

Dans ce guide, vous apprendrez:- Quand stocker les données dans Tulip ou dans un système externe- Comment extraire des données d'autres systèmes- Ce dont vous avez besoin pour intégrer un système à Tulip.
Les opérations tirent souvent des données de sources multiples, dans Tulip et à l'extérieur. Pour les sources de données externes, vous devrez vous connecter via Tulip.
Establishing secure data connections may require IT personnel.
Quand stocker les données dans Tulip ou dans un système externe ?
Dans Tulip, vous pouvez stocker des données à deux endroits :
- Tables
- Complétions
Les données de Tulip (par exemple les données de processus, les instructions de travail, l'équipement) sont directement mises à jour à partir de vos opérations numériques.
Mais qu'en est-il des données auxquelles vous faites référence dans la production et qui sont stockées ailleurs ? Il peut s'agir de
- des systèmes ERP/WMS
- des anciens systèmes MES
- des bases de données
- PLM (par exemple pour les nomenclatures)
- Système de gestion de la qualité (QMS)
Vous pouvez interagir avec les données externes de différentes manières, en fonction de l'usage que vous en faites (par exemple, lecture et écriture de données dans une base de données API/SQL ou visualisation de données de gestion à des fins de référence pour la production).
Une source unique de vérité est un élément essentiel pour obtenir des données précises et en temps réel. Une source de vérité garantit que les données ne sont pas dupliquées ou représentées à plusieurs endroits.
Les données de Tulip et les données externes sont des sources de vérité respectives, et aucune ne doit être remplacée ou répliquée : - Un système externe fournit des exigences claires, des mesures commerciales ou des données sur les clients pour le contexte du flux de travail numérique - Les données de Tulip contiennent des données opérationnelles et de processus pour les rapports en temps réel.
Ce diagramme montre la séparation des données de Tulip et d'un ERP :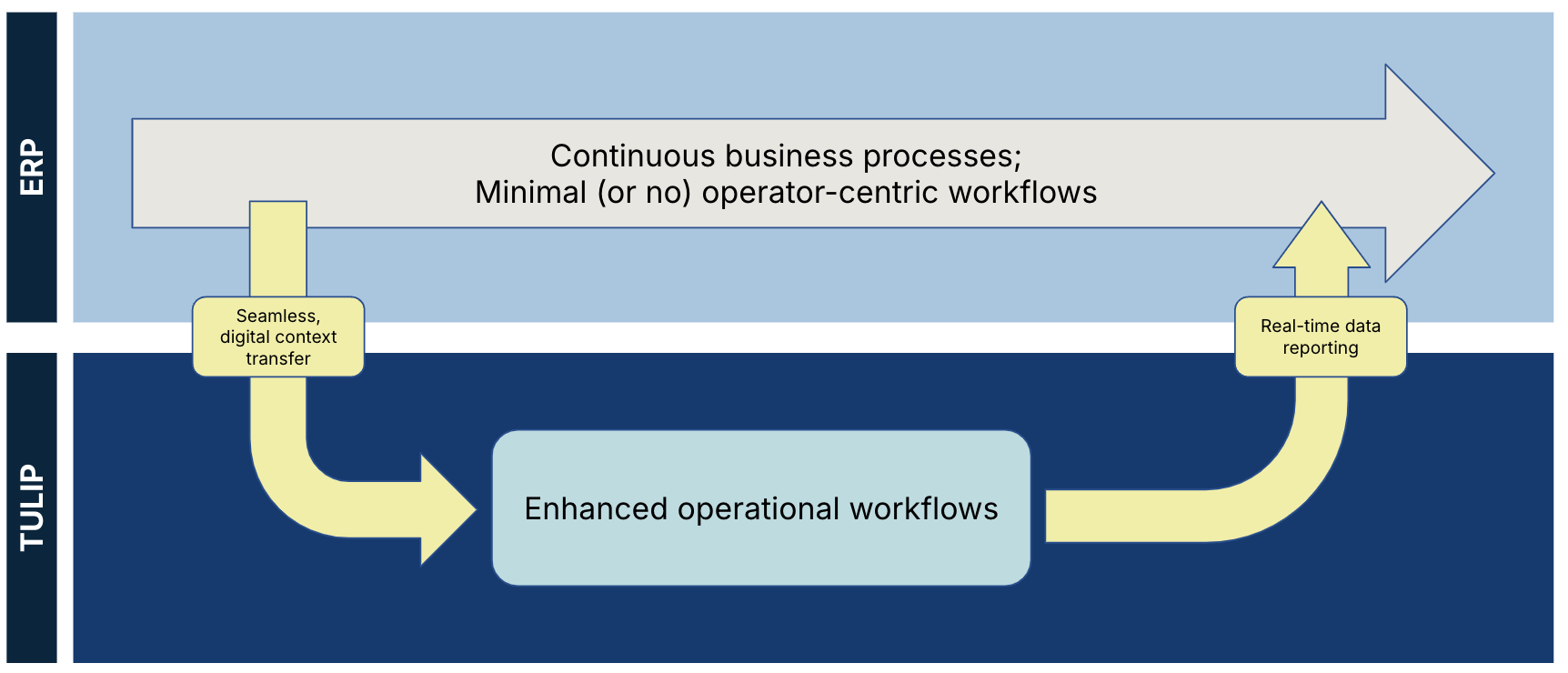
Vous ne devriez utiliser des données provenant de sources externes qu'en cas de besoin. Cette pratique signifie qu'un autre système peut fournir des informations contextuelles pour la production tandis que les données de Tulip améliorent les informations provenant d'une source externe.
Comment savoir si vous devez utiliser des données externes ?- Obtenez-vous une valeur minimale de la solution sans intégration ? - Êtes-vous en mesure d'intégrer rapidement (moins d'un mois) ?
Les intégrations devraient débloquer un niveau de valeur, mais elles ne sont généralement pas essentielles à la valeur potentielle.
Exemple : Bons de travail provenant d'un ERP
- Les bons de travail sont stockés dans un ERP
- Une application de gestion Tulip récupère le bon de travail dans l'ERP
- L'application de gestion crée un enregistrement du bon de travail dans une table Tulip pour stocker les données de production.
- Les applications d'instructions de travail et d'assemblage saisissent les données de production dans la table des ordres de travail et les données de processus conformes dans les achèvements.
Écosystème ouvert
Un écosystème ouvert exploite des solutions multiples et connectées pour répondre aux besoins uniques d'une organisation. Plutôt que d'utiliser un seul système pour tout, l'approche de l'écosystème ouvert de Tulip donne la priorité à Composability plutôt qu'à un contrôle descendant.
Le diagramme ci-dessous montre comment les capacités numériques de Tulip s'intègrent à d'autres systèmes.
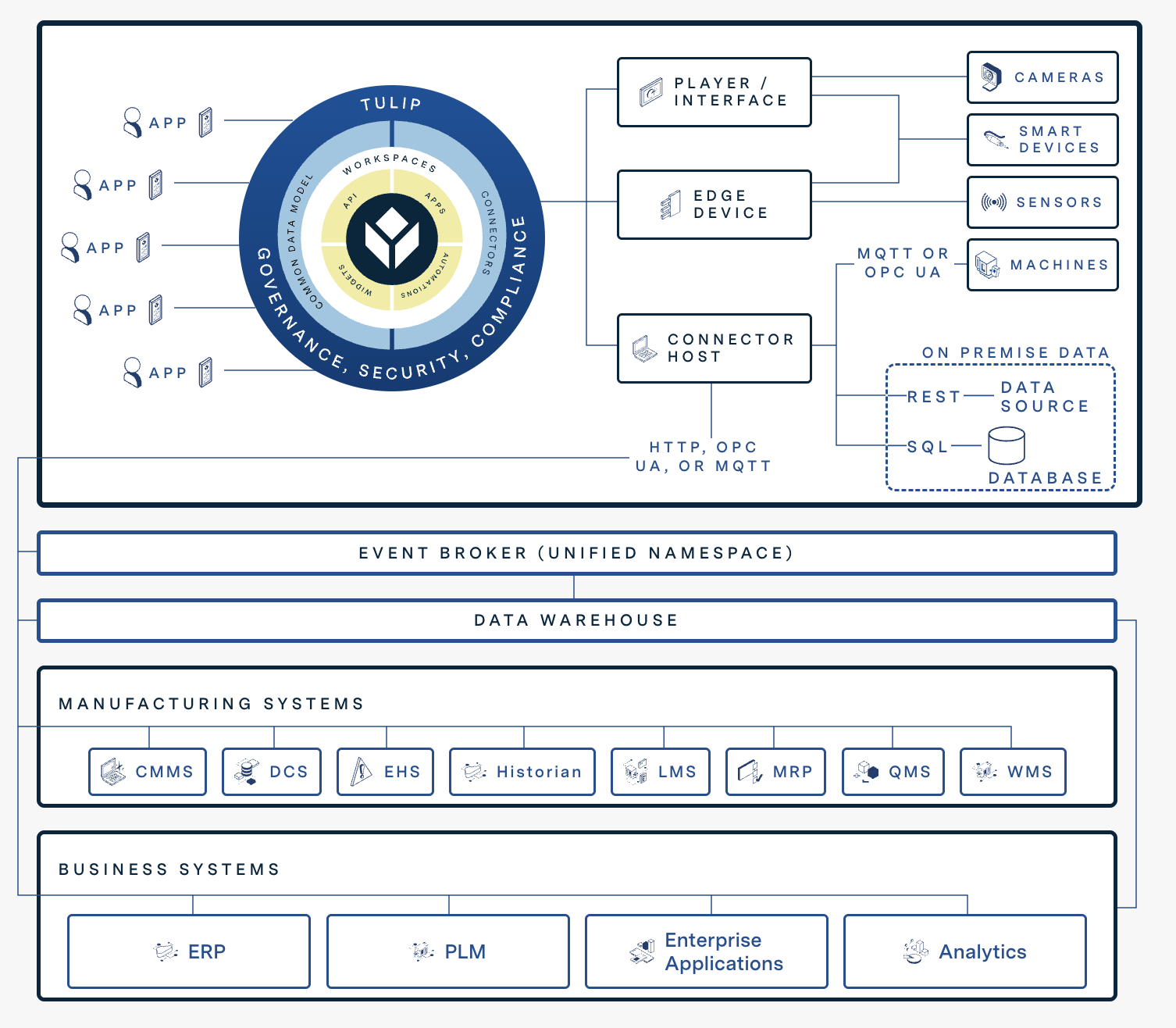
Intégration des systèmes
Les intégrations de systèmes n'ont généralement pas besoin d'être dans la première étape du déploiement. Tulip recommande que vous construisiez d'abord votre produit de valeur minimale sans intégration de système, puis que vous fassiez les ajustements nécessaires. Ceci est dû au fait que les intégrations de systèmes peuvent prendre jusqu'à plusieurs mois pour être mises en place.
Une intégration de système avec Tulip implique généralement 3 facteurs:- Les capacités et les paramètres du système lui-même- La complexité de l'environnement informatique de votre entreprise- Les capacités de votre équipe informatique à travailler avec le système.
Les intégrations ne sont pas tout ou rien - vous devez vous concentrer sur la définition des données minimales nécessaires pour fournir un contexte opérationnel dans une application.
Le diagramme ci-dessous montre une intégration ERP typique avec Tulip :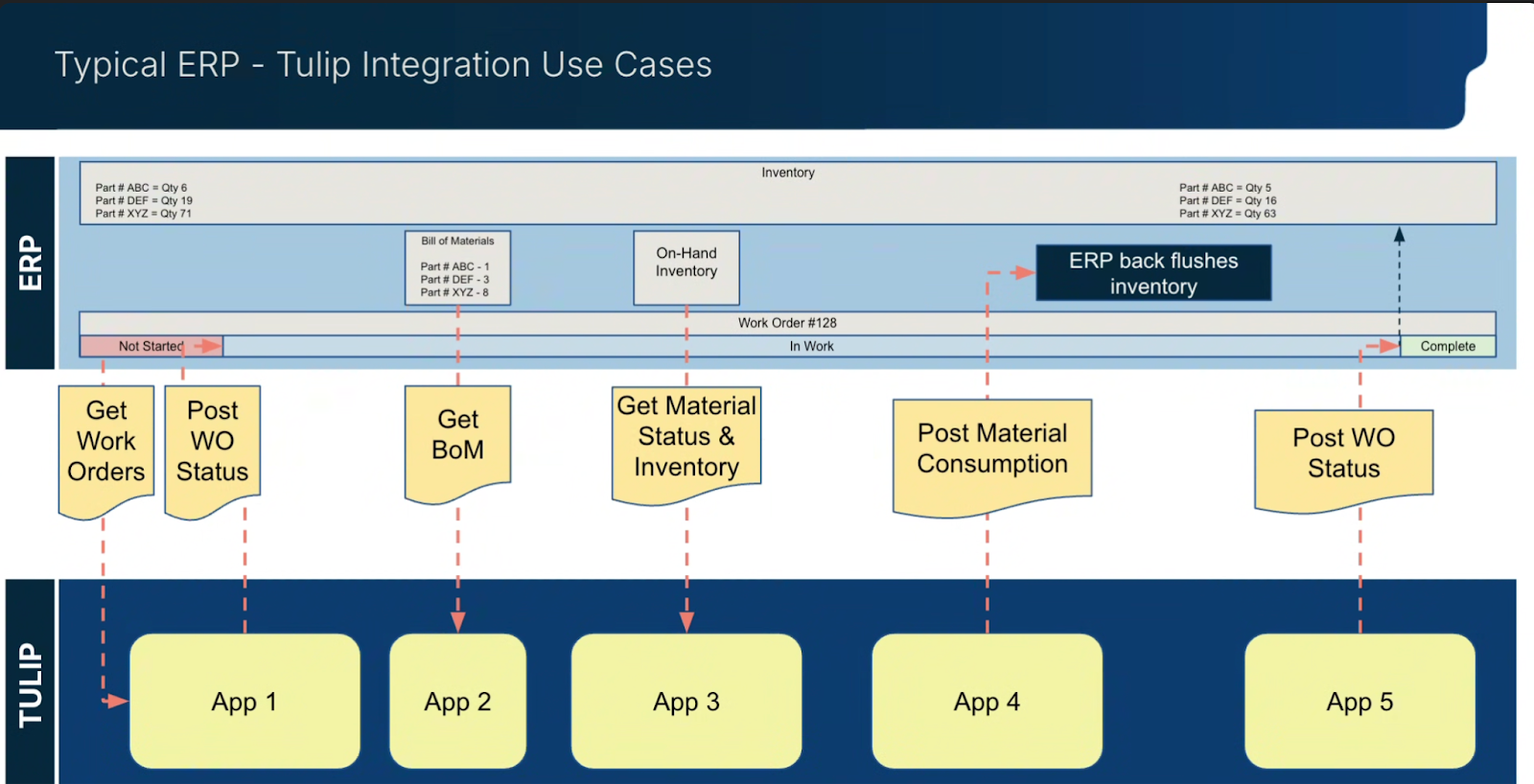
Pour en savoir plus sur la planification d'une intégration , cliquez ici.
Flux de données d'intégration
La façon dont Tulip "parle" à un système externe est la suivante:* Un connecteur utilise des paramètres sécurisés pour obtenir un "accès" au système* Une fonction de connecteur commande l'information vers/depuis le système* Une action de déclenchement (créée dans l'éditeur d'application) exécute la fonction de connecteur (par exemple, en appuyant sur un bouton)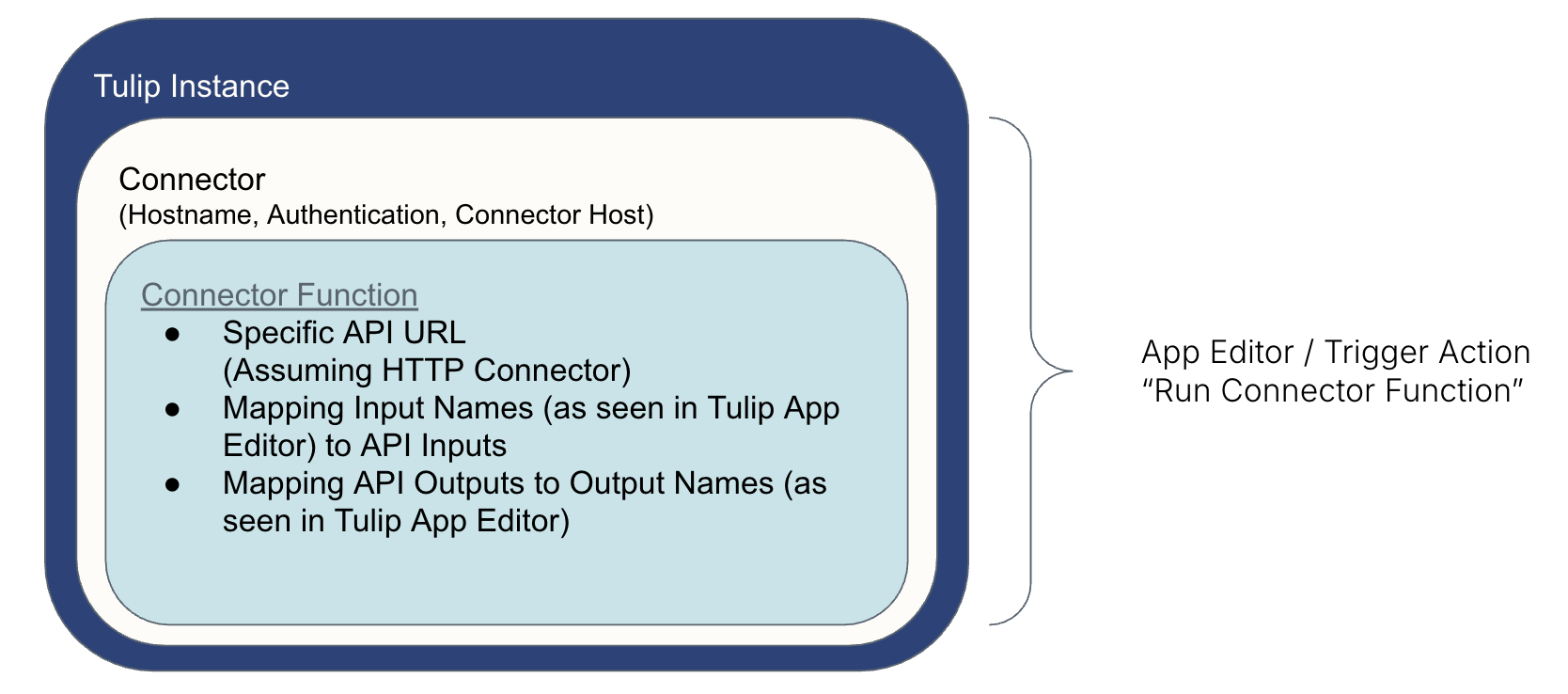
Comment se connecter à un système ?
Explorons et décomposons les fonctions qui rendent ces connexions possibles.
Connecteurs
Les connecteurs sont le cadre de Tulip pour créer des connexions entre Tulip et des systèmes tiers. Ce sont des intégrations puissantes pour visualiser, gérer et interagir avec des données provenant de systèmes externes dans des applications.
Pourquoi utiliser les connecteurs ?
Les connecteurs sont la façon dont Tulip communique avec les systèmes externes. Les outils de votre pile et le degré d'intégration requis dans vos applications déterminent la façon dont vous utilisez les connecteurs.
Quelques cas d'utilisation des connecteurs incluent:* Obtenir des informations d'une source de vérité (par exemple les ordres de travail de votre ERP)* Enregistrer la consommation de matériel (par exemple à votre ERP)* Envoyer un message Slack
Comment fonctionnent les connecteurs
Les connecteurs établissent une connexion entre Tulip et un système tiers. Ils gèrent la direction et l'authentification qui permettent aux données de transiger.
La transaction de données est rendue possible grâce à un hôte de connecteur. Les hôtes de connecteurs permettent à Tulip de se connecter à des systèmes externes, agissant comme un lien direct entre les deux. Tulip fournit un Cloud Connector Host, mais vous pouvez également utiliser un Connector Host sur site.
Pour en savoir plus sur les connecteurs hôtes , cliquez ici.
Alors que l'hôte de connecteur établit la connexion, les fonctions de connecteur permettent à vos connecteurs d'effectuer des tâches telles que l'extraction d'informations, l'écriture dans des tables et l'édition de données existantes. Les fonctions de connecteur demandent des actions au système tiers qui passe par l'hôte de connecteur.
Vous pouvez également apporter des modifications à votre fonction, telles que des paramètres de requête et des réponses, qui déterminent les données renvoyées. Bien qu'une connaissance préalable de {{glossaire.JSON}} ne soit pas nécessaire, une familiarité avec des aspects tels que {{glossaire.Dotation}} et la structure générale des données est utile pour mieux comprendre vos fonctions de connecteur.
Types de connecteurs
Afin de comprendre les différents systèmes auxquels vous pouvez vous connecter, il est important de noter qu'il existe trois types de connecteurs différents qui extraient des informations de différentes sources :
HTTP
Les connecteurs HTTP accèdent aux données à partir d'API externes. Il s'agit du connecteur le plus couramment utilisé. Les connecteurs HTTP peuvent s'interfacer avec la plupart des types d'API HTTP, y compris REST et SOAP.
Les fonctions des connecteurs HTTP peuvent effectuer les types d'appels {{glossaire.API Call}} suivants :
- GET
- HEAD
- POST
- PUT
- BATCH
- DELETE
SQL
Lesconnecteurs SQL permettent d'accéder à des données provenant de bases de données externes. Avec un connecteur SQL, vous pouvez modifier les données de la table, récupérer des données et manipuler un ensemble de données existant.
Tulip supporte les connecteurs SQL suivants :
- Microsoft SQL Server
- PostgreSQL
- MySQL
- Oracle
Accédez aux connecteurs HTTP et SQL via la page Connecteurs de votre instance.
MQTT
Connectez-vous aux courtiers MQTT pour la surveillance des machines. Tulip peut nativement publier des données de son produit vers votre courtier MQTT, s'intégrant de manière transparente dans un espace de noms unifié ou un bus d'événements d'entreprise.
Les champs suivants peuvent être définis pour une fonction de connecteur MQTT : - Qualité de service - Sujet - Conserver le message - Charge utile - Entrées définies par l'utilisateur.
Connectivité de la périphérie
Certaines de ces machines comprennent des dispositifs de périphérie, que vous pouvez découvrir ici :
API de table
En utilisant des connecteurs, une application Tulip peut lancer une requête HTTP ou SQL. Avec l'API de Tulip, vous pouvez communiquer avec et intégrer Tulip à partir de systèmes externes. Cette API fonctionne en amenant des données dans Tulip depuis un autre système et en vous permettant d'écrire dans ces autres systèmes. L'API Table offre diverses possibilités, notamment : * Mettre à jour un enregistrement de table* Créer une table* Trouver le nombre d'enregistrements de table
L'API de Tulip ne fonctionne actuellement qu'avec les tables de Tulip. Pour utiliser l'API de table, vous devez avoir une compréhension de base du fonctionnement des API.
Accédez à la documentation de l'API de Tulip ici.
Pour vous entraîner à l'utilisation de l'API Table, suivez le cours de l'Université Tulip : Feature Deep Dive : Table API.
Prochaines étapes
En savoir plus sur les intégrations et commencer à se connecter:* Comment créer un connecteur* Comment configurer des connecteurs rapides
Vous avez trouvé ce que vous cherchiez ?
Vous pouvez vous rendre sur community.tulip.co pour poser votre question ou voir si d'autres personnes ont rencontré une question similaire !