Tulip OCR z AWS Textract
- 31 Jan 2024
- 4 Minuty do przeczytania
- Współtwórcy




- Wydrukować
Tulip OCR z AWS Textract
- Zaktualizowano 31 Jan 2024
- 4 Minuty do przeczytania
- Współtwórcy
- Wydrukować
Article Summary
Share feedback
Thanks for sharing your feedback!
:::(Warning) (Uwaga) Dzięki Frontline Coplilot™ tekst można wyodrębnić bezpośrednio z obrazów i dokumentów, co znacznie upraszcza proces rozpoznawania OCR obrazów w Tulip. W przyszłości jest to zalecane podejście :::
Ten artykuł poprowadzi Cię przez konfigurację AWS Textract Connector na Tulip.
AWS Textract to oparta na chmurze usługa dostarczana przez Amazon Web Services (AWS), która wykorzystuje technologię uczenia maszynowego do wyodrębniania tekstu i danych z różnych typów dokumentów. Textract może analizować zeskanowane dokumenty, pliki PDF, obrazy i inne pliki w celu automatycznego wyodrębniania treści tekstowych, tabel, formularzy i par klucz-wartość.
Kluczowe funkcje i możliwości AWS Textract obejmują:
- Optyczne rozpoznawanie znaków (OCR): Textract wykorzystuje OCR do wyodrębniania tekstu z zeskanowanych dokumentów i obrazów, nawet jeśli są one w różnych językach lub mają złożone układy.
- Ekstrakcjapar klucz-wartość: Textract może wyodrębniać pary klucz-wartość z dokumentów, takich jak faktury lub paragony, identyfikując relacje między etykietami i powiązanymi z nimi wartościami.
- Ekstrakcjatabel: Textract może wykrywać i wyodrębniać dane tabelaryczne z dokumentów, zachowując strukturę tabeli, wiersze i kolumny.
- Wyodrębnianie tekstu napodstawie zapytań: Textract umożliwia pobieranie określonych informacji z dokumentów za pomocą zapytań w języku naturalnym.
- Obsługa wielu formatów dokumentów: Textract obsługuje szeroki zakres formatów dokumentów, w tym PDF, JPEG, PNG i TIFF.
- Ekstrakcja formularzy (wkrótce): Textract może automatycznie identyfikować pola formularzy, takie jak pola wyboru, przyciski radiowe i pola tekstowe, i wyodrębniać odpowiednie dane.
Wymagania wstępne
- Działająca stacja robocza Tulip Vision z kamerą do inspekcji wizualnej
- Skontaktuj się z pomocą techniczną Tul ip, aby uzyskać konektor AWS Textract i klucz API (aplikacja Textract wkrótce pojawi się w bibliotece Tulip ).
- Aby wyodrębnić plik PDF, utwórz konektor adresu URL logowania
Konfiguracja konektora Tulip
W instancji Tulip wybierz opcję Konektory z menu Aplikacje.
Wybierz konektor AWS i upewnij się, że jest online lub skonfiguruj go za pomocą następujących szczegółów połączenia:
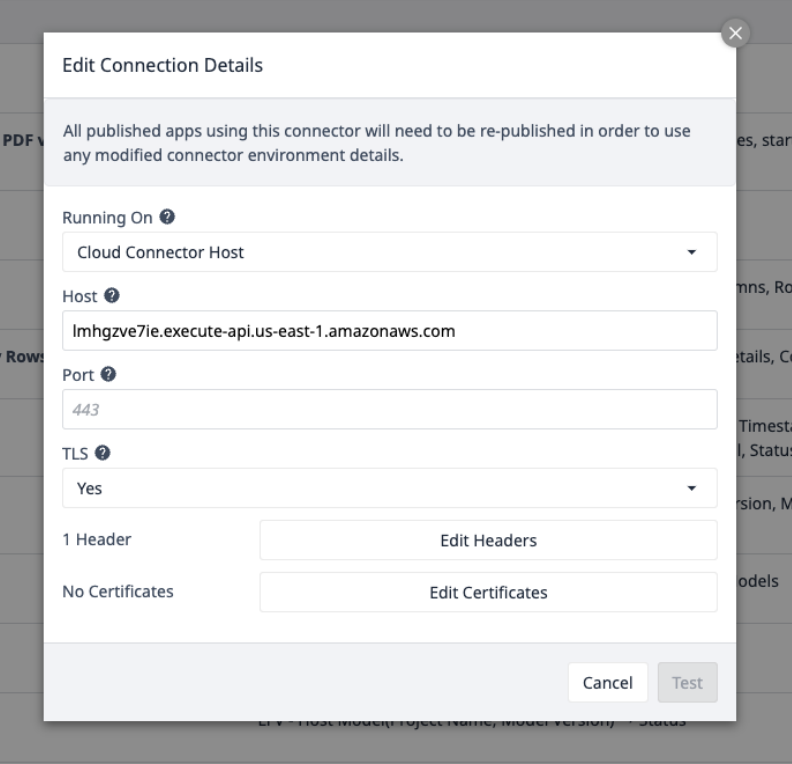
Wybierz Edytuj nagłówki i zaktualizuj klucz X-API dostarczony przez Tulip.
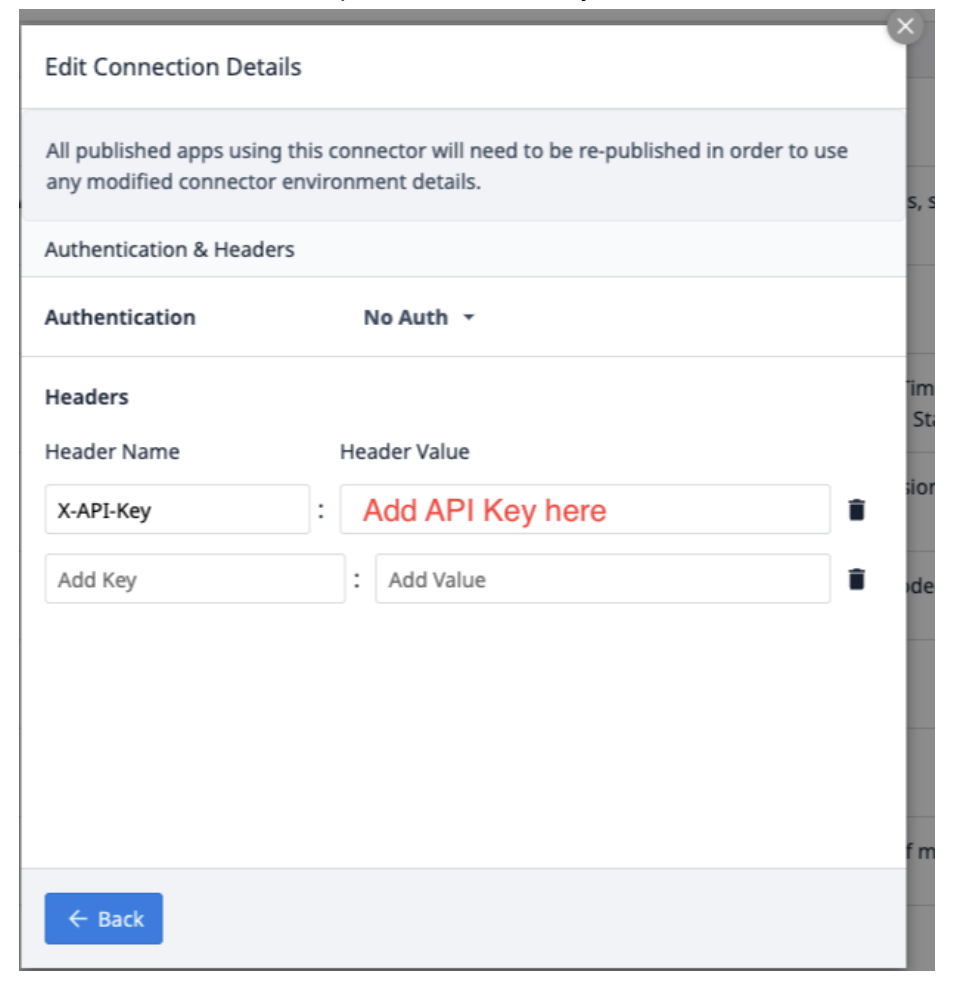
Wybierz Back, a następnie kliknij Test.
Textract w aplikacji Tulip dla par klucz-wartość (wyodrębnianie z pliku PDF)
W tym przykładzie omówimy, jak używać Textract w aplikacji do pobierania par klucz-wartość z pliku PDF. Konieczne będzie utworzenie i skonfigurowanie funkcji konektora w konektorze AWS, a także użycie logiki wyzwalacza do uruchomienia konektora i wyodrębnienia żądanych danych.
Szczegóły funkcji konektora
Utwórz nową funkcję konektora w konektorze AWS. Użyj następujących informacji, aby ustawić Input i Output.
Dane wejściowe File_url (Text) - adres URL pliku PDF przesłanego do Tulip Start_page (Int) - pierwsza strona w pliku PDF do wyodrębnienia End_page (Int) - ostatnia strona w pliku PDF do wyodrębnienia
OutputResults (Objects) - lista obiektów zawierająca pary kluczy i wartości.
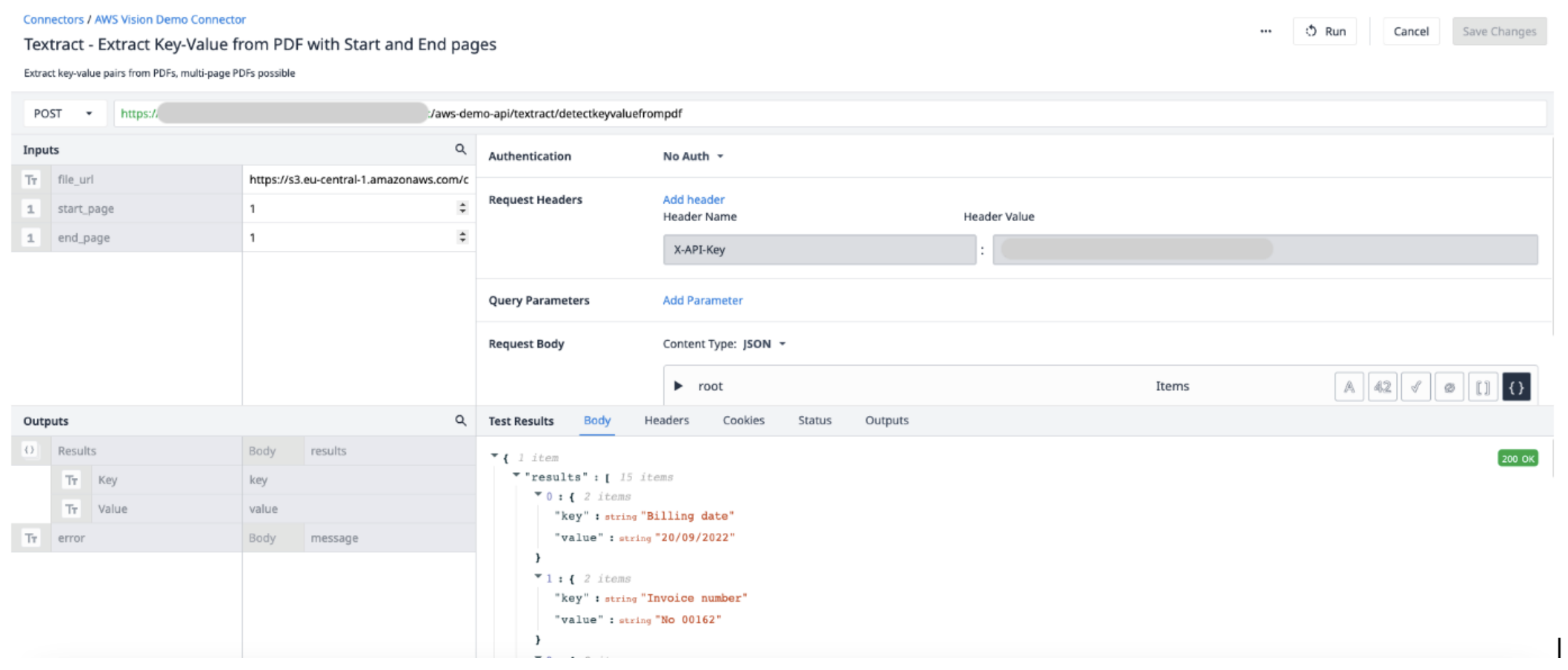
Wyzwalacz aplikacji
Wyzwalacze w aplikacji będą wywoływać funkcję konektora w celu jej uruchomienia.
Utwórz nowy wyzwalacz z następującymi działaniami:
- Uruchom URL Signing Connector z funkcją Sign URL. Plik wejściowy powinien być zmienną tekstową. Użyj wyrażenia FILETOTEXT (variable.File), gdzie "File" to nazwa zmiennej, aby przekonwertować nazwę pliku na ciąg tekstowy. Zapisz dane wyjściowe w zmiennej i nadaj jej nazwę ("SignedURL").
- Uruchom funkcję konektora AWS Textract Key-Value Pairs z danymi wejściowymi sign URL (file_url), a także początkowymi i końcowymi stronami pliku PDF, które mają zostać wyodrębnione. Zapisz dane wyjściowe w nowej tablicy.
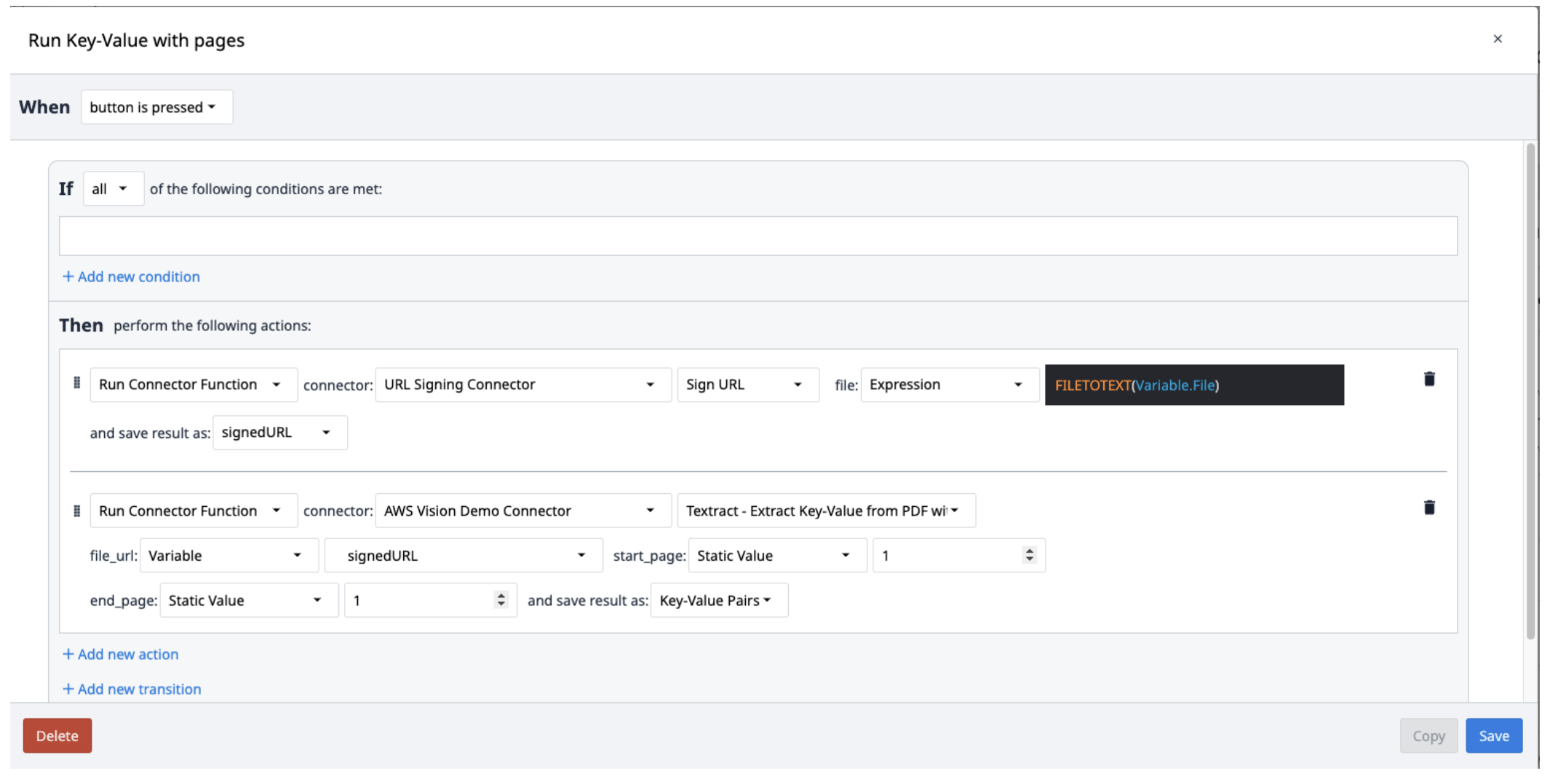
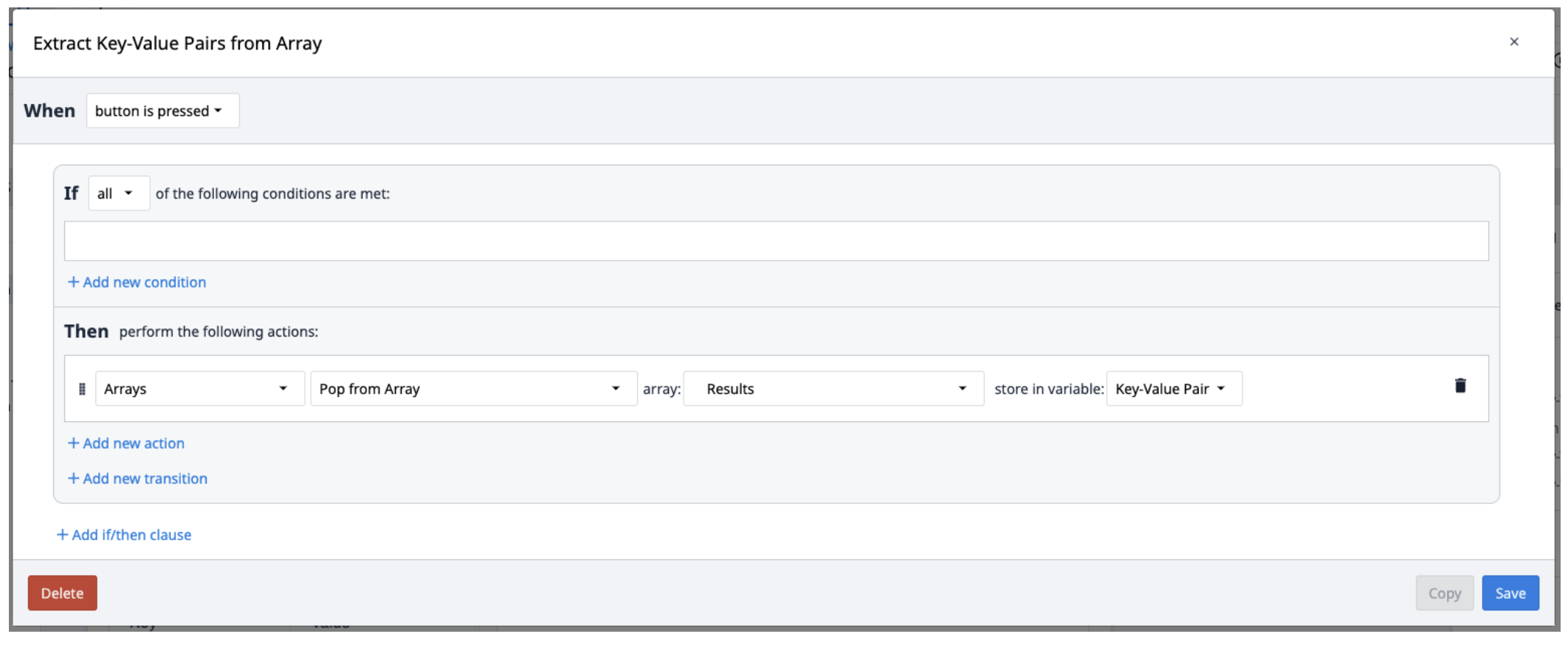
Wyniki Textract są zapisywane w tablicy obiektów zawierających pary klucz-wartość. Aby wyodrębnić je z tablicy, utwórz nowy wyzwalacz, który będzie powtarzał wyskakiwanie par z tablicy w razie potrzeby.
Możesz rozważyć użycie widżetu Looping Customer Wid get, aby pobrać wiele obiektów z tablicy.
Textract w aplikacji Tulip do zapytań (wyodrębnianie z pliku PDF)
W tym przykładzie omówimy, jak używać Textract w aplikacji do odpytywania danych wyodrębnionych z pliku PDF. Konieczne będzie utworzenie i skonfigurowanie nowej funkcji konektora w konektorze AWS, a także użycie logiki wyzwalacza do uruchomienia konektora. Zapytanie o dane pozwala zrozumieć lub zmienić otrzymane dane.
Szczegóły funkcji konektora
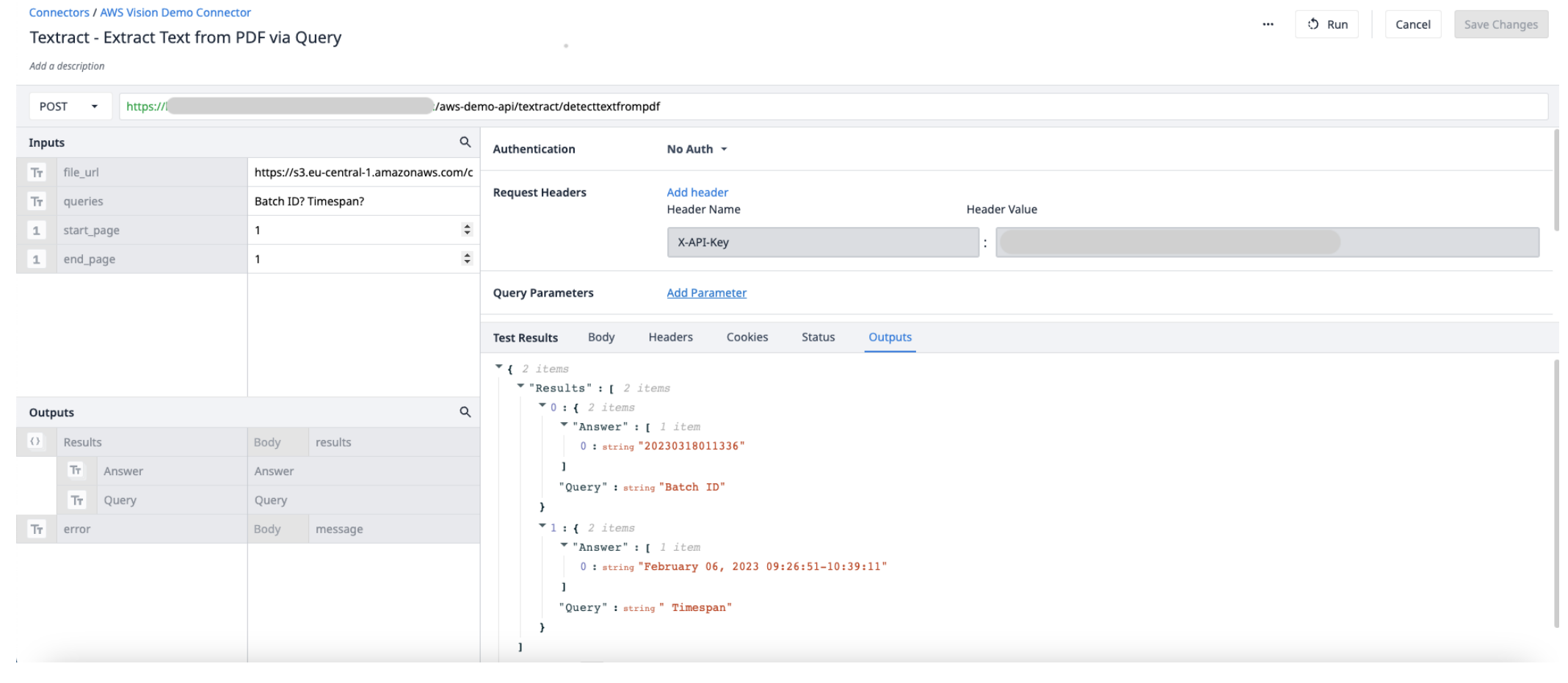
Utwórz nową funkcję konektora w konektorze AWS. Użyj następujących informacji, aby ustawić Input i Output.
Wejścia File_url (tekst) - adres URL pliku PDF przesłanego do Tulip Start_page (int) - pierwsza strona w pliku PDF do wyodrębnienia End_page (int) - ostatnia strona w pliku PDF do wyodrębnienia
OutputResults (objects) - lista obiektów zawierająca odpowiedzi i zapytania.
Wyzwalacz aplikacji
Wyzwalacze w aplikacji będą wywoływać funkcję konektora w celu jej uruchomienia.
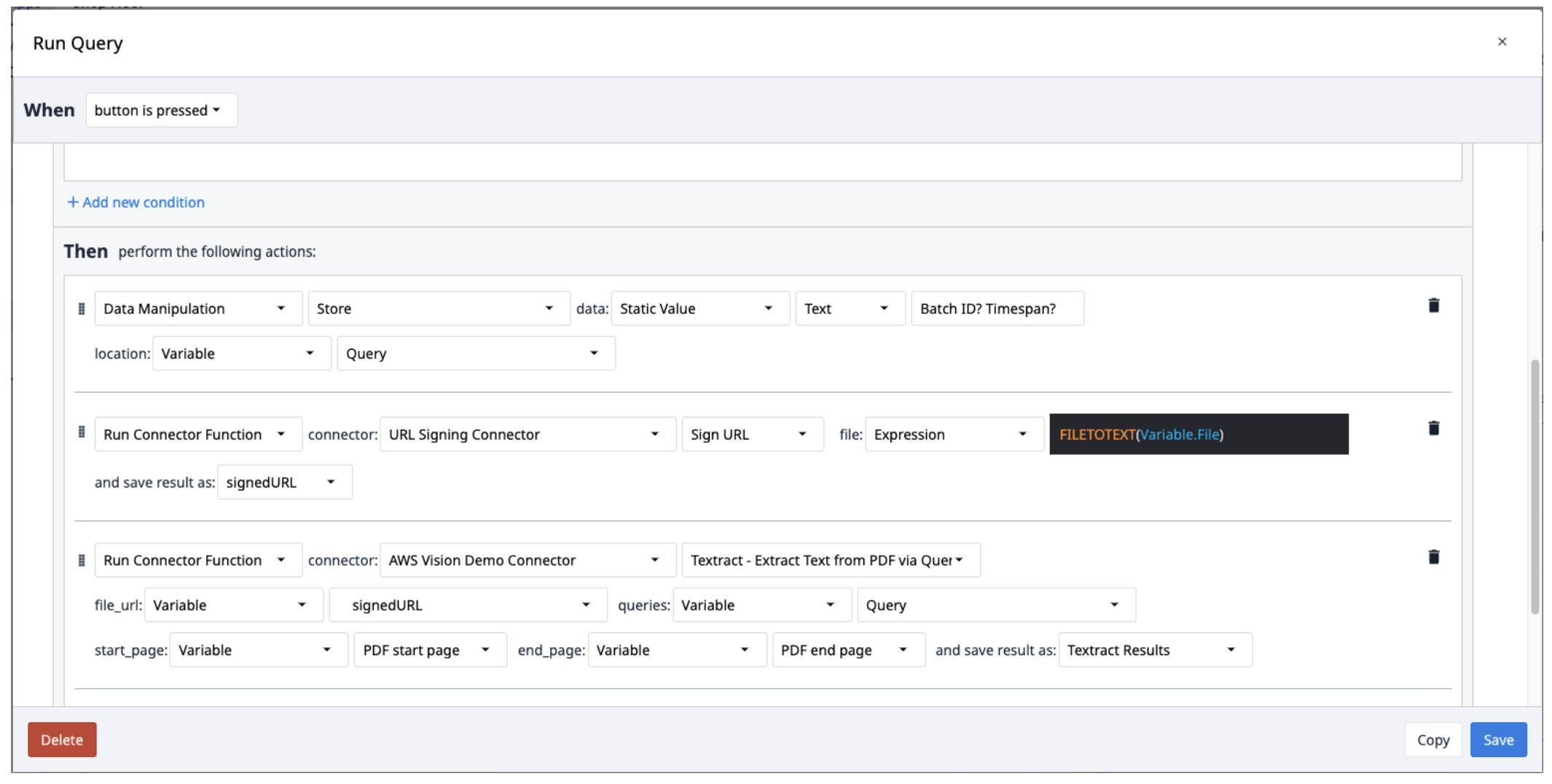
Utwórz nowy wyzwalacz z następującymi działaniami:
- Zapisz zapytania w zmiennej tekstowej oddzielonej znakami zapytania (?).
- Uruchom URL Signing Connector z funkcją Sign URL. Plik wejściowy powinien być zmienną tekstową. Użyj wyrażenia FILETOTEXT (variable.File), gdzie "File" to nazwa zmiennej, aby przekonwertować nazwę pliku na ciąg tekstowy. Zapisz dane wyjściowe w zmiennej i nadaj jej nazwę ("SignedURL").
- Uruchom AWS Textract, wyodrębniając tekst z pliku PDF za pomocą funkcji łącznika zapytań z danymi wejściowymi podpisanego adresu URL (file_url), zmienną zapytania oraz początkową i końcową stroną pliku PDF. Zapisz dane wyjściowe w nowej tablicy.
Czy znalazłeś to, czego szukałeś?
Możesz również udać się na stronę community.tulip.co, aby opublikować swoje pytanie lub sprawdzić, czy inni mieli do czynienia z podobnym pytaniem!
Czy ten artykuł był pomocny?