
TulipからAWSへのデータ取得を合理化し、アナリティクスと統合の機会を拡大
目的
このガイドでは、Lambda関数を介してAWSにTulip Tablesのデータをフェッチする方法をステップバイステップで説明します。
Lambda関数は、Event BridgeタイマーやAPI Gatewayのような様々なリソースを介してトリガーすることができます。
アーキテクチャの例を以下に示します:
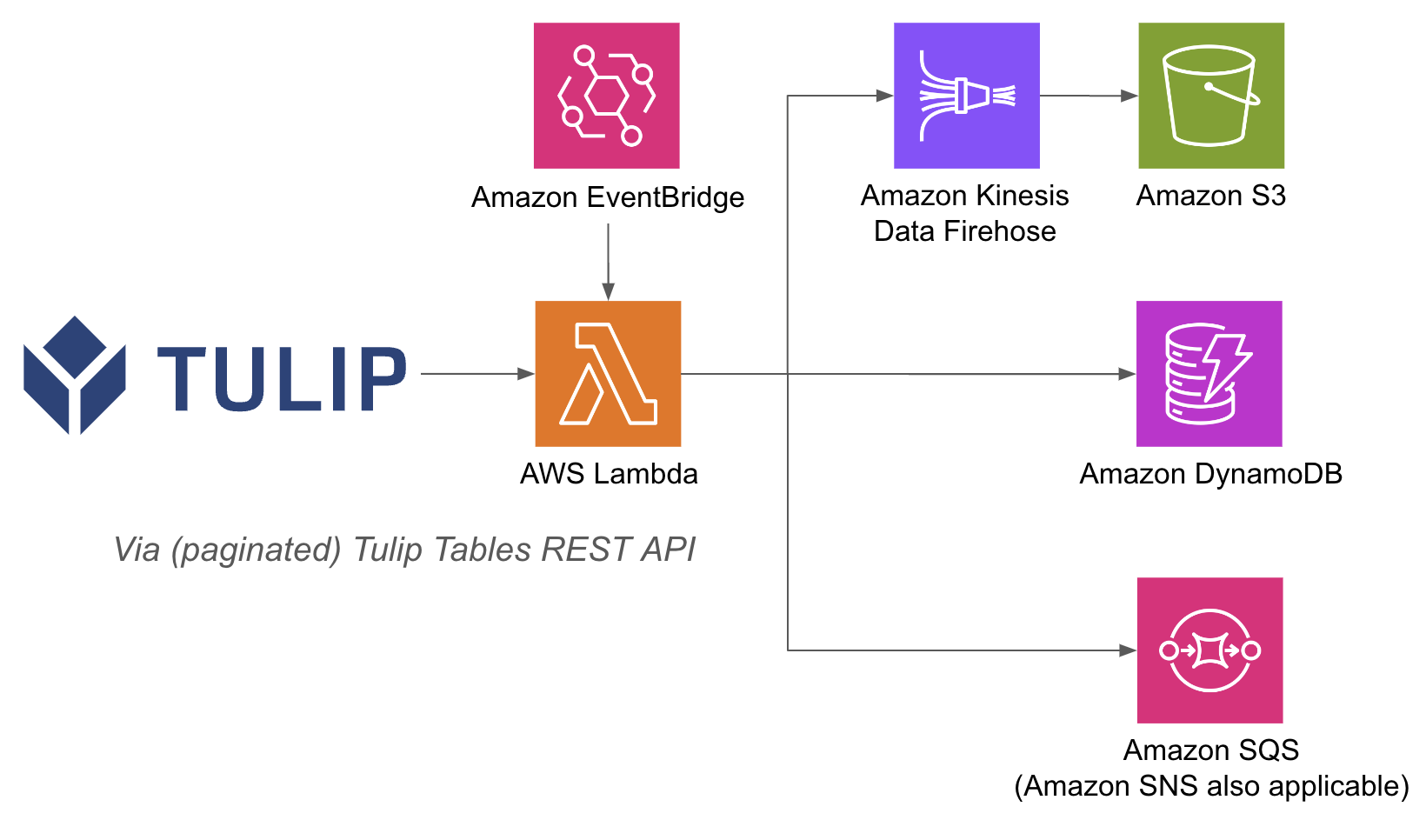
API GatewayとLambda関数を使えば、Tulip側でデータベースをユーザー名とパスワードで認証する必要がなく、AWS内部のIAM認証メソッドに頼ることができるので、Lambda関数内でAWSの操作を実行するのが簡単になります。 また、RedshiftやDynamoDBなど、他のAWSサービスの活用方法も効率化できます。
セットアップ
この連携例では以下のものが必要です:
- Tulip Tables APIの利用 (アカウント設定でAPIキーとシークレットを取得)
- チューリップ・テーブル(テーブル固有IDを取得する
高レベルのステップ: 1.関連するトリガー(API Gateway、Event Bridge Timerなど)でAWS Lambda関数を作成する 2.以下の例でTulipテーブルのデータを取得する ``python import json import pandas as pd import numpy as np import requests
# AWSのpandasレイヤーをLambdaに追加する必要があります。
# をLambda関数に追加する必要があります。
def lambda_handler(event, context): auth_header = OBTAIN FROM API AUTH header = {'Authorization' : auth_header} base_url = 'https://[INSTANCE].tulip.co/api/v3' offset = 0 function = f'/tables/[TABLE_ID/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=header) df = pd.DataFrame(r.json()) length = len(r.json()) while length > 0: offset += 100 function = f'/tables/[TABLE_ID/records?limit=100&offset{offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+関数, headers=cdm_header) length = len(r.json()) df_append = pd.DataFrame(r.df_append = pd.DataFrame(r. json()) df = pd.concat([df, df_append], axis=0) df.shape # これで100レコードがデータフレームに追加され、S3やFirehoseなどに利用できる # S3やFirehoseへの書き込みにはdata変数を利用する、
# データベースなどに書き込むために使用する。
- トリガーはタイマーで実行されるか、URL経由でトリガーされる
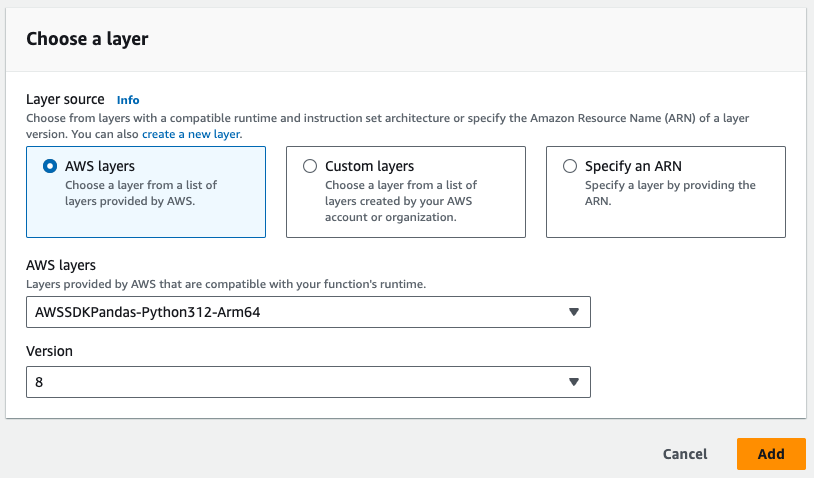
- 以下の画像では、Pandasレイヤーが必要であることに注意してください。
- 最後に、必要な統合機能を追加します。ラムダ関数からデータベース、S3、通知サービスにデータを書き込むことができる。
使用例と次のステップ
lambdaとの統合が完了したら、sagemaker notebookやQuickSight、その他様々なツールを使って簡単にデータを分析することができます。
1.不具合予測- 製造上の不具合を事前に特定し、初回不良率を向上させます。
2.品質コストの最適化- 顧客満足度に影響を与えることなく、製品設計を最適化する機会を特定する。
3.生産エネルギーの最適化 - エネルギー消費を最適化するための生産レバーを特定する。
4.納期と計画の予測と最適化 - 顧客の需要とリアルタイムの受注スケジュールに基づいて生産スケジュールを最適化する。
5.グローバルな機械/ラインのベンチマーキング- 類似の機械や設備を正規化した上でベンチマーキングする。
6.グローバル/地域デジタルパフォーマンス管理- データを統合してリアルタイムダッシュボードを作成します。