Tulip OCR con AWS Textract
- 31 Jan 2024
- 4 Minuti da leggere
- Contributori




- Stampa
Tulip OCR con AWS Textract
- Aggiornato il 31 Jan 2024
- 4 Minuti da leggere
- Contributori
- Stampa
Article Summary
Share feedback
Thanks for sharing your feedback!
:::(Warning) (Nota) Con Frontline Coplilot™ è possibile estrarre il testo direttamente da immagini e documenti, semplificando notevolmente il processo di OCR delle immagini in Tulip. In futuro questo è l'approccio consigliato:
Questo articolo vi guiderà nella configurazione di AWS Textract Connector su Tulip.
AWS Textract è un servizio basato sul cloud fornito da Amazon Web Services (AWS) che utilizza la tecnologia di apprendimento automatico per estrarre testo e dati da vari tipi di documenti. Textract è in grado di analizzare documenti scansionati, PDF, immagini e altri file per estrarre automaticamente contenuti testuali, tabelle, moduli e coppie chiave-valore.
Le caratteristiche e le funzionalità principali di AWS Textract includono:
- Riconoscimento ottico dei caratteri (OCR): Textract utilizza l'OCR per estrarre il testo da documenti e immagini scannerizzati, anche se in lingue diverse o con layout complessi.
- Estrazione di coppie chiave-valore: Textract può estrarre coppie chiave-valore da documenti, come fatture o ricevute, identificando la relazione tra le etichette e i valori ad esse associati.
- Estrazione di tabelle: Textract è in grado di rilevare ed estrarre dati tabellari dai documenti, preservando la struttura della tabella, le righe e le colonne.
- Estrazione di testo basata su query: Textract consente di recuperare informazioni specifiche dai documenti utilizzando query in linguaggio naturale.
- Supporto per più formati di documenti: Textract supporta un'ampia gamma di formati di documenti, tra cui PDF, JPEG, PNG e TIFF.
- Estrazione di moduli (in arrivo): Textract è in grado di identificare automaticamente i campi dei moduli, come caselle di controllo, pulsanti di opzione e campi di testo, e di estrarre i dati corrispondenti.
Prerequisiti
- Una workstation Tulip Vision funzionante con una fotocamera per l'ispezione visiva.
- Contattare l'assistenza Tulip per ottenere il connettore AWS Textract e la chiave API (l'app Textract arriverà presto nella libreria Tulip ).
- Per l'estrazione di file PDF, creare un connettore URL di accesso.
Impostazione del connettore Tulip
Nell'istanza di Tulip, selezionare Connettori dal menu Applicazioni.
Selezionare il connettore AWS e assicurarsi che sia online, oppure impostarne uno con i seguenti dettagli di connessione:
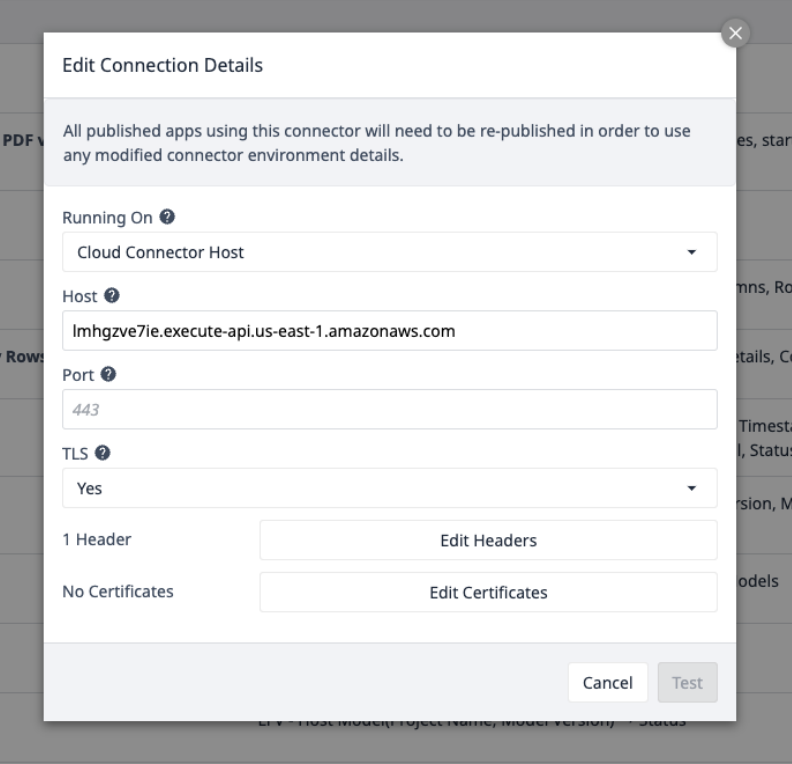
Selezionare Modifica intestazioni e aggiornare la chiave X-API, fornita da Tulip.
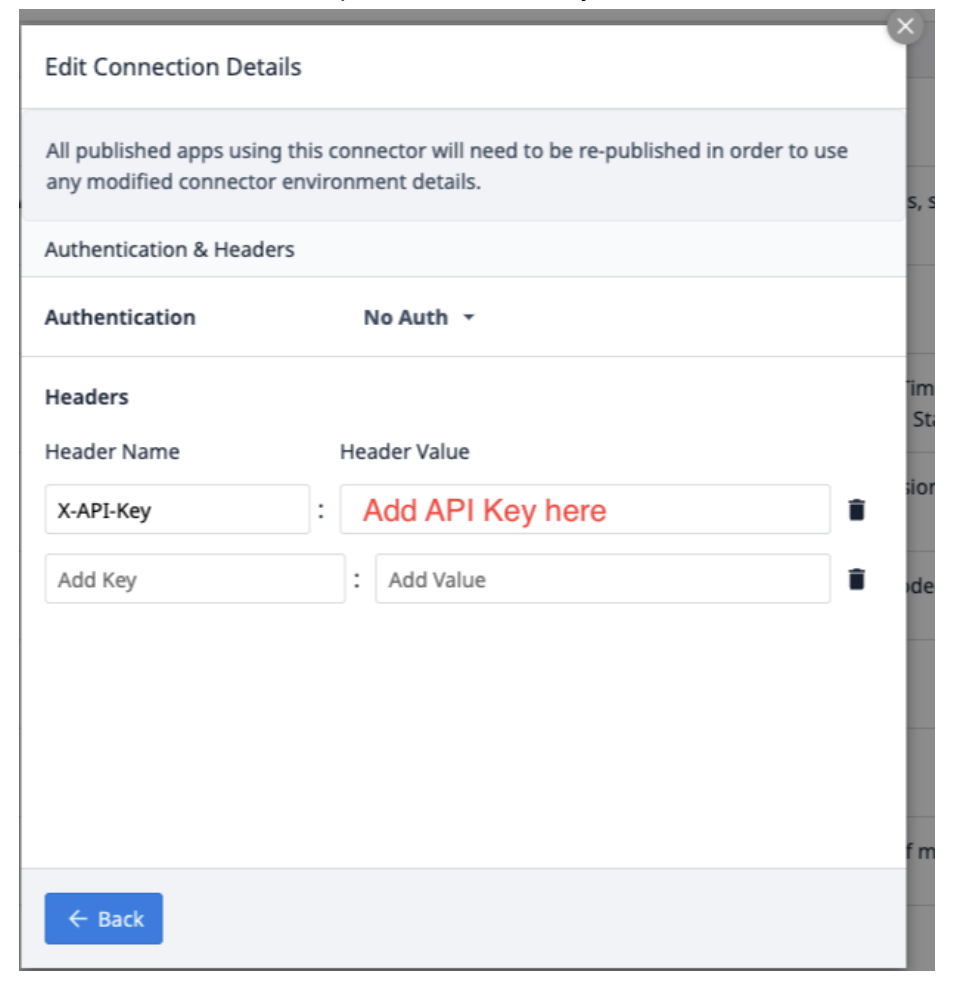
Selezionare Indietro e poi fare clic su Test.
Textract in un'applicazione Tulip per coppie chiave-valore (estrazione da un PDF)
In questo esempio, spiegheremo come utilizzare Textract in un'applicazione per ottenere coppie chiave-valore da un PDF. È necessario creare e configurare una funzione connettore nel connettore AWS e utilizzare la logica di attivazione per eseguire il connettore ed estrarre i dati desiderati.
Dettagli della funzione connettore
Creare una nuova funzione connettore nel connettore AWS. Utilizzare le seguenti informazioni per impostare gli {{glossario.Input}} e gli {{glossario.Output}}.
Ingressi File_url (Testo) - URL del file PDF caricato su Tulip Inizio_pagina (Int) - la prima pagina del file PDF da cui estrarre Fine_pagina (Int) - l'ultima pagina del file PDF da cui estrarre
OutputResults (Objects) - un elenco di oggetti composto da coppie di chiavi e valori.
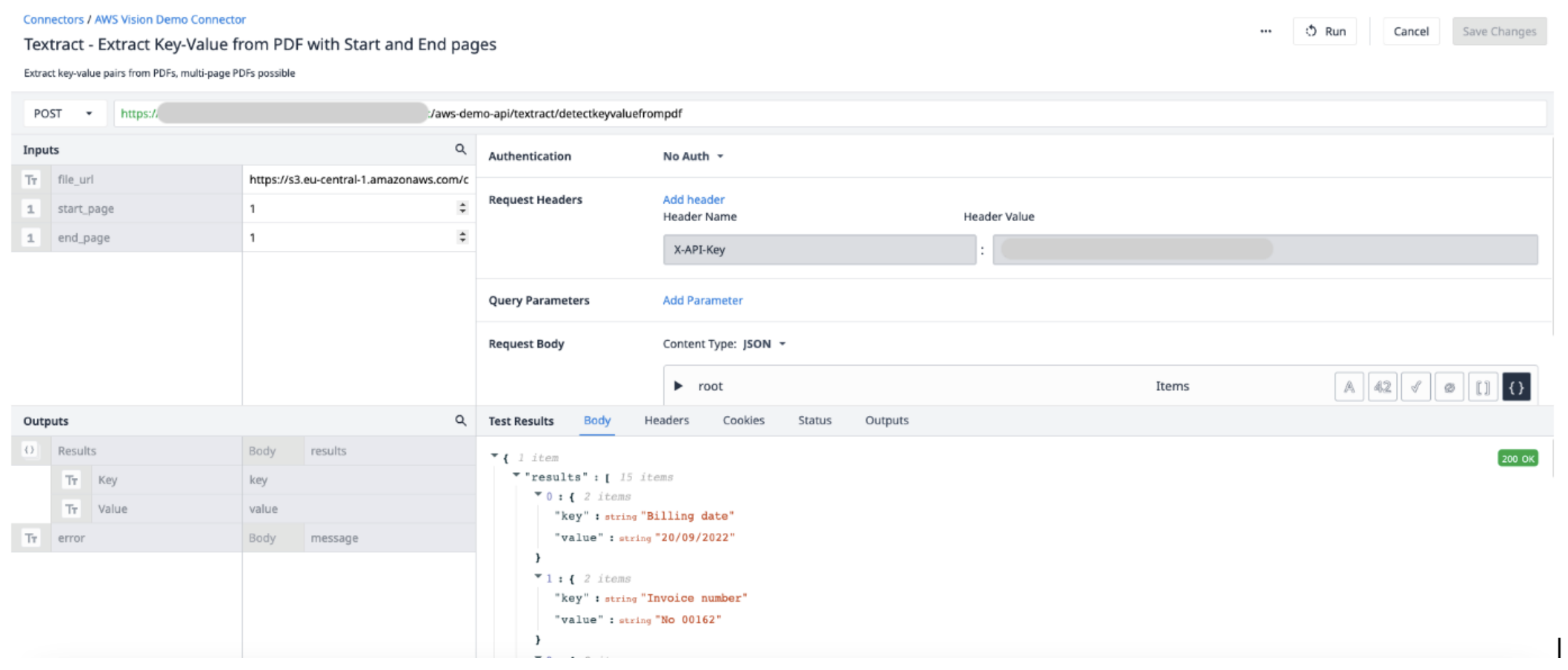
Trigger dell'applicazione
Nella vostra applicazione, i Trigger chiameranno la funzione del connettore per essere eseguiti.
Creare un nuovo trigger con le seguenti azioni:
- Eseguire il connettore di firma degli URL con la funzione Sign URL. Il file di input deve essere una variabile di testo. Utilizzare l'espressione FILETOTEXT (variable.File), dove "File" è il nome della variabile, per convertire il nome del file in una stringa di testo. Salvare l'output in una variabile e nominarla ("SignedURL").
- Eseguire la funzione del connettore AWS Textract Key-Value Pairs con l'URL di firma in ingresso (file_url) e le pagine iniziali e finali del PDF da estrarre. Salvare l'output in un nuovo array.
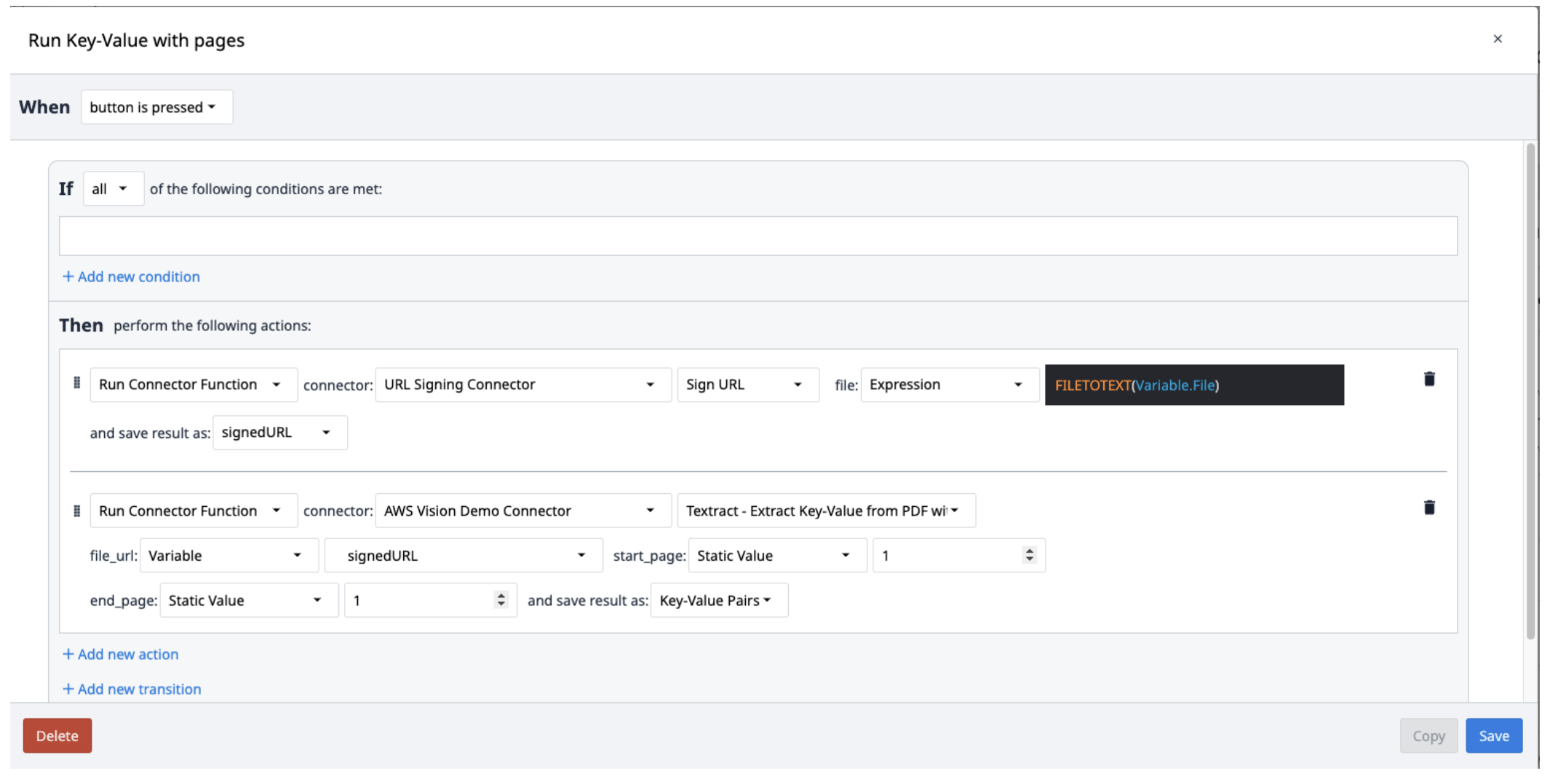
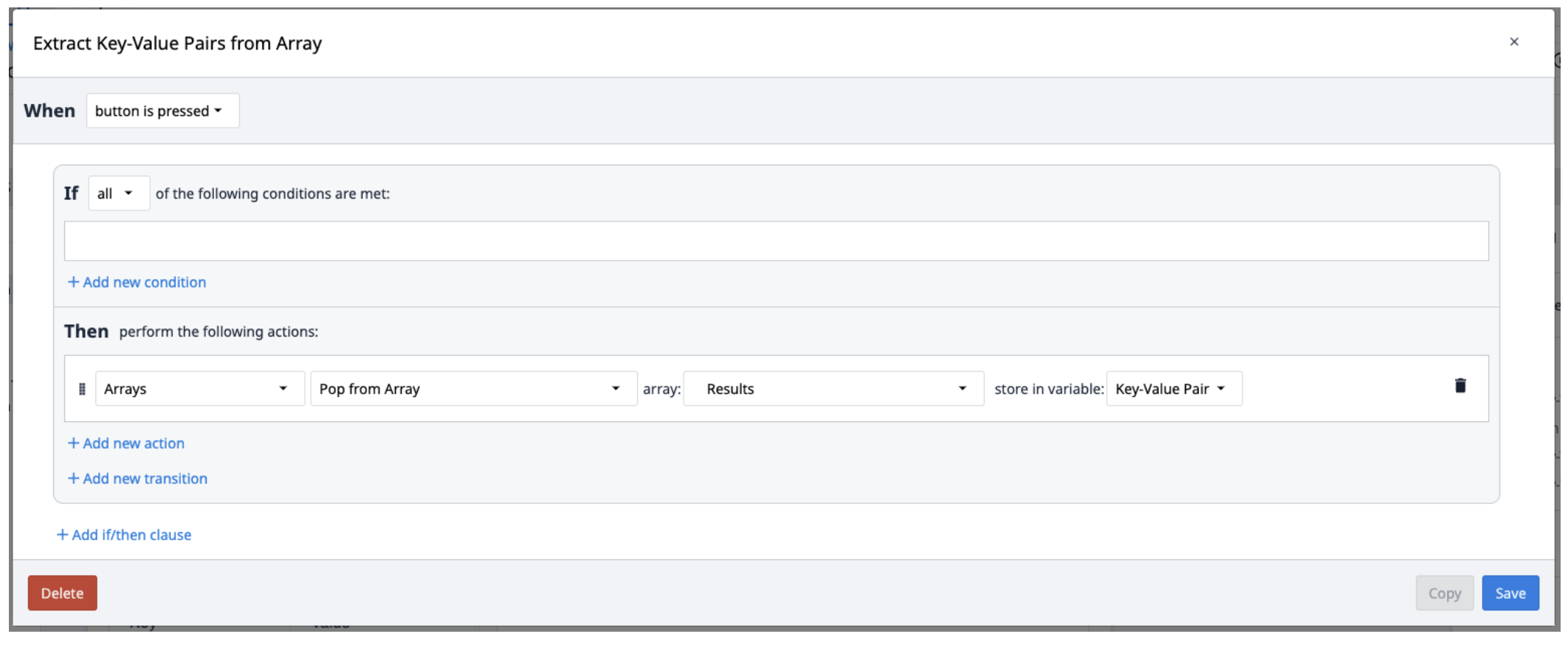
I risultati di Textract vengono salvati in un array di oggetti contenenti coppie chiave-valore. Per estrarli dall'array, creare un nuovo trigger che ripeta l'estrazione delle coppie dall'array come necessario.
Per estrarre più oggetti dall'array, si può utilizzare il widget Looping Customer.
Textract in un'applicazione Tulip per l'interrogazione (estrazione da un PDF)
In questo esempio, spiegheremo come utilizzare Textract in un'applicazione per interrogare i dati estratti da un PDF. È necessario creare e configurare una nuova funzione connettore nel connettore AWS e utilizzare la logica di trigger per eseguire il connettore. L'interrogazione dei dati consente di comprendere o modificare i dati ricevuti.
Dettagli della funzione connettore
Creare una nuova funzione connettore nel connettore AWS. Utilizzare le seguenti informazioni per impostare gli {{glossario.Input}} e gli {{glossario.Output}}.
Ingressi File_url (Testo) - URL del file PDF caricato su Tulip Inizio_pagina (Int) - la prima pagina del file PDF da cui estrarre Fine_pagina (Int) - l'ultima pagina del file PDF da cui estrarre
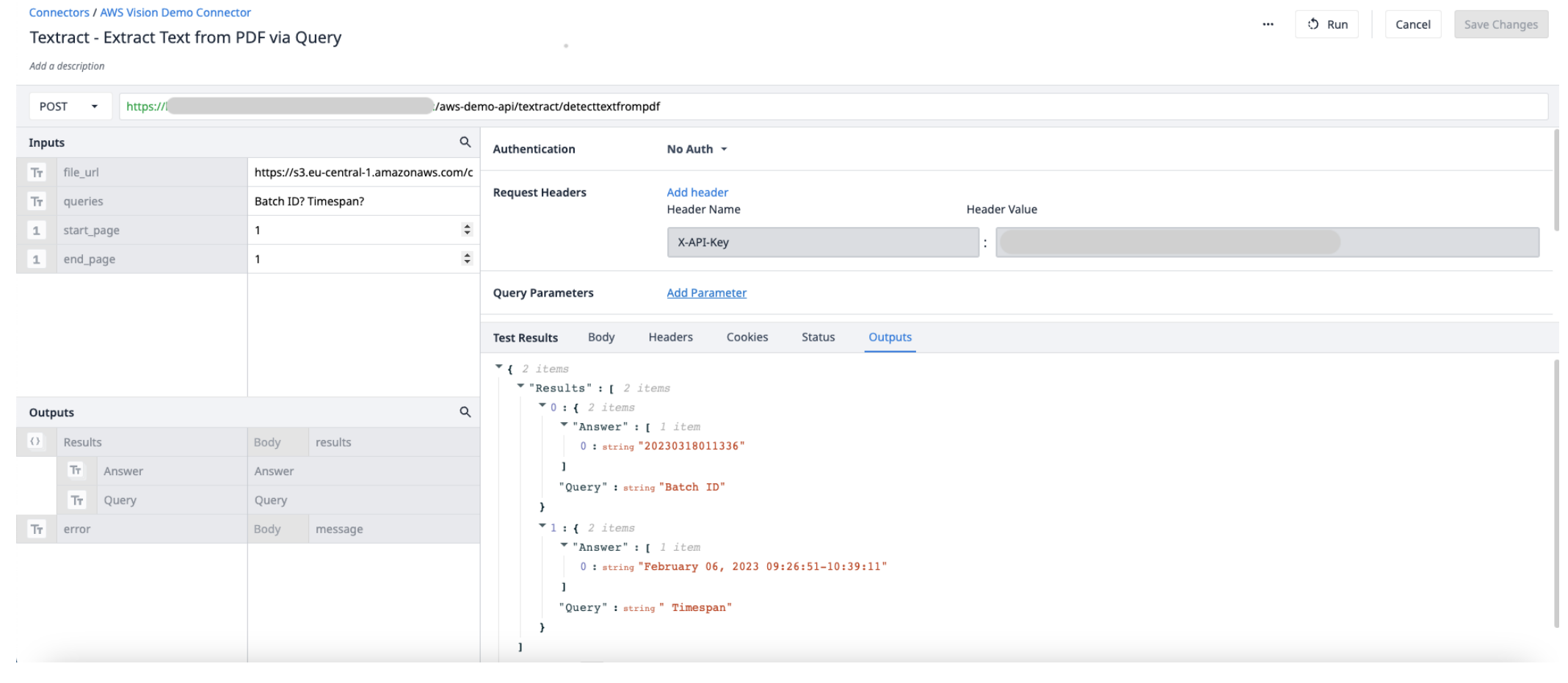
Risultatidi output(oggetti) - un elenco di oggetti di risposte e query.
Trigger dell'applicazione
Nella vostra applicazione, i Trigger chiameranno la funzione del connettore per essere eseguiti.
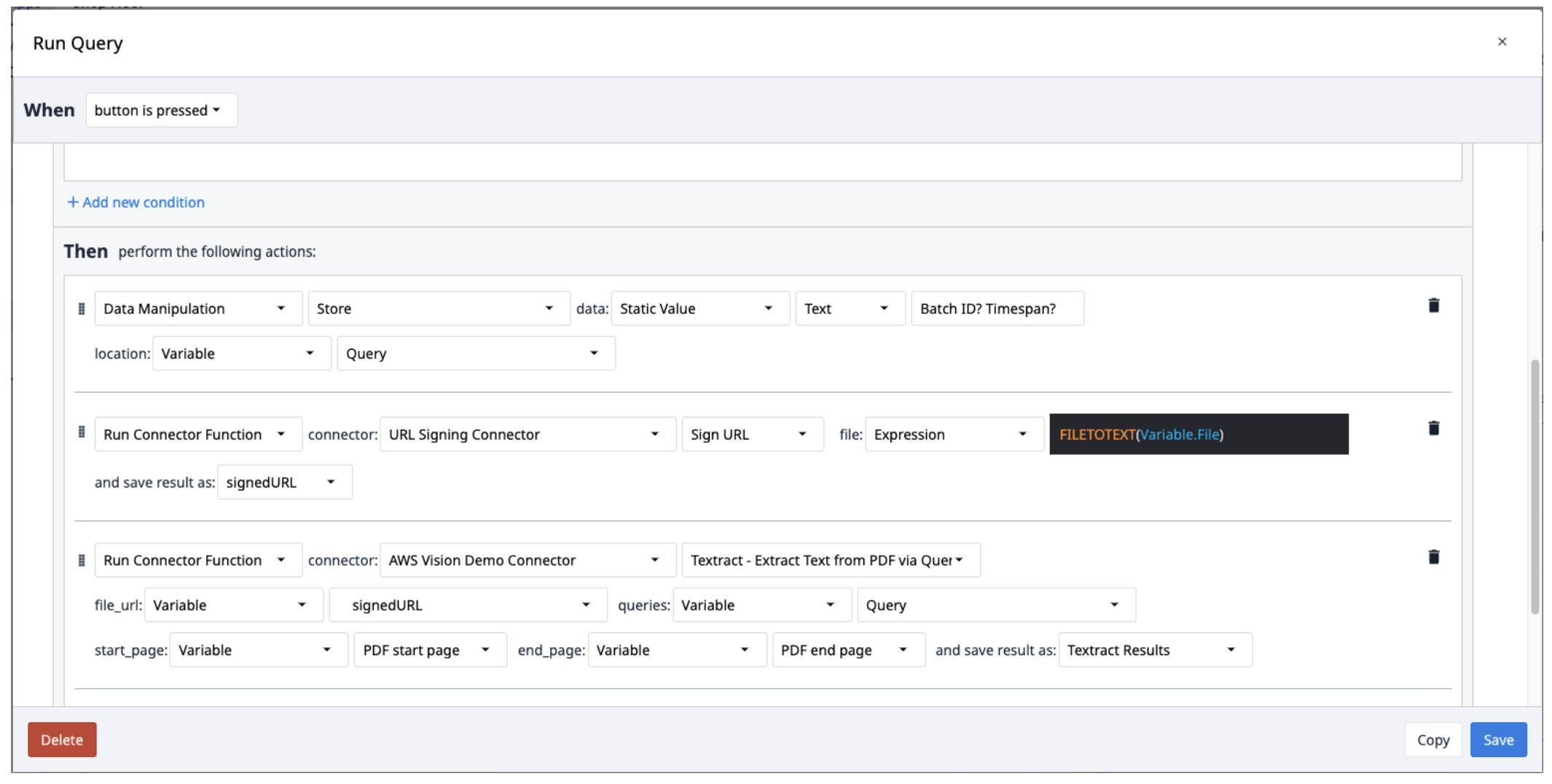
Creare un nuovo trigger con le seguenti azioni:
- Salvare le query in una variabile di testo separata da punti interrogativi (?).
- Eseguire il connettore di firma degli URL con la funzione Sign URL. Il file di input deve essere una variabile di testo. Utilizzare l'espressione FILETOTEXT (variable.File), dove "File" è il nome della variabile, per convertire il nome del file in una stringa di testo. Salvare l'output in una variabile e nominarla ("SignedURL").
- Eseguire AWS Textract estraendo il testo da un PDF tramite la funzione query connector con l'input URL firmato (file_url), la variabile queries e le pagine iniziali e finali del PDF. Salvare l'output in un nuovo array.
Avete trovato quello che cercavate?
Potete anche andare su community.tulip.co per postare la vostra domanda o vedere se altri hanno affrontato una domanda simile!
Questo articolo è stato utile?