
Allgemeine SQL-Connector-Funktionen
Dieser Artikel beschreibt, wie man einige häufig verwendete SQL-Funktionen in Tulip Connectors schreibt.
Bevor Sie diese Anleitung lesen, sehen Sie sich unsere andere Anleitung zur Erstellung Ihrer ersten SQL-Connector-Funktion in Tulip an
Im Folgenden finden Sie einige einfache und häufig verwendete SQL-Connector-Funktionen, die Sie in Ihren SQL-Abfragen verwenden können:
SELECT-Anweisung:
Stellen Sie sich ein Szenario vor, in dem Sie Details über einen bestimmten Arbeitsauftrag, der in Ihrer MES/ERP-Datenbank gespeichert ist, einsehen möchten. Die SELECT-Anweisung kann uns bei dieser Aufgabe helfen:
SELECT * FROM tabelle_in_Ihrer_Datenbank
Dies gibt alle Zeilen und Spalten aus Ihrer Tabelle zurück.
Sie können entweder eine einzelne Zeile oder mehrere Zeilen zurückgeben. Wenn Sie nur eine einzige Zeile zurückgeben möchten, fügen Sie Ihrer Abfrage Bedingungen oder Einschränkungen hinzu. In diesem Fall werden in der Regel Tulpeneingaben verwendet. Im folgenden Beispiel ist work_order_number eine Tulip-Funktions-Eingabe.
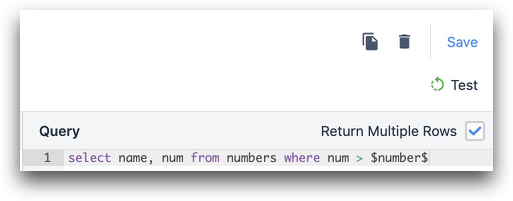
SELECT * FROM tabelle_in_Ihrer_Datenbank WHERE spalte_1 = $arbeit_auftragsnummer$
Wenn Sie mehrere Zeilen zurückgeben möchten, müssen Sie das Kästchen unter "Return Multiple Rows?" ankreuzen.
Daten zurückgeben
Wenn die Namen der Datenbankspalten mit den Namen der Ausgaben übereinstimmen, die Sie in der Konnektorfunktion definiert haben, wird Tulip die Abfrageergebnisse automatisch mit den Ausgaben der Funktion verknüpfen. Beispiel: Tulip-Ausgabe ist output_1 und die Datenbankspalte ist ebenfalls output_1
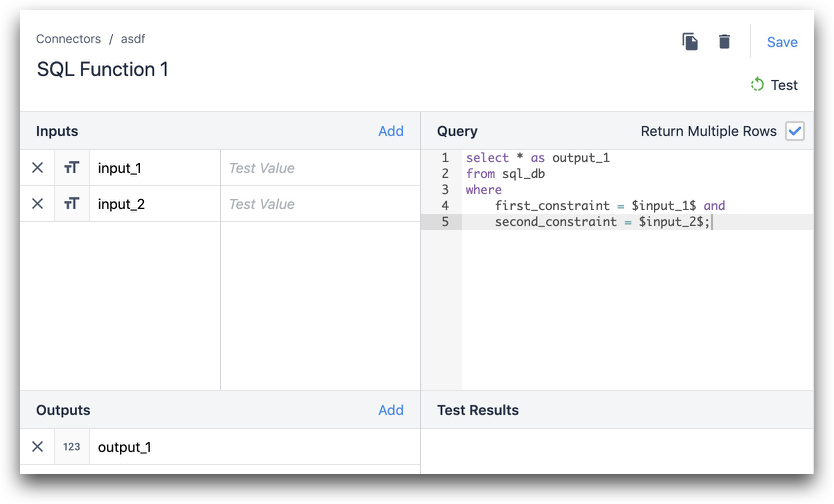
Wenn sich die Spaltennamen in Ihrer Datenbank von denen unterscheiden, die Sie in Tulip verwenden möchten, müssen Sie einen Alias verwenden, um die richtige Verbindung zwischen den beiden herzustellen.
Im folgenden Beispiel ist Spalte_1 aus der Datenbank und Ausgabe_1 ist die Tulip-Ausgabe.
SELECT column_1 as output_1 FROM table_in_Ihrer_Datenbank where first_constraint = $input_1$ und second_constraint = $input_2$;
INSERT-Anweisung:
Stellen Sie sich ein Szenario vor, in dem Sie Daten aus einer Tulip-App in Ihr MES/ERP einfügen möchten. Sie würden eine einfache INSERT-Funktion verwenden, um diese Aufgabe zu erfüllen. Hier sehen Sie ein Beispiel, wie diese Funktion in SQL aussieht:
INSERT INTO table_in_Ihrer_Datenbank (username, user_id, product_id) VALUES ($username$, $user_id$, $product_id$)
Lassen Sie uns nun die einzelnen Teile dieser Funktion aufschlüsseln:
Identifizieren Sie die Tabelle in Ihrer Datenbank
INSERT INTO table_in_Ihrer_Datenbank
Wählen Sie die Spalten in Ihrer Datenbank
(benutzername, benutzer_id, produkt_id)
Definieren Sie die Werte aus Tulip
VALUES ($Benutzername$, $Benutzer_id$, $Produkt_id$)
UPDATE-Anweisung:
Stellen Sie sich ein Szenario vor, in dem Sie Ihr MES/ERP mit Daten aus einer Tulip App aktualisieren möchten, wobei ein Arbeitsauftrag als Schlüssel verwendet wird. Sie würden die UPDATE-Funktion verwenden, wie unten gezeigt:
UPDATE table_in_Ihrer_Datenbank SET column_1 = $input_1$, column_2 = $input_2$ WHERE work_order = $work_order$
Lassen Sie uns nun die einzelnen Teile dieser Funktion aufschlüsseln:
Identifizieren Sie die Tabelle in Ihrer Datenbank
UPDATE Tabelle_in_Ihrer_Datenbank
Definieren Sie die Spalten, die mit Tulip-Daten aktualisiert werden sollen
SET Spalte_1 = $Eingabe_1$, Spalte_2 = $Eingabe_2$
Verwenden Sie den Arbeitsauftrag als Bedingung
WHERE arbeit_auftrag = $arbeit_auftrag$
Weitere Lektüre
Haben Sie gefunden, wonach Sie gesucht haben?
Sie können auch auf community.tulip.co Ihre Frage stellen oder sehen, ob andere mit einer ähnlichen Frage konfrontiert wurden!