
Objectif
Le Input Widget fonctionne parallèlement à toutes les autres entrées pour permettre à vos utilisateurs de saisir des données dans vos applications Tulip. Dans de nombreux environnements industriels, la saisie au clavier est jugée peu pratique ou simplement trop lente. Avec le widget Speech-to-text, les utilisateurs peuvent décrire le problème qu'ils rencontrent et il sera automatiquement transcrit. 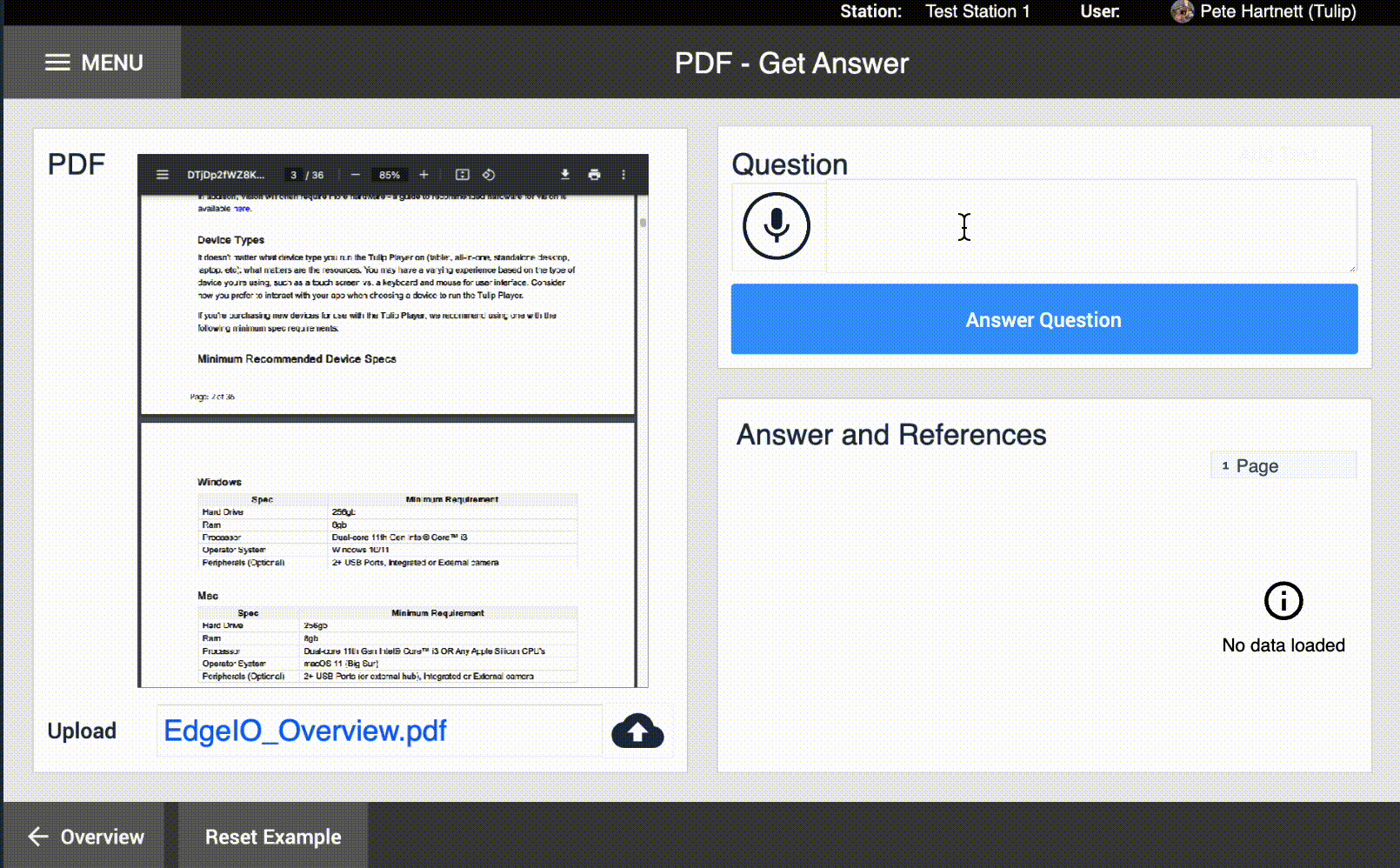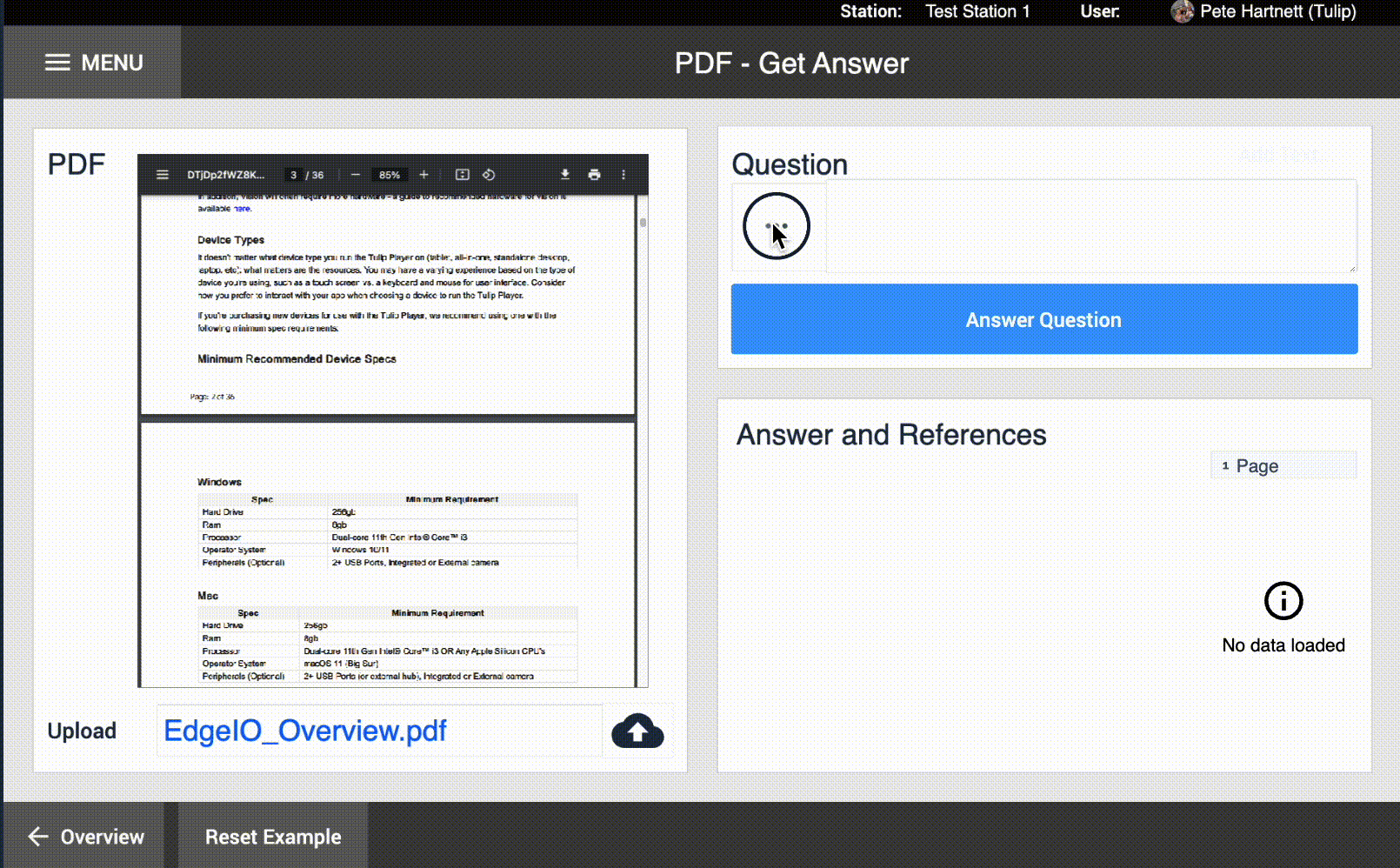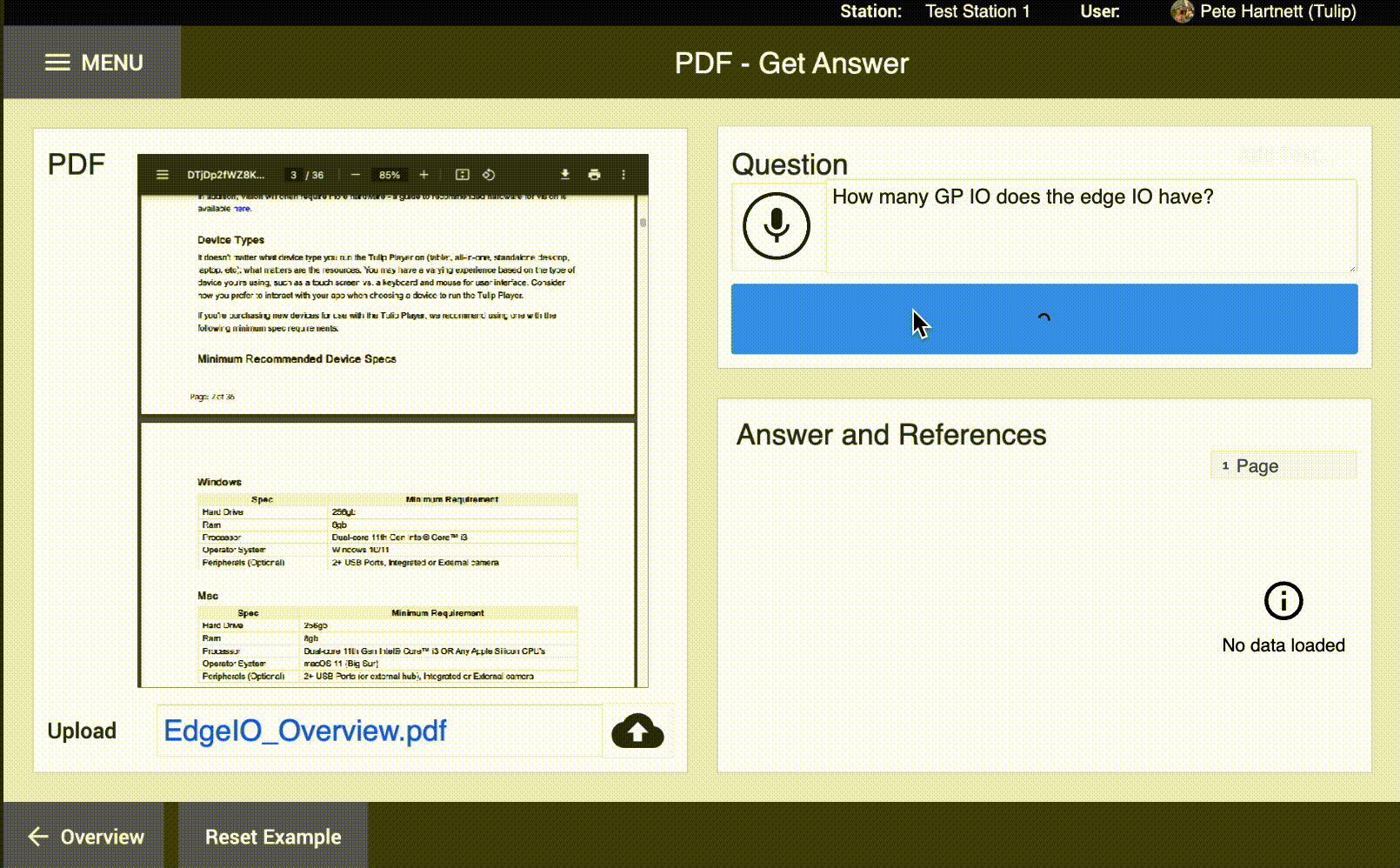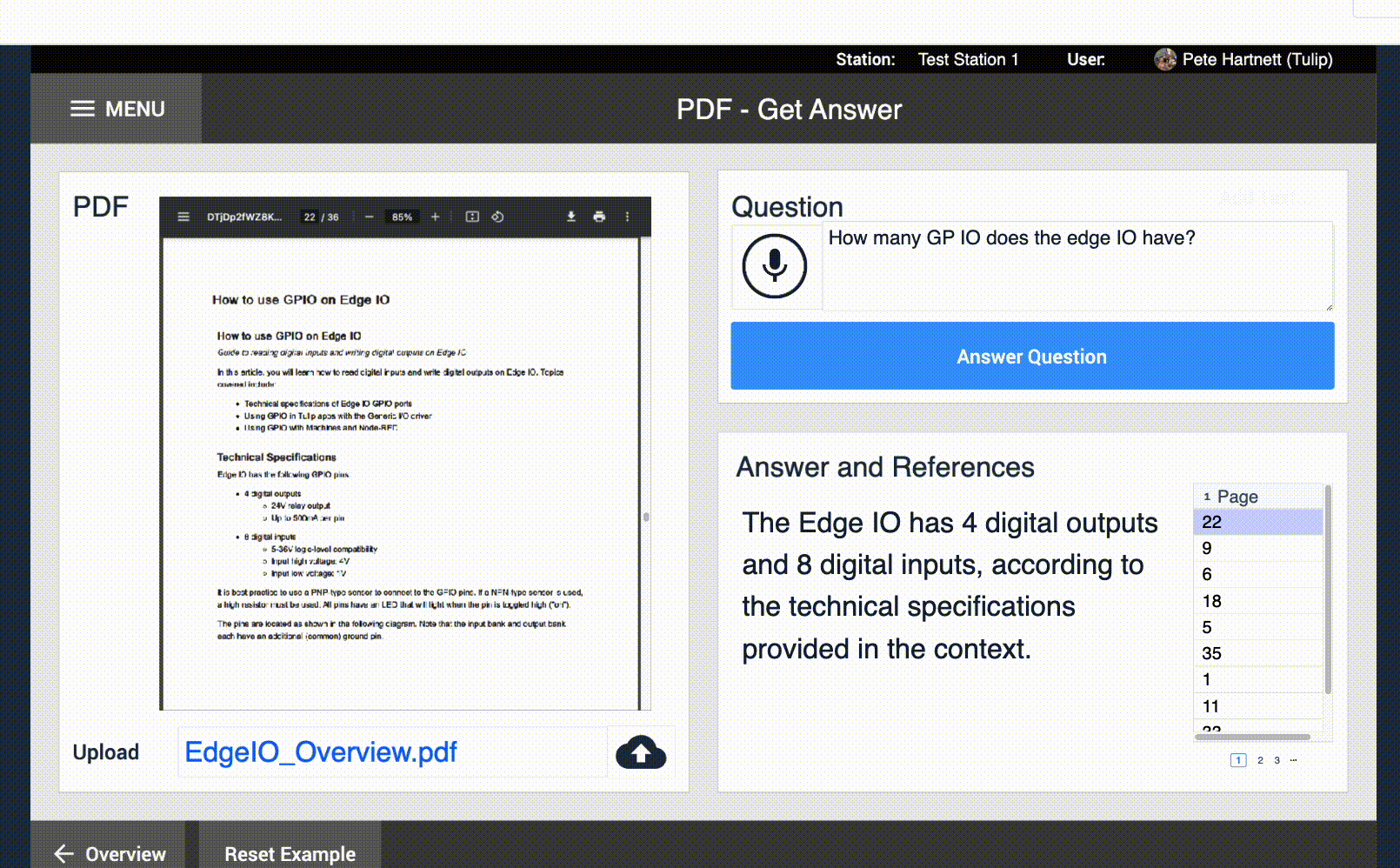
Exemples de cas d'utilisation
Combiné à d'autres actions AI Trigger, le widget Speech-to-text peut être utilisé pour changer radicalement l'expérience de l'utilisateur qui interagit avec vos systèmes et processus.
Voici quelques exemples de cas d'utilisation:* Permettre aux utilisateurs de poser des questions à un "expert" de l'IA. Supprimez la nécessité de demander l'assistance de l'employé qui peut répondre à toutes les questions en permettant aux utilisateurs de poser des questions directement à la base de données des défauts antérieurs . Recueillir des informations significatives auprès d'utilisateurs qui doivent écrire ou taper manuellement leurs résultats est une recette pour obtenir des informations inutiles. Rationalisez la collecte des données afin qu'elles puissent être recueillies aussi rapidement qu'elles peuvent être expliquées.* Guidez les utilisateurs vers la bonne ressource. Souvent, la moitié de la bataille dans un rôle est de comprendre qui est la bonne personne ou le bon service pour soulever un problème. Combinez l'entrée Speech-to-text avec le déclencheur Classify pour déterminer la bonne ressource vers laquelle acheminer le retour d'information.
Comment procéder
Mappage des variables - Le widget de synthèse vocale, comme toute autre entrée, doit être mappé à une variable texte. Lorsque le discours de l'utilisateur a été traité, cette variable est remplie avec la transcription de l'entrée de l'utilisateur. 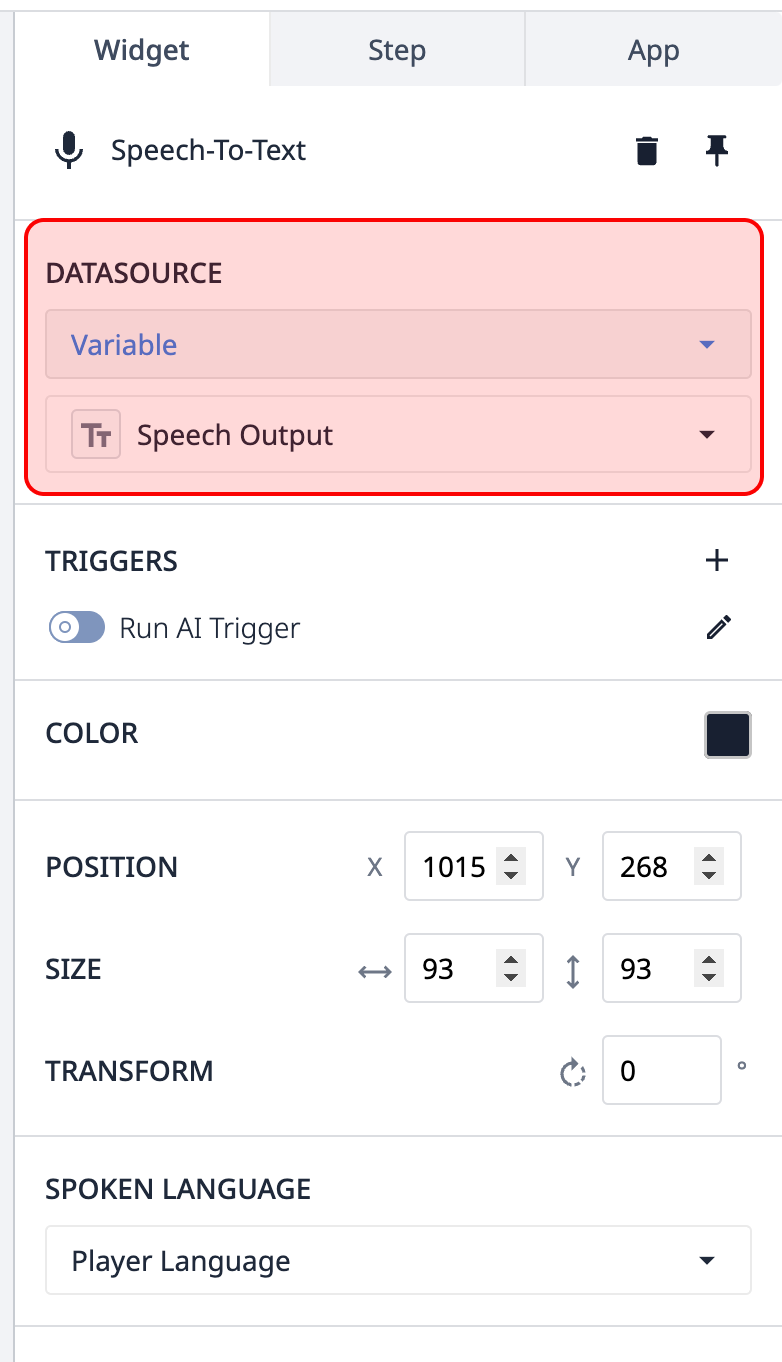
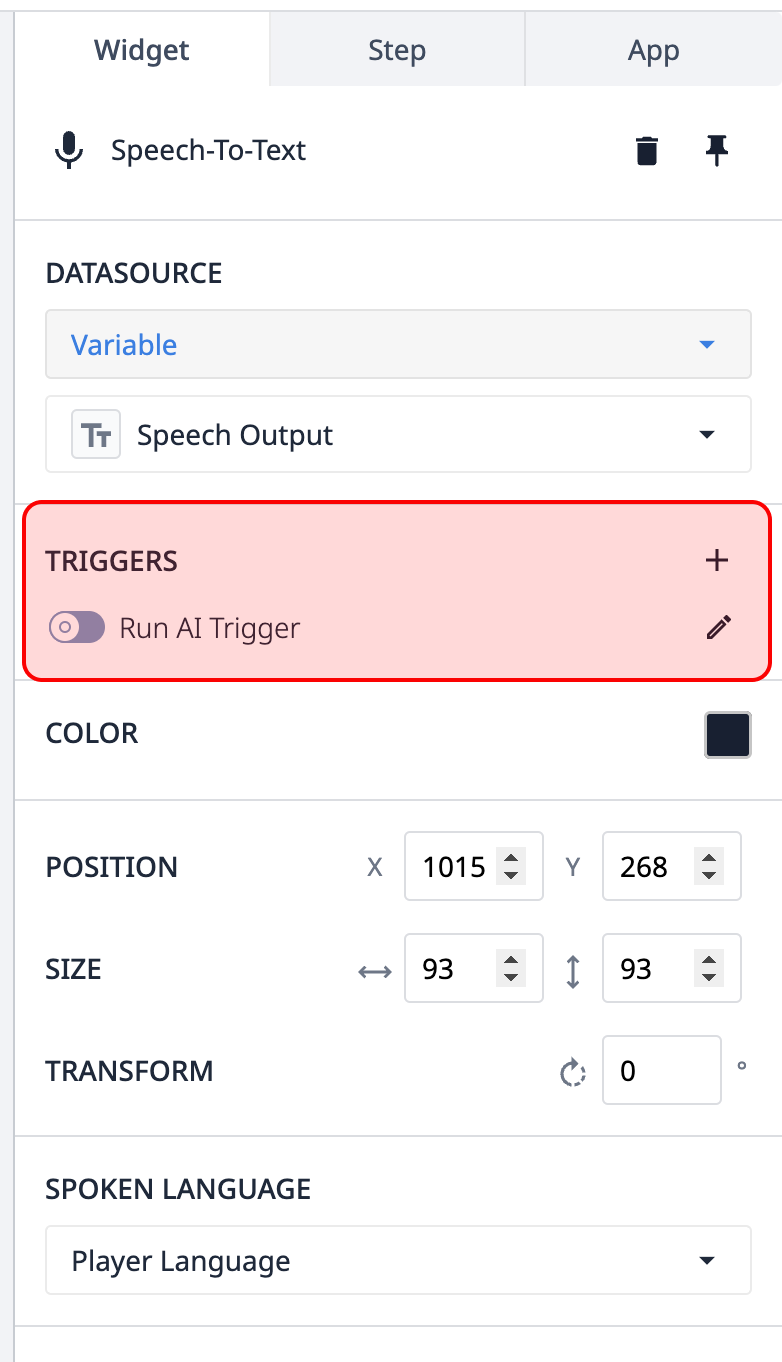
Déclencheurs - L'entrée Speech-to-text peut exécuter automatiquement un déclencheur lorsque l'entrée de l'utilisateur a été transcrite. Ce déclencheur peut être utilisé pour stocker automatiquement ces données, exécuter d'autres actions de copilotage, etc.
Langue parlée: la langue parlée sera par défaut la langue définie dans le lecteur pour l'utilisateur connecté, mais elle peut être remplacée manuellement si ce comportement est préféré. 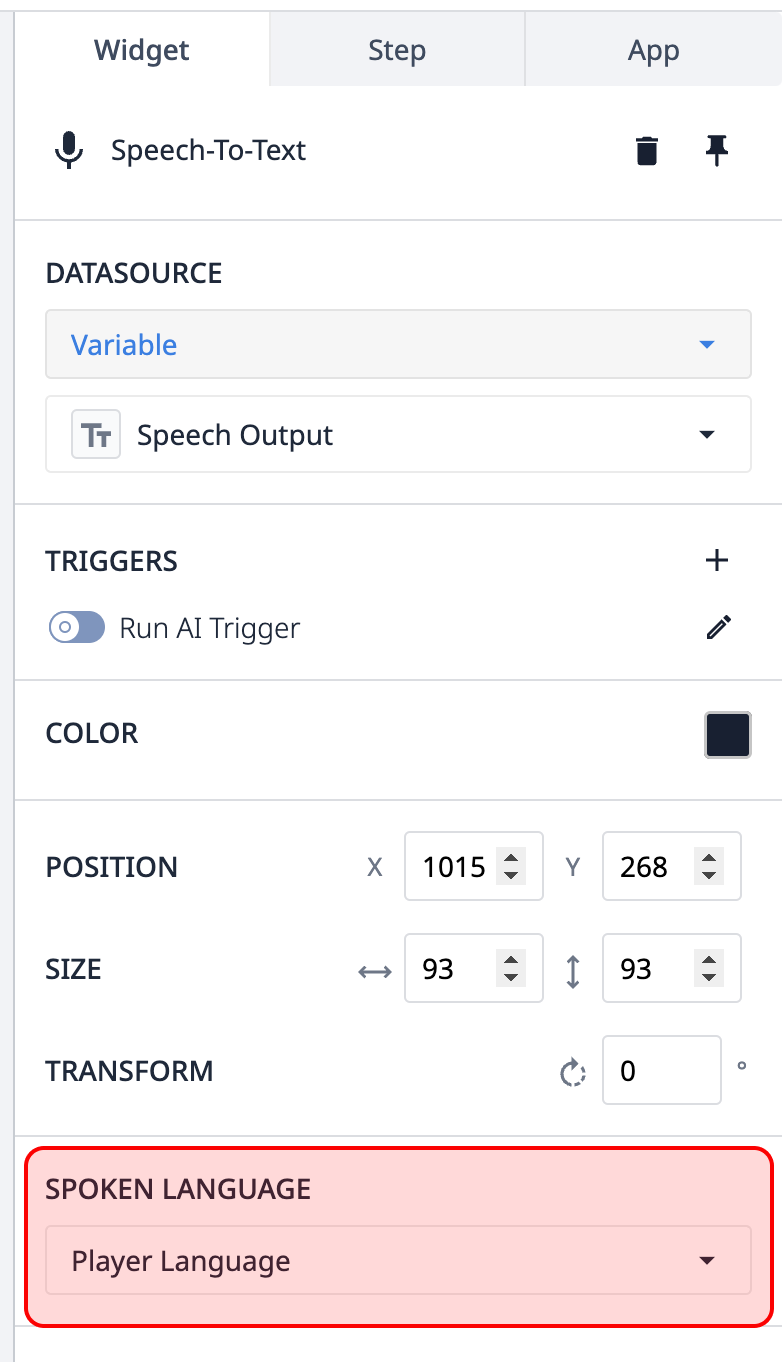 {La langue parlée sera par défaut la langue définie dans le lecteur pour l'utilisateur connecté, mais elle peut être modifiée manuellement si l'on préfère ce comportement.}
{La langue parlée sera par défaut la langue définie dans le lecteur pour l'utilisateur connecté, mais elle peut être modifiée manuellement si l'on préfère ce comportement.}
Limites
Limits are subject to change.
Actuellement, les limites suivantes existent pour les entrées de synthèse vocale. Ces limites sont suivies au niveau de l'instance. Si ces limites sont dépassées, il se peut que l'entrée vocale ne transcrive pas la saisie de l'utilisateur.Durée maximale de l'enregistrement : 30 secondesLimite mensuelle : 5 000 requêtes/moisLimite de débit : 10 requêtes/minute