Tulipán OCR con AWS Textract
- 31 Jan 2024
- 5 Minutos para leer
- Colaboradores




- Impresión
Tulipán OCR con AWS Textract
- Actualizado en 31 Jan 2024
- 5 Minutos para leer
- Colaboradores
- Impresión
Article Summary
Share feedback
Thanks for sharing your feedback!
:::(Warning) (Nota) Con Frontline Coplilot™, el texto puede ser extraído directamente de imágenes y documentos, simplificando significativamente el proceso para hacer OCR contra imágenes en Tulip. En el futuro, este es el enfoque recomendado :::
Este artículo le guiará a través de la configuración de AWS Textract Connector en Tulip.
AWS Textract es un servicio basado en la nube proporcionado por Amazon Web Services (AWS) que utiliza la tecnología de aprendizaje automático para extraer texto y datos de diversos tipos de documentos. Textract puede analizar documentos escaneados, PDF, imágenes y otros archivos para extraer automáticamente contenido textual, tablas, formularios y pares clave-valor.
Las características y capacidades clave de AWS Textract incluyen:
- Reconocimiento óptico de caracteres (OCR): Textract utiliza OCR para extraer texto de documentos e imágenes escaneados, incluso si están en diferentes idiomas o tienen diseños complejos.
- Extracción de pares clave-valor: Textract puede extraer pares clave-valor de documentos, como facturas o recibos, identificando la relación entre las etiquetas y sus valores asociados.
- Extracción de tablas: Textract puede detectar y extraer datos tabulares de documentos, conservando la estructura de la tabla, las filas y las columnas.
- Extracción detexto basada en consultas: Textract permite recuperar información específica de documentos mediante consultas en lenguaje natural.
- Soporte para múltiples formatos de documentos: Textract soporta una amplia gama de formatos de documentos, incluyendo PDF, JPEG, PNG y TIFF.
- Extracción de formularios (próximamente): Textract puede identificar automáticamente campos de formulario, como casillas de verificación, botones de radio y campos de texto, y extraer los datos correspondientes.
Requisitos previos
- Una estación de trabajo Tulip Vision en funcionamiento con una cámara para inspección visual.
- Contacta con Tulip Support para obtener AWS Textract Connector y API Key (Textract App llegará a Tulip Library pronto)
- Para la extracción de archivos PDF crear un conector Sign-in URL
Configuración de Tulip Connector
En tu instancia de Tulip, selecciona Connectors en el menú Apps.
Selecciona el Conector AWS y asegúrate de que está en línea, o configura uno con los siguientes Detalles de Conexión:
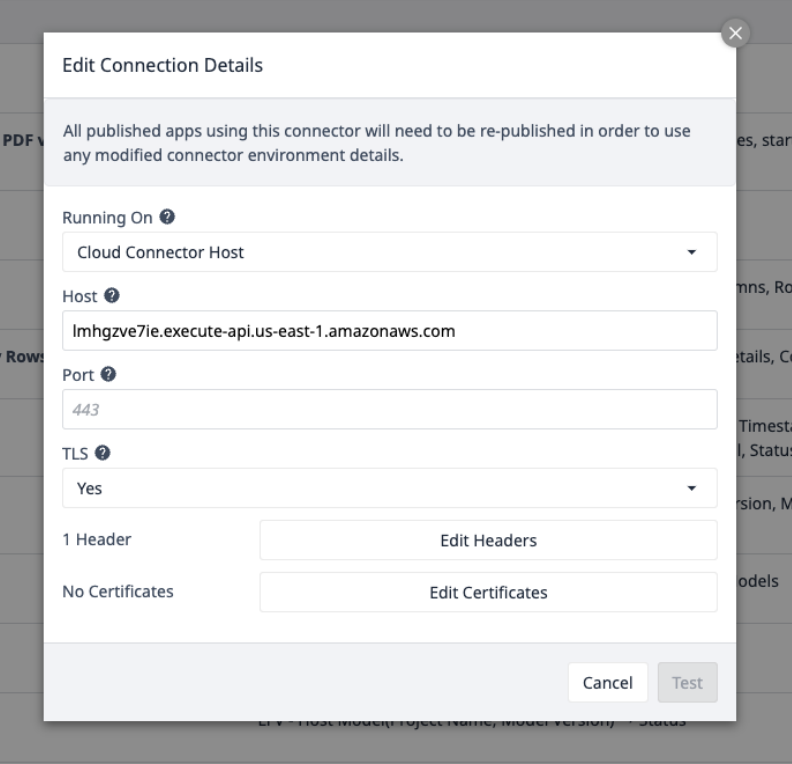
Selecciona Edit Headers y actualiza la X-API-Key, proporcionada por Tulip.
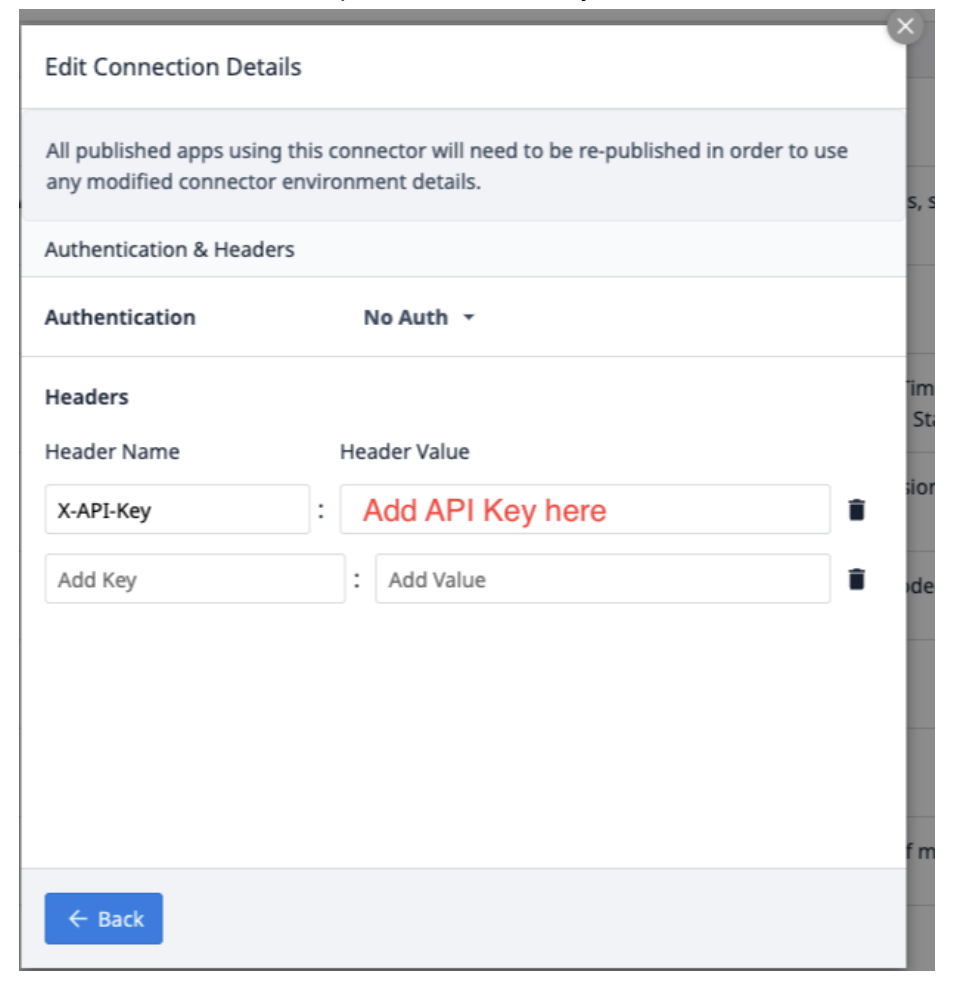
Selecciona Back y haz clic en Test.
Textract en una aplicación Tulip para pares clave-valor (extracción de un PDF)
En este ejemplo, veremos cómo utilizar Textract en una aplicación para obtener pares clave-valor de un PDF. Tendrás que crear y configurar una función de conector en el conector de AWS, así como utilizar la lógica de activación para ejecutar el conector y extraer los datos que deseamos.
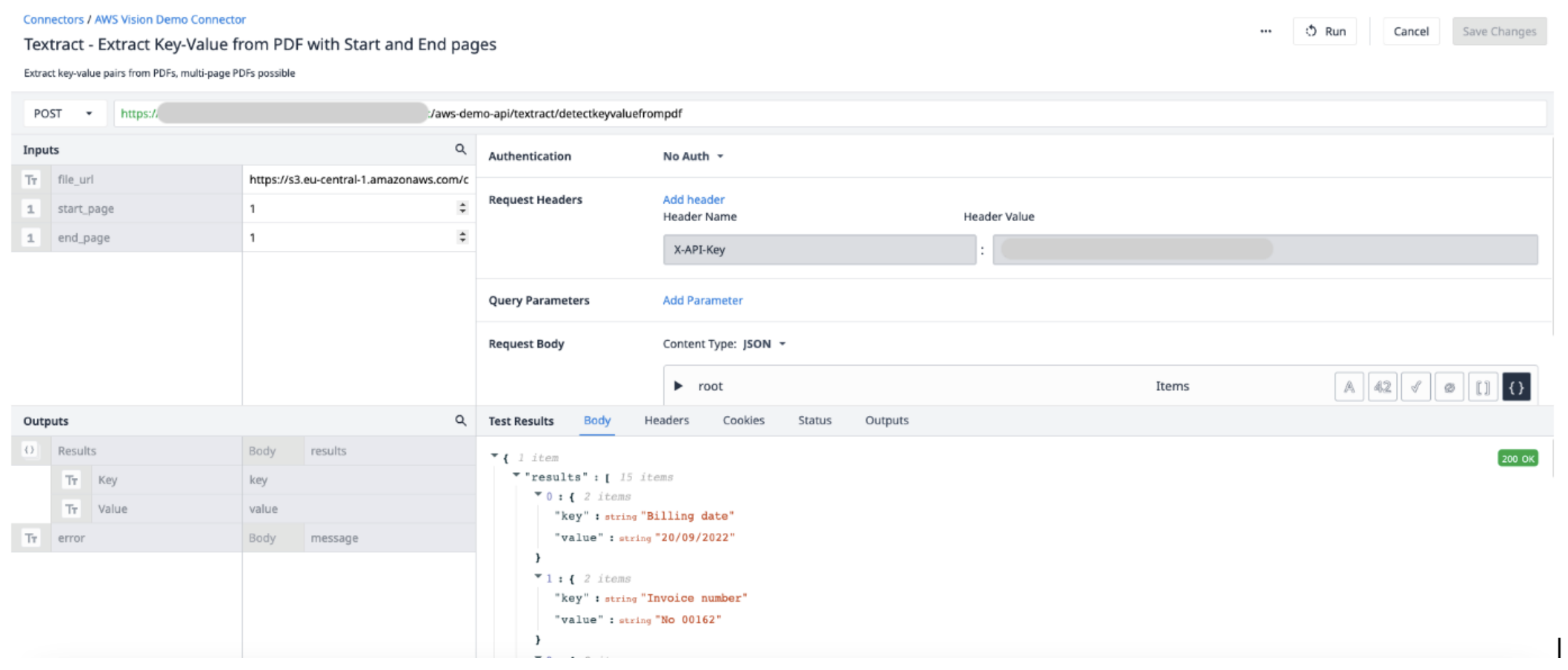
Detalles de la función de conector
Crea una nueva función de conector en el conector de AWS. Utiliza la siguiente información para establecer los Inputs y Outputs.
Entradas File_url (Texto) - URL del archivo PDF subido a Tulip Start_page (Int) - la primera página del archivo PDF a extraer End_page (Int) - la última página del archivo PDF a extraer
OutputResults (Objects) - una lista de objetos de pares clave y valor.
Activador de aplicación
En su aplicación, los disparadores llamarán a la función del conector para que se ejecute.
Crea un nuevo disparador con las siguientes acciones
- Ejecutar el conector de firma de URL con la función Firmar URL. El archivo de entrada debe ser una Variable de texto. Utilice la expresión FILETOTEXT (variable.Archivo), donde "Archivo" es el nombre de la variable, para convertir el nombre del archivo en una cadena de texto. Guarde la salida en una variable y nómbrela ("SignedURL").
- Ejecute la función del conector de pares clave-valor de AWS Textract con la entrada de URL firmada (file_url), así como las páginas de inicio y fin del PDF que se van a extraer. Guarde el resultado en un nuevo Array.
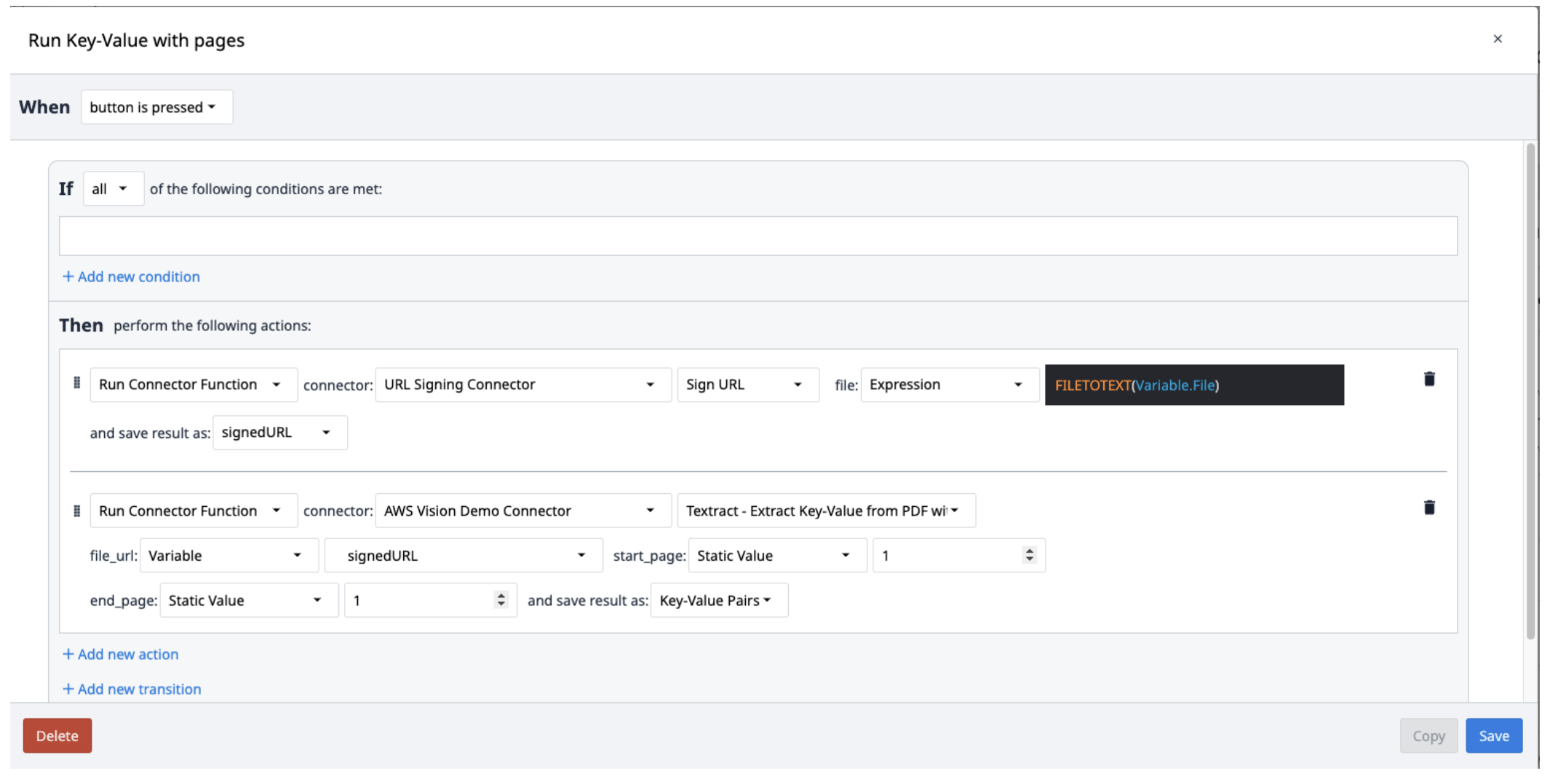
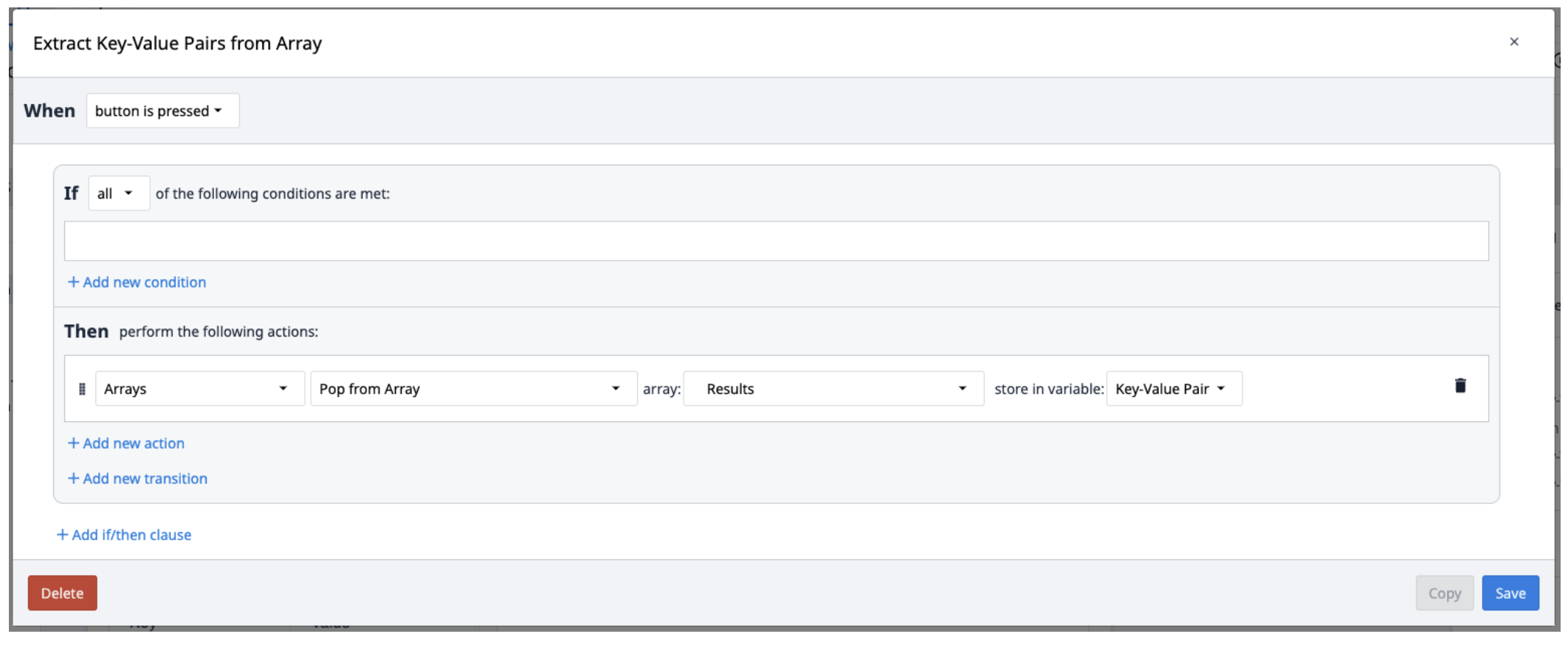
Los resultados de Textract se guardan en una matriz de objetos que contienen pares clave-valor. Para extraerlos de la matriz, cree un nuevo disparador que repita la extracción de los pares de la matriz según sea necesario.
Puede utilizar el Looping Customer Widget para extraer múltiples objetos del array.
Textract en una aplicación Tulip para realizar consultas (extracción de un PDF)
En este ejemplo, veremos cómo utilizar Textract en una aplicación para consultar datos extraídos de un PDF. Tendrás que crear y configurar una nueva función de conector en el conector de AWS, así como utilizar la lógica de activación para ejecutar el conector. La consulta de datos permite comprender o modificar los datos recibidos.
Detalles de la función de conector
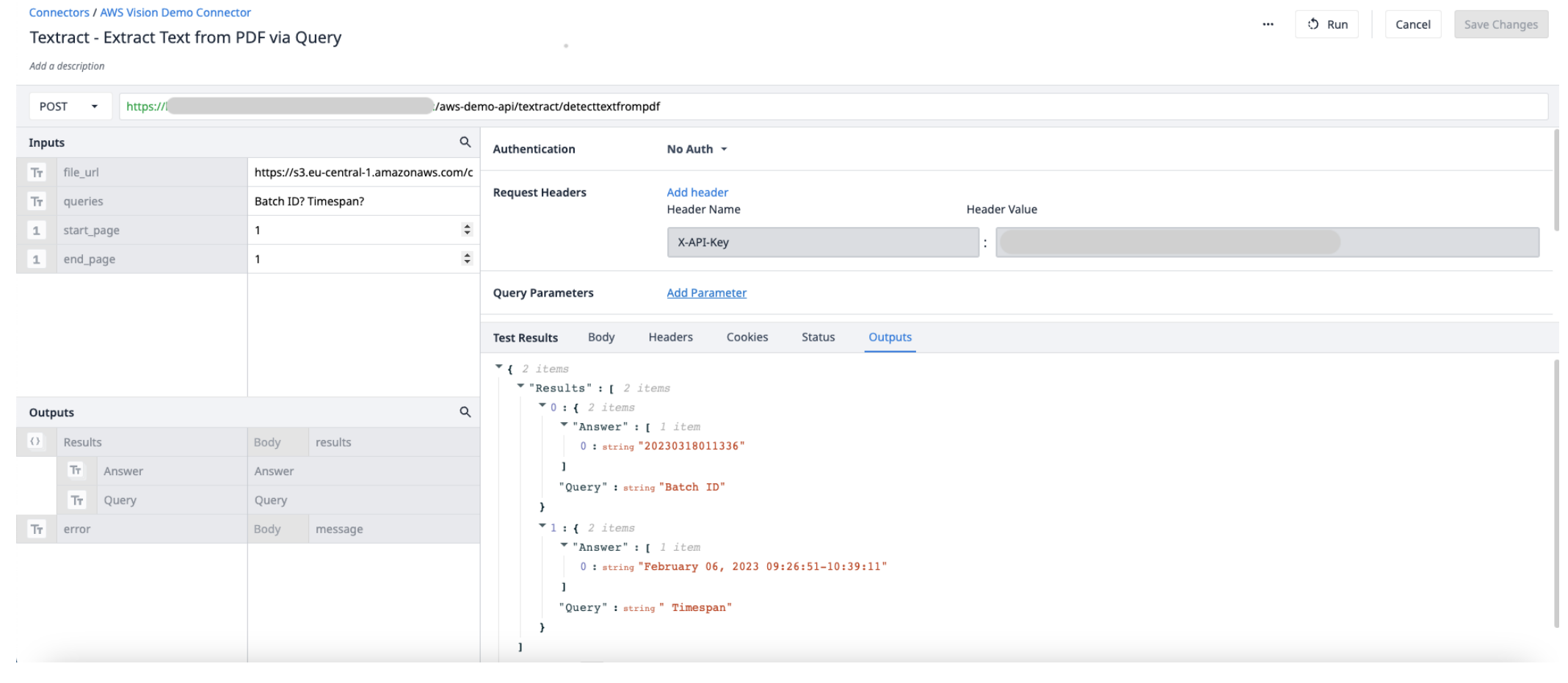
Crea una nueva función de conector en el conector de AWS. Utilice la siguiente información para establecer los Inputs y Outputs.
Entradas File_url (Texto) - URL del archivo PDF cargado en Tulip Start_page (Int) - la primera página del archivo PDF de la que extraer End_page (Int) - la última página del archivo PDF de la que extraer
OutputResults (objects) - una lista de objetos de Respuestas y Consultas
Disparador de la aplicación
En su aplicación, los disparadores llamarán a la función del conector para que se ejecute.
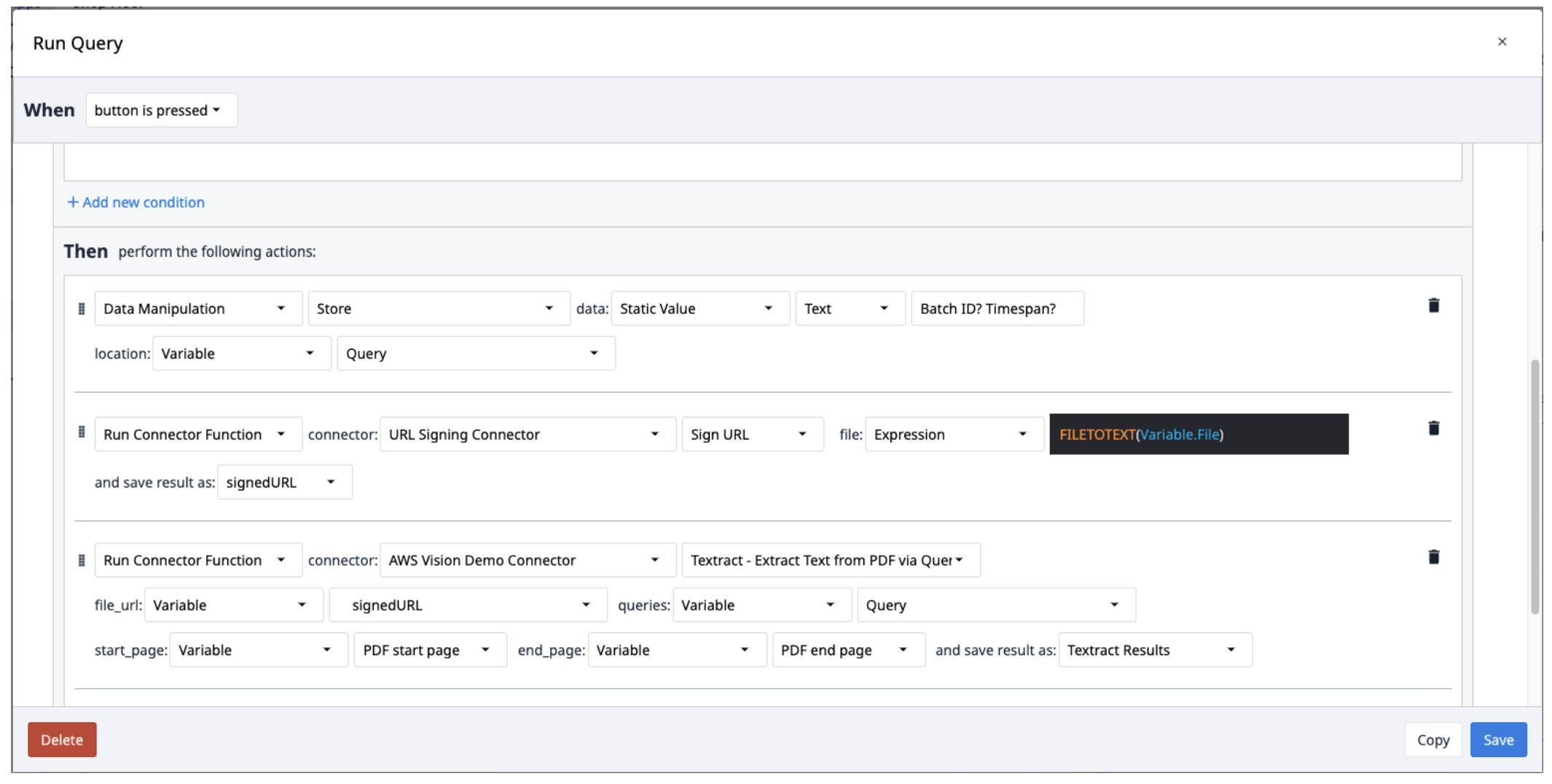
Cree un nuevo disparador con las siguientes acciones
- Guarda las consultas en una variable de texto separadas por signos de interrogación (?).
- Ejecuta el conector de firma de URL con la función Firmar URL. La entrada del archivo debe ser una variable de texto. Utiliza la expresión FILETOTEXT (variable.Archivo), donde "Archivo" es el nombre de la variable, para convertir el nombre del archivo en una cadena de texto. Guarde la salida en una variable y nómbrela ("SignedURL").
- Ejecute el AWS Textract extrayendo texto de un PDF a través de la función del conector de consulta con la entrada URL firmada (file_url), la variable de consulta y las páginas inicial y final del PDF. Guarde la salida en un nuevo array.
¿Ha encontrado lo que buscaba?
También puedes dirigirte a community.tulip.co para publicar tu pregunta o ver si otras personas se han enfrentado a una pregunta similar.
¿Te ha sido útil este artículo?