui.
Mentre l'host del connettore stabilisce la connessione, le funzioni del connettore fanno sì che i vostri connettori facciano cose come estrarre informazioni, scrivere su tabelle e modificare i dati esistenti. Le funzioni del connettore richiedono azioni al sistema di terze parti che passano attraverso l'host del connettore.
Si possono anche impostare modifiche alla funzione, come i parametri della query e le risposte, che dettano i dati restituiti. Sebbene non sia richiesta una conoscenza preliminare di {{glossario.JSON}}, la familiarità con aspetti quali {{glossario.Dot Notation}} e la struttura generale dei dati è utile per comprendere meglio le funzioni del connettore.
Tipi di connettori
Per comprendere i diversi sistemi a cui ci si può connettere, è importante notare che esistono tre diversi tipi di connettori che estraggono informazioni da fonti diverse:
HTTP
I connettori HTTP accedono ai dati da API esterne. Sono i connettori più comunemente utilizzati. I connettori HTTP possono interfacciarsi con la maggior parte dei tipi di API HTTP, tra cui REST e SOAP.
Le funzioni dei connettori HTTP possono effettuare i seguenti tipi di {{glossario.Chiamata API}}:
- GET
- TESTA
- POST
- INVIO
- LANCIO
- CANCELLARE
SQL
I connettori SQL accedono ai dati di database esterni. Con un connettore SQL è possibile modificare i dati della scheda, recuperare i dati e manipolare un set di dati esistente.
Tulip supporta i seguenti connettori SQL:
- Microsoft SQL Server
- PostgreSQL
- MySQL
- Oracle
Accedere ai connettori HTTP e SQL attraverso la pagina Connettori della propria istanza.
MQTT
Collegatevi ai broker MQTT per il monitoraggio delle macchine. Tulip può pubblicare in modo nativo i dati dal suo prodotto al vostro broker MQTT, integrandosi perfettamente in un Namespace unificato o in un event bus aziendale.
I seguenti campi possono essere definiti per una funzione di connettore MQTT: - Qualità del servizio - Argomento - Mantenimento del messaggio - Carico utile - Ingressi definiti dall'utente.
Connettività Edge
Alcune di queste macchine includono i dispositivi Edge, di cui potete leggere qui:
Tabella API
Utilizzando i connettori, un'applicazione Tulip può avviare una query HTTP o SQL. Con l'API di Tulip, è possibile comunicare con Tulip e integrarlo da sistemi esterni. Questa API funziona portando i dati a Tulip da un altro sistema e consentendo di scrivere su questi sistemi. L'API Tabella dispone di varie funzionalità, tra cui:* Aggiornamento di un record di tabella* Creazione di una tabella* Ricerca dei conteggi dei record di tabella
L'API di Tulip funziona attualmente solo con le tabelle di Tulip. Per utilizzare l'API Table, è necessario avere una conoscenza di base del funzionamento delle API.
Accedere alla documentazione dell'API Tulip qui.
Per esercitarsi nell'uso dell'API Table, seguire il corso della Tulip University: Feature Deep Dive: Table API.
Prossimi passi
Per saperne di più sulle integrazioni e iniziare a connettersi:* Come creare un connettore* Come impostare i connettori rapidi
Avete trovato quello che cercavate?
Potete andare su community.tulip.co per postare la vostra domanda o vedere se altri hanno affrontato una domanda simile!