
Funzioni comuni del connettore SQL
Questo articolo descrive come scrivere alcune funzioni SQL comunemente usate in Tulip Connectors.
Prima di leggere questa guida, consultate l'altro nostro tutorial per creare la vostra prima funzione di connettore SQL in Tulip.
Di seguito sono elencate alcune funzioni SQL Connector semplici e comunemente usate che possono essere utilizzate nelle query SQL:
Dichiarazione SELECT:
Considerate uno scenario in cui volete visualizzare i dettagli di un particolare ordine di lavoro memorizzato nel vostro database MES/ERP. L'istruzione SELECT può aiutarci in questo compito:
SELECT * FROM tabella_nel_vostro_database
Questa operazione restituisce tutte le righe e le colonne della tabella.
È possibile restituire una singola riga o più righe. Se si desidera restituire una singola riga, aggiungere condizioni o limiti alla query. In questo caso si usano comunemente gli input tulipani. Nell'esempio seguente, numero_ordine_lavoro è un input della funzione Tulip.
SELEZIONA * DA tabella_nel_tuo_database DOVE colonna_1 = $numero_ordine_di_lavoro
Se si desidera restituire più righe, assicurarsi di selezionare la casella sotto "Restituire righe multiple?".
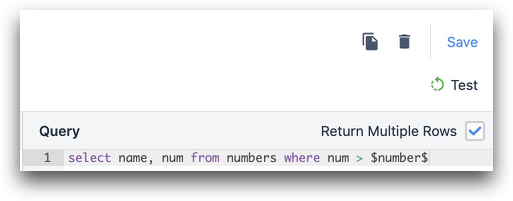
Restituzione dei dati
Se i nomi delle colonne del database corrispondono ai nomi degli output definiti nella funzione connettore, Tulip assocerà automaticamente i risultati della query agli output della funzione. Esempio: L'output di Tulip è output_1 e la colonna del database è anch'essa output_1.
Se i nomi delle colonne del database differiscono da quelli che si desidera utilizzare in Tulip, è necessario utilizzare un alias per creare l'associazione corretta tra i due.
Nell'esempio seguente, column_1 proviene dal database e output_1 è l'output di Tulip.
SELECT column_1 as output_1 FROM table_in_your_database dove primo_ vincolo = $input_1$ e secondo_ vincolo = $input_2$;
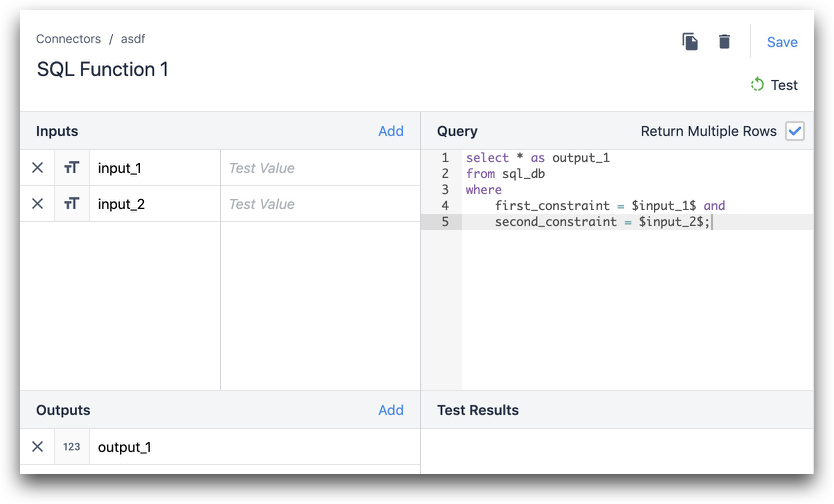
Dichiarazione INSERT:
Considerate uno scenario in cui desiderate inserire nel vostro MES/ERP i dati di un'applicazione Tulip. Per farlo, si utilizza una semplice funzione INSERT. Ecco un esempio di come si presenta questa funzione in SQL:
INSERT INTO tabella_nel_tuo_database (username, user_id, product_id) VALUES ($nomeutente$, $id utente$, $id prodotto$)
Ora analizziamo ogni parte di questa funzione:
Identificare la tabella nel database
INSERT INTO tabella_nel_tuo_database
Scegliere le colonne del database
(username, user_id, product_id)
Definire i valori da Tulip
VALUES ($nomeutente$, $id utente$, $id prodotto$)
Dichiarazione UPDATE:
Si consideri uno scenario in cui si desidera aggiornare il MES/ERP con i dati di un'applicazione Tulip, utilizzando un ordine di lavoro come chiave. Si utilizzerebbe la funzione UPDATE, come mostrato di seguito:
AGGIORNARE la tabella_nel_vostro_database SET colonna_1 = $input_1$, colonna_2 = $ingresso_2 DOVE ORDINE DI LAVORO = $ordine di lavoro
Ora analizziamo le singole parti di questa funzione:
Identificare la tabella nel database
AGGIORNARE tabella_nel_vostro_database
Definire le colonne da aggiornare con i dati di Tulip
SET colonna_1 = $input_1$, colonna_2 = $input_2$
Utilizzare l'ordine di lavoro come condizione
DOVE ordine_di_lavoro = $ordine_di_lavoro$
Ulteriori letture
Avete trovato quello che cercavate?
Potete anche andare su community.tulip.co per porre la vostra domanda o vedere se altri hanno affrontato una domanda simile!