
This video walks through instructions of using Fivetran + AWS Lambda to fetch Tulip table data on a scheduled basis and update a variety of destinations such as data warehouses, databases, data lakes, and more
Streamline Tulip data engineering with Fivetran integration
Purpose
Streamlining data engineering pipelines with Tulip enables usage of Tulip tables data across the enterprise
Setup
This requires the following for setup:
- Fivetran account (Free Version is available)
- AWS (Or other cloud account)
- Database or Data Warehouse for receiving Tulip Tables data
- High-level knowledge of Python
How it works
This fivetran automation setup works with the following steps:
- Set up Fivetran account
- Create Destination (e.g., Snowflake)
- Create Connector function with AWS Lambda function
- Create AWS Lambda function
- Finalize Connector function
- Test Fivetran connector and adjust refresh frequency
Fivetran uses the lambda function to automatically fetch tulip tables data on a scheduled basis and update destination databases or data warehouses. The example included is a simple function which re-writes the table with new, refreshed data. Additional functionality can be added for improved event-based triggers.
Setup Instructions
Set Up Fivetran Account
First you will need to set up a Fivetran account. They offer a free version with a limited number of refreshes per month
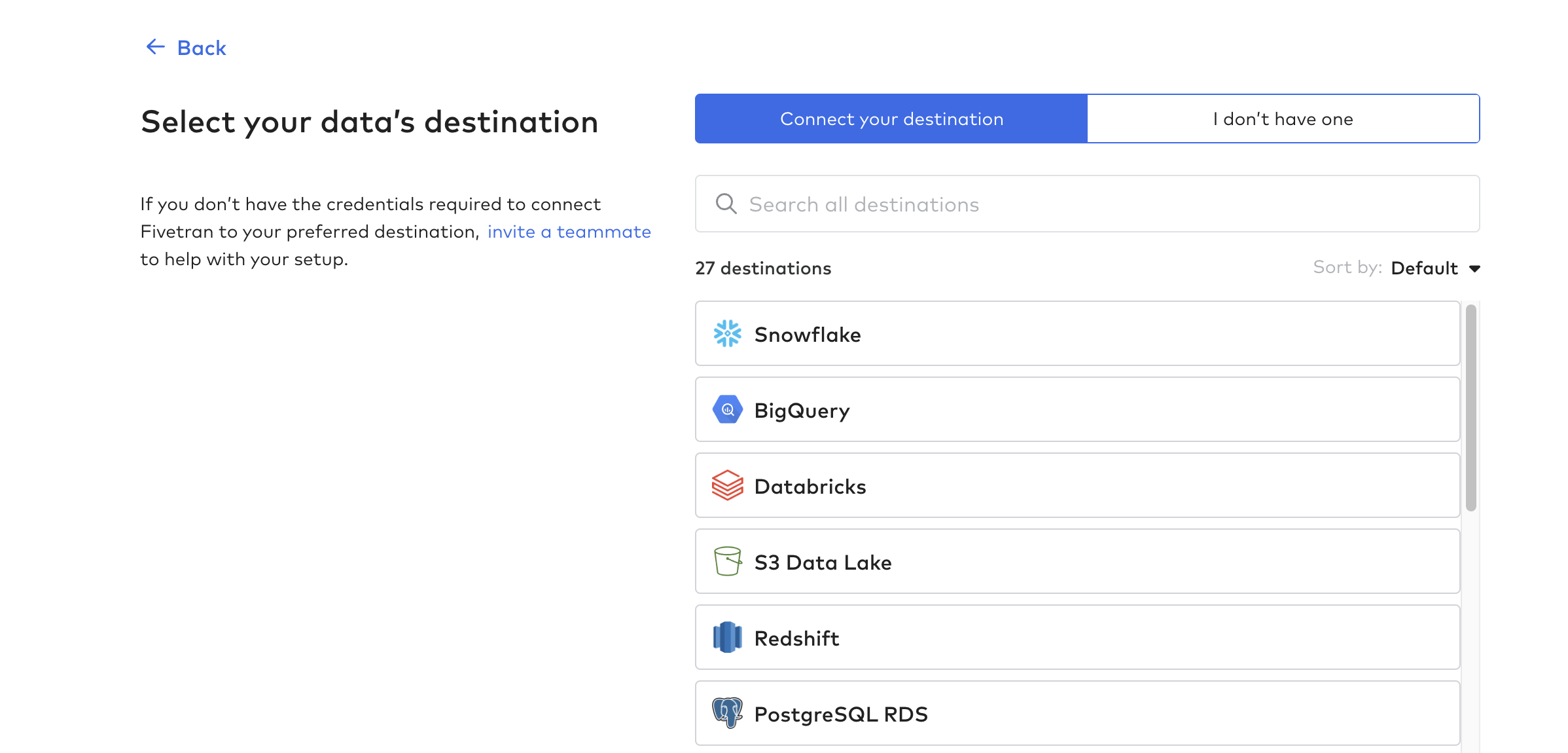
Set Up Destination
Then, click on Destinations and create your first destination. This is essentially the database or data warehouse that will receive the Tulip tables data
Create Connector Function
Then, create the connector function; this is the process for automating the data pipeline from Tulip. You can use any cloud function such as AWS Lambda, Azure Functions, or GCP Cloud Functions. For this example, we'll use AWS Lambda
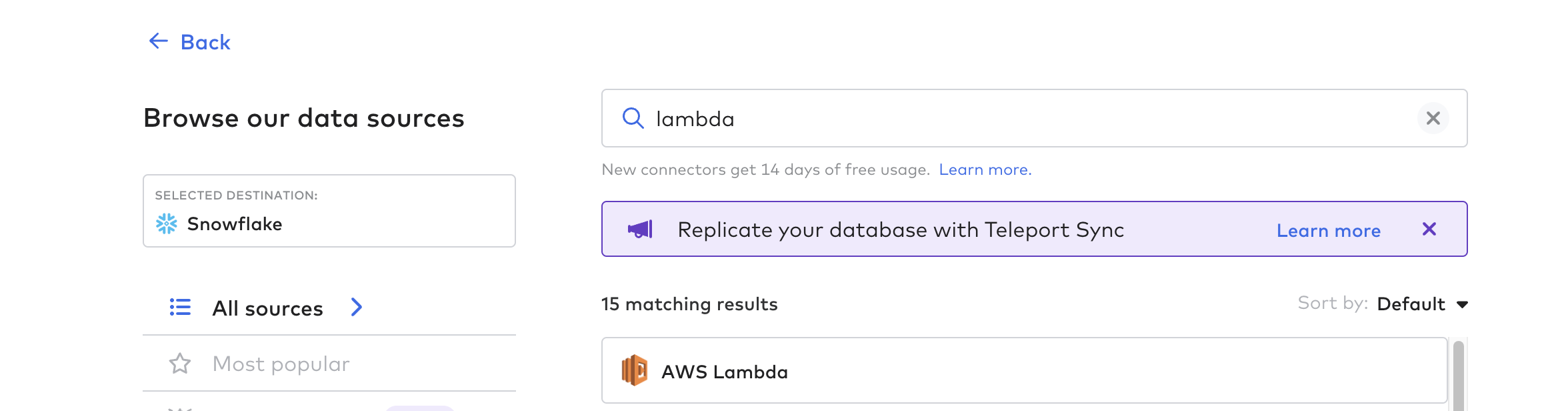
Follow the in-Fivetran instructions for creating a Lambda function on AWS with the appropriate roles and permissions
See link for lambda function template as a starting point
Below are some helpful tips:
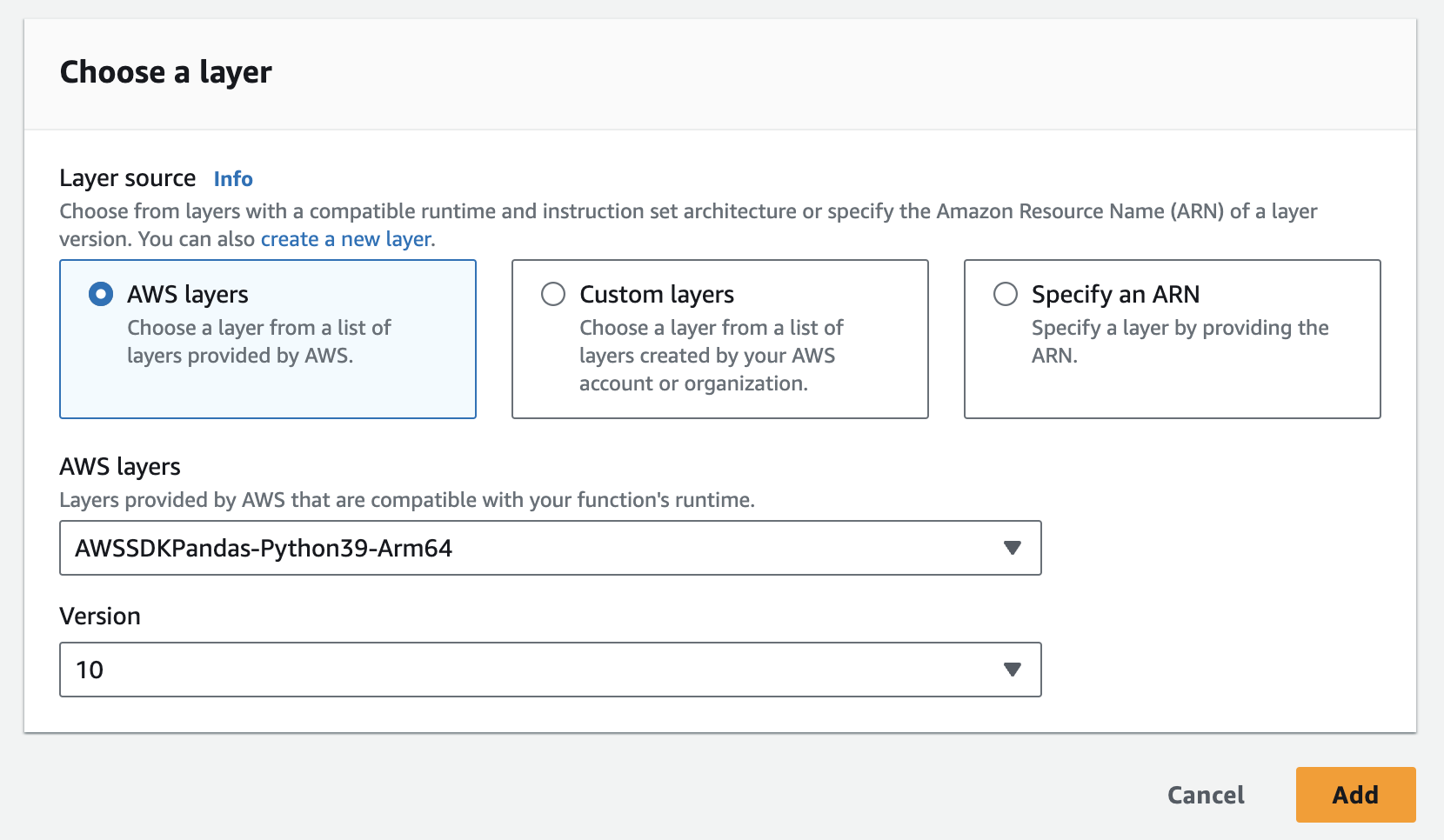
- You will have to create two layers: one is for the tulip library; the other is for the pandas library
- You can view the Tulip community API here
- You can download the zip file here alternatively (This has been prepped for adding to a layer
- You can easily add the pandas layer in AWS below
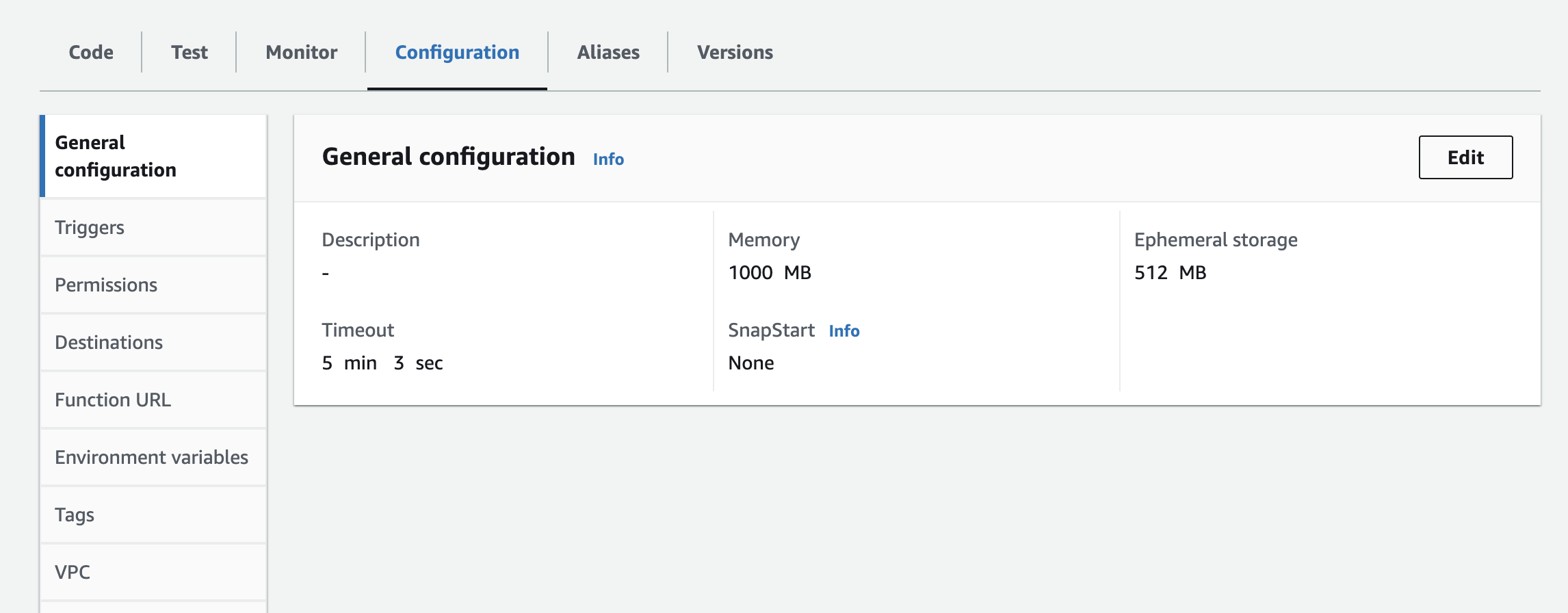
- You will have to add the instance, API Key, and API Secret as environment variables to the lambda function. You may have to update the runtime settings to increase the timeout time and memory used. Screenshot below for updating configuration
Next Steps
Once the connector function is working, you can adjust the refresh frequency, view Tulip tables information in the destination database or Data Warehouse and additional more functionality
Some specific use cases for this data pipeline:
- Enterprise-level analytics and data processing of Tulip data
- Batch automations with enterprise systems
- Contextualization with Data Warehouses and Data Lakes
Additional Resources
Reach out to Fivetran for additional support hereReach out to Fivetran for additional support here
*
Additionally, they have provided a form to make adjustments and requests for simplified Tulip tables integration. Provide feedback and request here