AWS TextractによるチューリップOCR
- 31 Jan 2024
- 1 読む分
- 寄稿者




- 印刷する
AWS TextractによるチューリップOCR
- 更新日 31 Jan 2024
- 1 読む分
- 寄稿者
- 印刷する
Article Summary
Share feedback
Thanks for sharing your feedback!
:::(Warning) (注)Frontline Coplilot™を使用すると、画像や文書から直接テキストを抽出できるため、Tulipで画像に対してOCRを行うプロセスが大幅に簡素化されます。今後はこの方法を推奨します:
この記事では、Tulip上でAWS Textract Connectorをセットアップする方法を説明します。
AWS TextractはAmazon Web Services (AWS)が提供するクラウドベースのサービスで、機械学習技術を使って様々な種類のドキュメントからテキストやデータを抽出します。Textractは、スキャンした文書、PDF、画像、その他のファイルを分析し、テキストコンテンツ、テーブル、フォーム、キーと値のペアを自動的に抽出することができます。
AWS Textractの主な特徴と機能は以下の通りです:
- 光学式文字認識(OCR):TextractはOCRを使用して、異なる言語や複雑なレイアウトのスキャン文書や画像からテキストを抽出します。
- キーと値のペアの抽出:Textractは、ラベルと関連する値の関係を識別することにより、請求書や領収書などの文書からキーと値のペアを抽出することができます。
- 表抽出:Textractは、表構造、行、列を保持したまま、文書から表データを検出して抽出することができます。
- クエリベースのテキスト抽出:Textractは、自然言語クエリを使用して文書から特定の情報を取得することができます。
- 複数の文書形式をサポート:Textractは、PDF、JPEG、PNG、TIFFなど幅広い文書形式に対応しています。
- フォーム抽出(近日公開予定):Textractは、チェックボックス、ラジオボタン、テキストフィールドなどのフォームフィールドを自動的に識別し、対応するデータを抽出することができます。
前提条件
- Tulip Visionワークステーションと目視検査用カメラ
- Tulipサポートに連絡して、AWS Textract ConnectorとAPI Keyを入手してください。
- PDFファイル抽出のためにサインインURLコネクタを作成する
Tulipコネクタのセットアップ
Tulipインスタンスで、AppsメニューからConnectorsを選択します。
AWSコネクタを選択し、それがオンラインであることを確認するか、次の接続の詳細で1つを設定します:
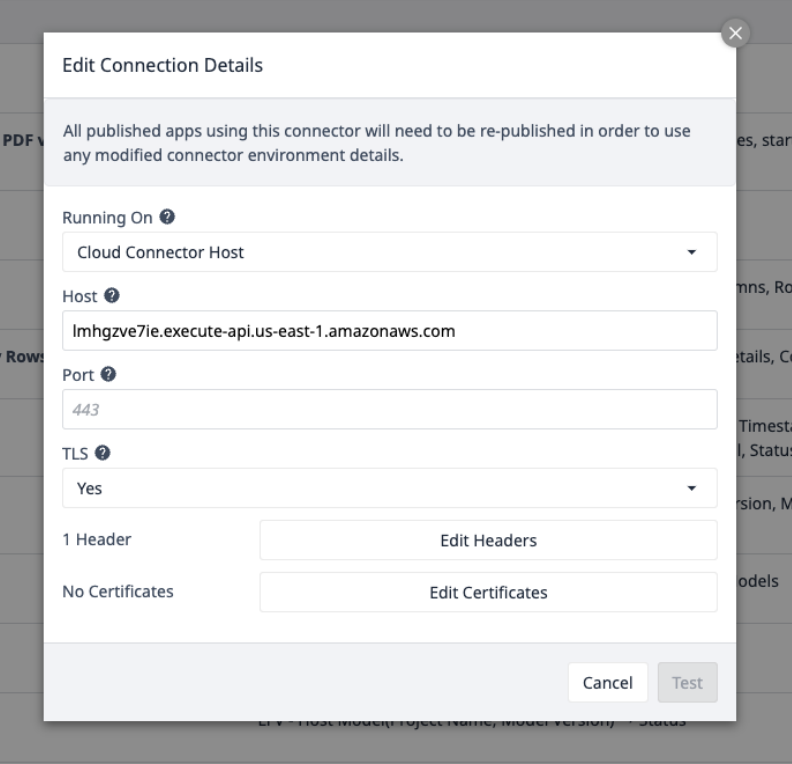
Edit Headersを選択し、Tulipが提供するX-API-Keyを更新します。
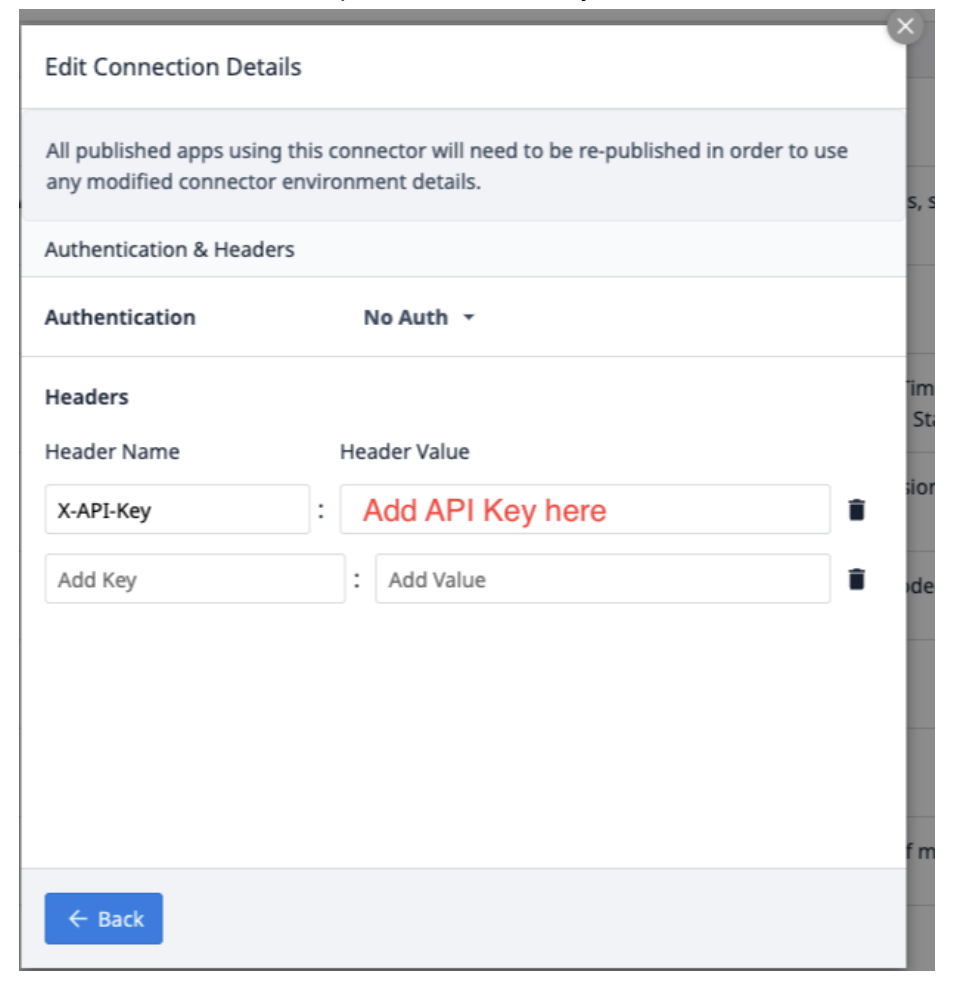
Backを選択し、Testをクリックします。
キーと値のペアのためのTulipアプリケーションでのTextract(PDFからの抽出)
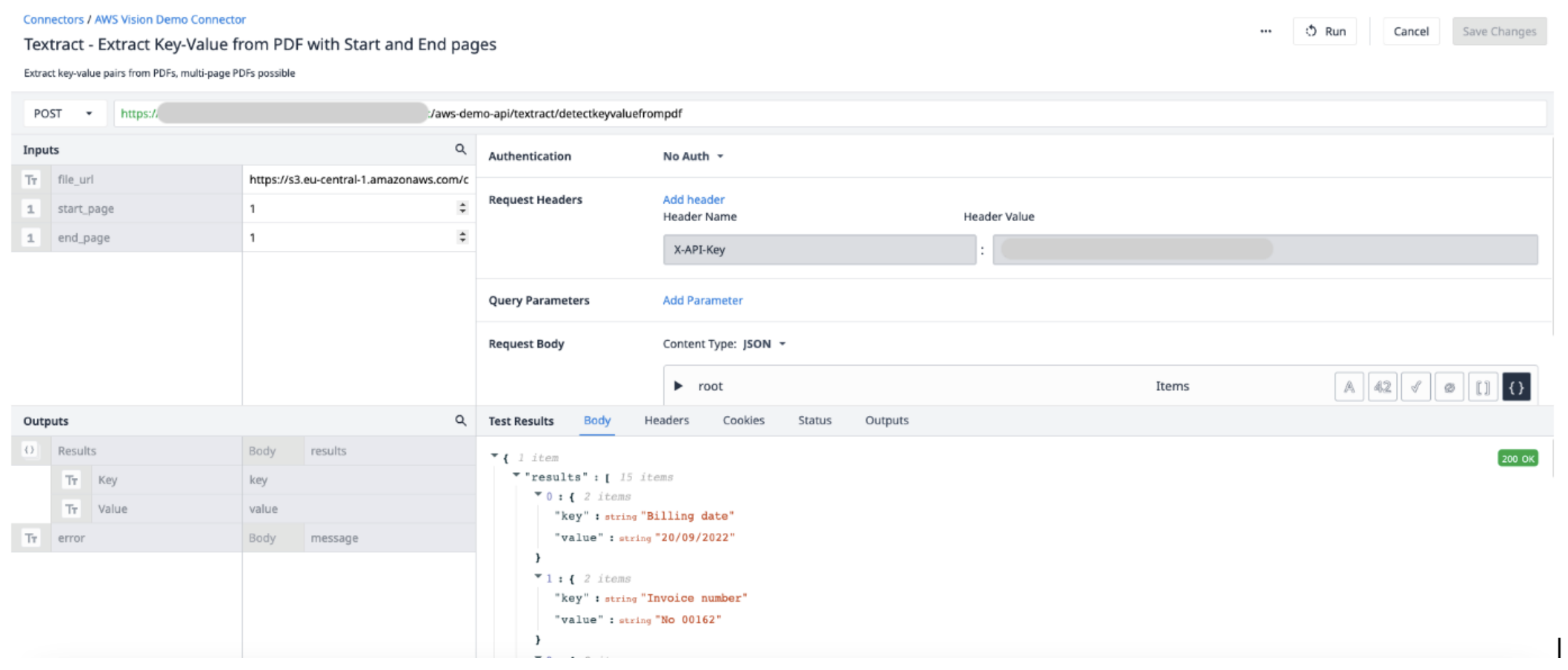
この例では、アプリでTextractを使ってPDFからキーと値のペアを取得する方法を説明します。AWSコネクタでコネクタ関数を作成・設定し、トリガーロジックを使用してコネクタを実行し、必要なデータを抽出する必要があります。
コネクタ関数の詳細
AWS Connector で新しい Connector Function を作成します。以下の情報を使用して、Inputs と Outputsを設定します。
入力File_url (Text) - Tulip にアップロードされた PDF ファイルの URL Start_page (Int) - 抽出する PDF ファイルの最初のページ End_page (Int) - 抽出する PDF ファイルの最後のページ
出力結果(オブジェクト) - キーと値のペアのオブジェクトリスト。
アプリケーショントリガー
アプリでは、トリガーがコネクタ関数を呼び出して実行します。
以下のアクションを持つ新しいトリガを作成します:
- Sign URL 関数で URL Signing コネクタを実行します。ファイル入力はテキスト変数でなければなりません。FILETOTEXT (variable.File) 式を使用して、ファイル名をテキスト文字列に変換します。出力を変数に保存し、名前を付ける("SignedURL")。
- AWS Textract Key-Value Pairs コネクタ関数を、署名 URL 入力(file_url)と、抽出する PDF の開始ページと終了ページすべてで実行します。出力を新しい配列に保存します。
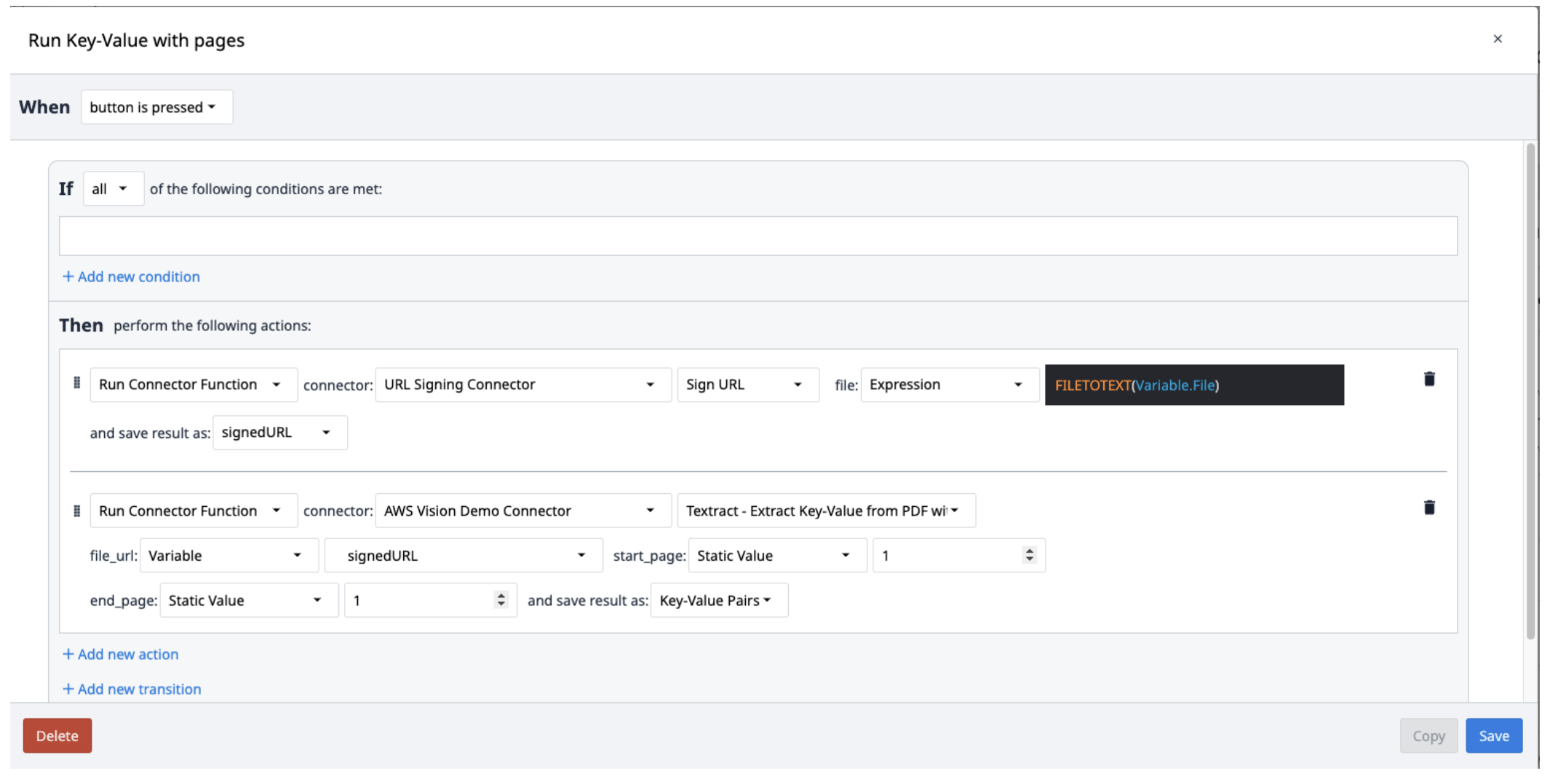
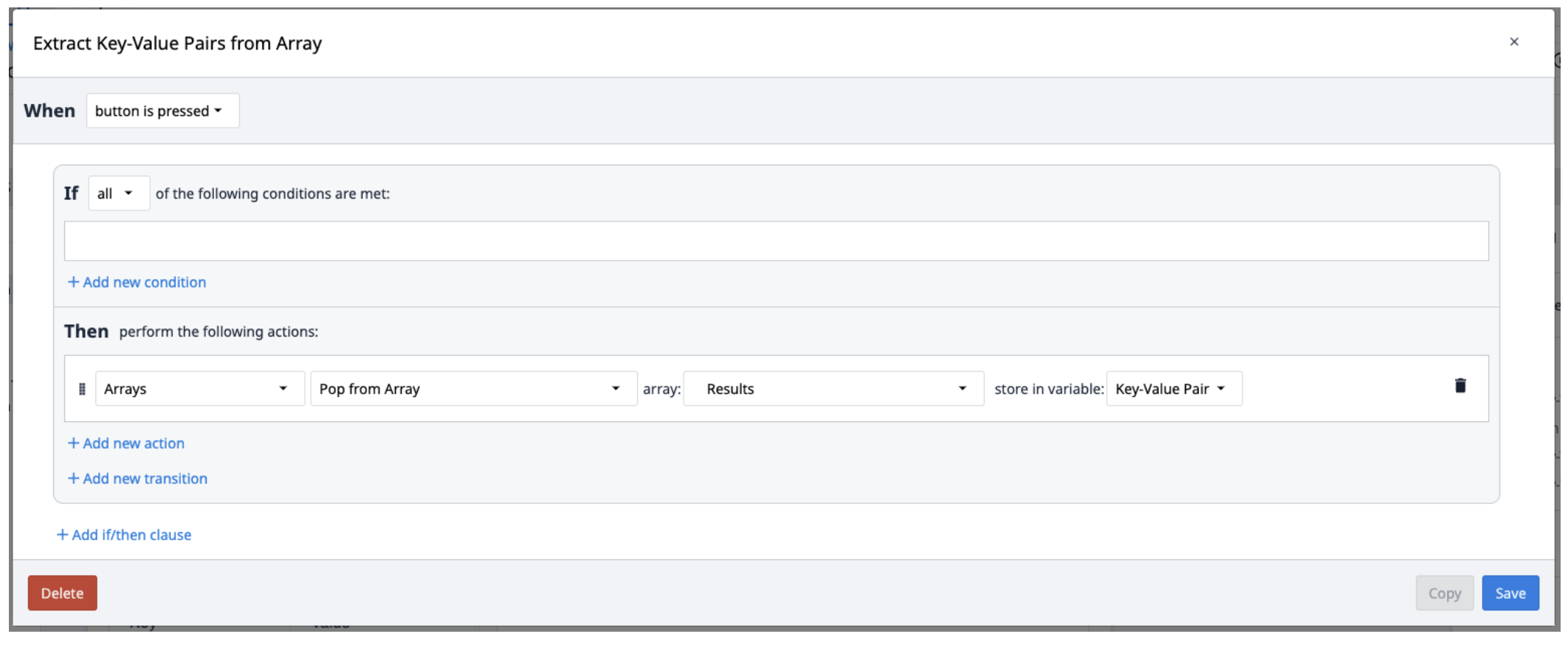
Textractの結果は、Key-Valueペアを含むオブジェクトの配列に保存されます。配列から抽出するには、必要に応じて配列からペアを繰り返しポップする新しいトリガーを作成します。
配列から複数のオブジェクトをポップするには、Looping Customer Widgetの使用を検討するとよいでしょう。
クエリのためのTulipアプリケーションでのTextract (PDFからの抽出)
この例では、 PDF から抽出したデータをクエリするアプリで Textract を使う方法を説明します。AWSコネクタで新しいコネクタ関数を作成・設定し、トリガーロジックを使ってコネクタを実行する必要があります。データをクエリすることで、受け取ったデータを理解したり変更したりすることができます。
コネクタ関数の詳細
AWS Connectorで新しいConnector Functionを作成します。以下の情報を使用して、Inputs と Outputsを設定します。
入力File_url (Text) - Tulip にアップロードされた PDF ファイルの URL Start_page (Int) - 抽出する PDF ファイルの最初のページ End_page (Int) - 抽出する PDF ファイルの最後のページ
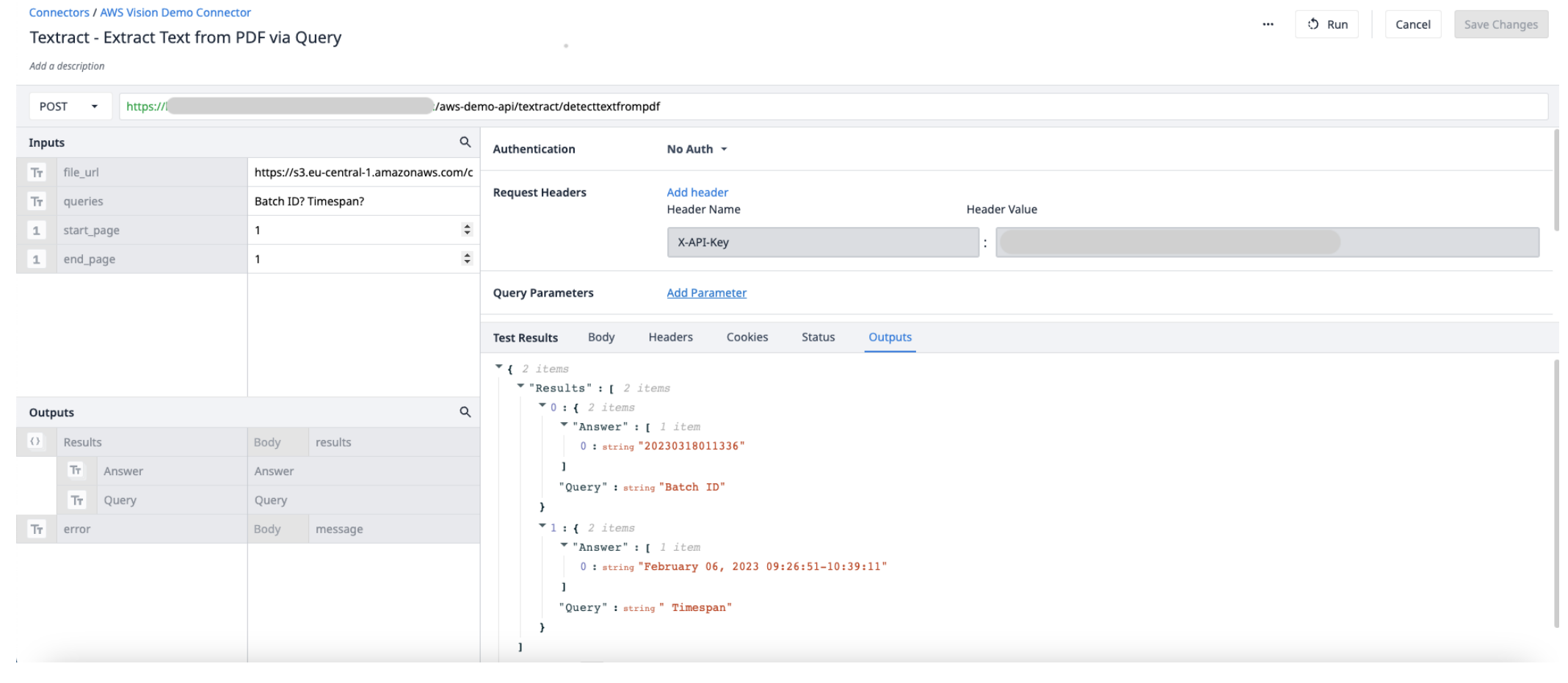
出力結果(オブジェクト) - 回答とクエリのオブジェクトリスト
アプリケーショントリガー
アプリでは、トリガーがコネクタ関数を呼び出して実行します。
以下のアクションを持つ新しいトリガーを作成します:
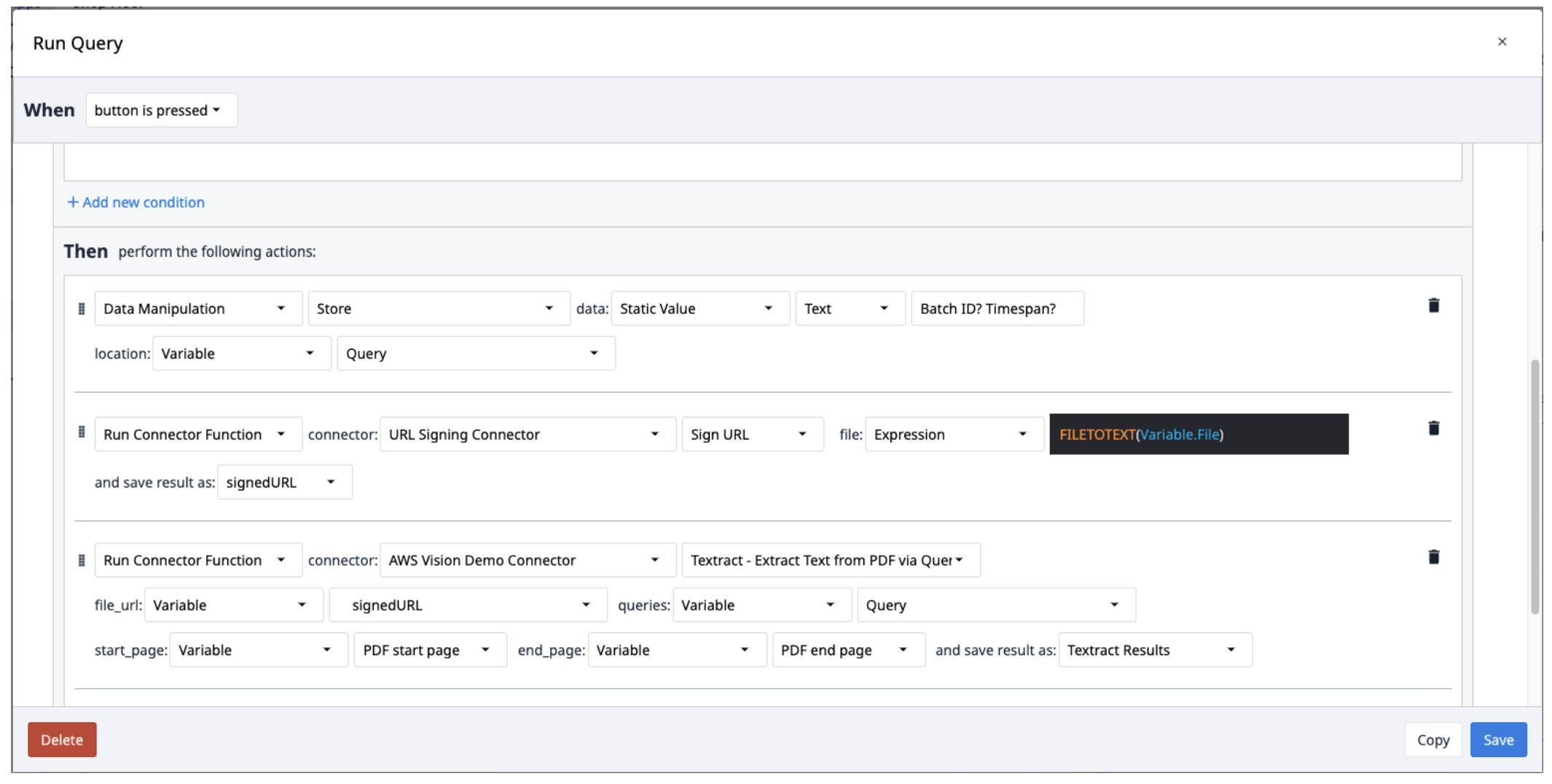
- クエリをクエスチョンマーク(?)で区切られたテキスト変数に保存する。
- Sign URL 関数で URL Signing コネクタを実行します。ファイル入力はテキスト変数でなければなりません。FILETOTEXT (variable.File) 式を使用する。"File" は変数の名前で、ファイル名をテキスト文字列に変換する。出力を変数に保存し、名前を付ける("SignedURL")。
- 署名URL入力(file_url)、クエリ変数、PDFの開始ページと終了ページで、クエリコネクタ関数を介してPDFからテキストを抽出することにより、AWS Textractを実行します。出力を新しい配列に保存します。
お探しのものは見つかりましたか?
community.tulip.coに質問を投稿したり、他の人が同じような質問に直面していないか確認することもできます!
この記事は役に立ちましたか?