Tulip OCR mit AWS Textract
- 31 Jan 2024
- 4 Minuten zu lesen
- Mitwirkende




- Drucken
Tulip OCR mit AWS Textract
- Aktualisiert am 31 Jan 2024
- 4 Minuten zu lesen
- Mitwirkende
- Drucken
Article Summary
Share feedback
Thanks for sharing your feedback!
:::(Warning) (Hinweis) Mit Frontline Coplilot™ kann Text direkt aus Bildern und Dokumenten extrahiert werden, was den Prozess der OCR von Bildern in Tulip erheblich vereinfacht. Dies ist der empfohlene Ansatz für die Zukunft. :::
Dieser Artikel führt Sie durch die Einrichtung von AWS Textract Connector in Tulip.
AWS Textract ist ein Cloud-basierter Dienst von Amazon Web Services (AWS), der maschinelle Lerntechnologien verwendet, um Text und Daten aus verschiedenen Arten von Dokumenten zu extrahieren. Textract kann gescannte Dokumente, PDFs, Bilder und andere Dateien analysieren, um automatisch Textinhalte, Tabellen, Formulare und Schlüssel-Werte-Paare zu extrahieren.
Zu den wichtigsten Funktionen und Möglichkeiten von AWS Textract gehören:
- Optische Zeichenerkennung (Optical Character Recognition, OCR): Textract verwendet OCR, um Text aus gescannten Dokumenten und Bildern zu extrahieren, auch wenn diese in verschiedenen Sprachen vorliegen oder ein komplexes Layout haben.
- Extraktion von Schlüssel-Werte-Paaren: Textract kann Schlüssel-Wert-Paare aus Dokumenten wie Rechnungen oder Quittungen extrahieren, indem es die Beziehung zwischen Bezeichnungen und den zugehörigen Werten identifiziert.
- Extraktion von Tabellen: Textract kann tabellarische Daten aus Dokumenten erkennen und extrahieren, wobei die Tabellenstruktur, Zeilen und Spalten erhalten bleiben.
- Abfragebasierte Textextraktion: Textract ermöglicht es Ihnen, spezifische Informationen aus Dokumenten mit Hilfe von Abfragen in natürlicher Sprache zu extrahieren.
- Unterstützung für mehrere Dokumentformate: Textract unterstützt eine Vielzahl von Dokumentenformaten, darunter PDF, JPEG, PNG und TIFF.
- Formularextraktion (in Kürze): Textract kann automatisch Formularfelder wie Kontrollkästchen, Optionsfelder und Textfelder identifizieren und die entsprechenden Daten extrahieren.
Voraussetzungen
- Eine funktionierende Tulip Vision Workstation mit einer Kamera für die visuelle Inspektion
- Wenden Sie sich an den Tulip Support, um den AWS Textract Connector und den API-Schlüssel zu erhalten (die Textract App wird demnächst in die Tulip Library integriert)
- Für die Extraktion von PDF-Dateien erstellen Sie einen Sign-in URL Connector
Tulip Connector einrichten
Wählen Sie in Ihrer Tulip-Instanz Connectors aus dem Menü Apps.
Wählen Sie den AWS Connector und vergewissern Sie sich, dass er online ist, oder richten Sie ihn mit den folgenden Verbindungsdetails ein:
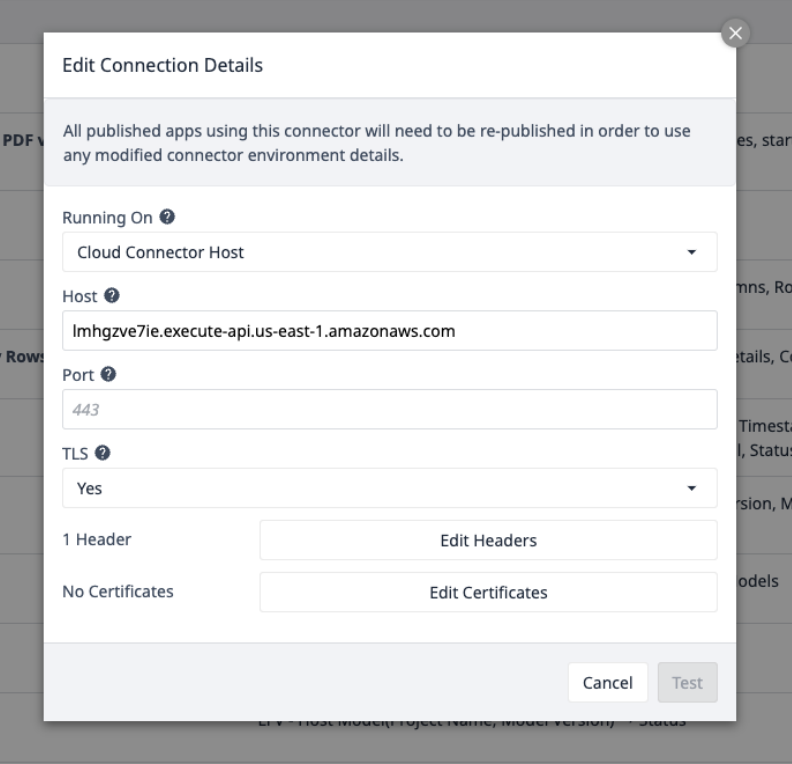
Wählen Sie Header bearbeiten und aktualisieren Sie den X-API-Key, der von Tulip bereitgestellt wird.
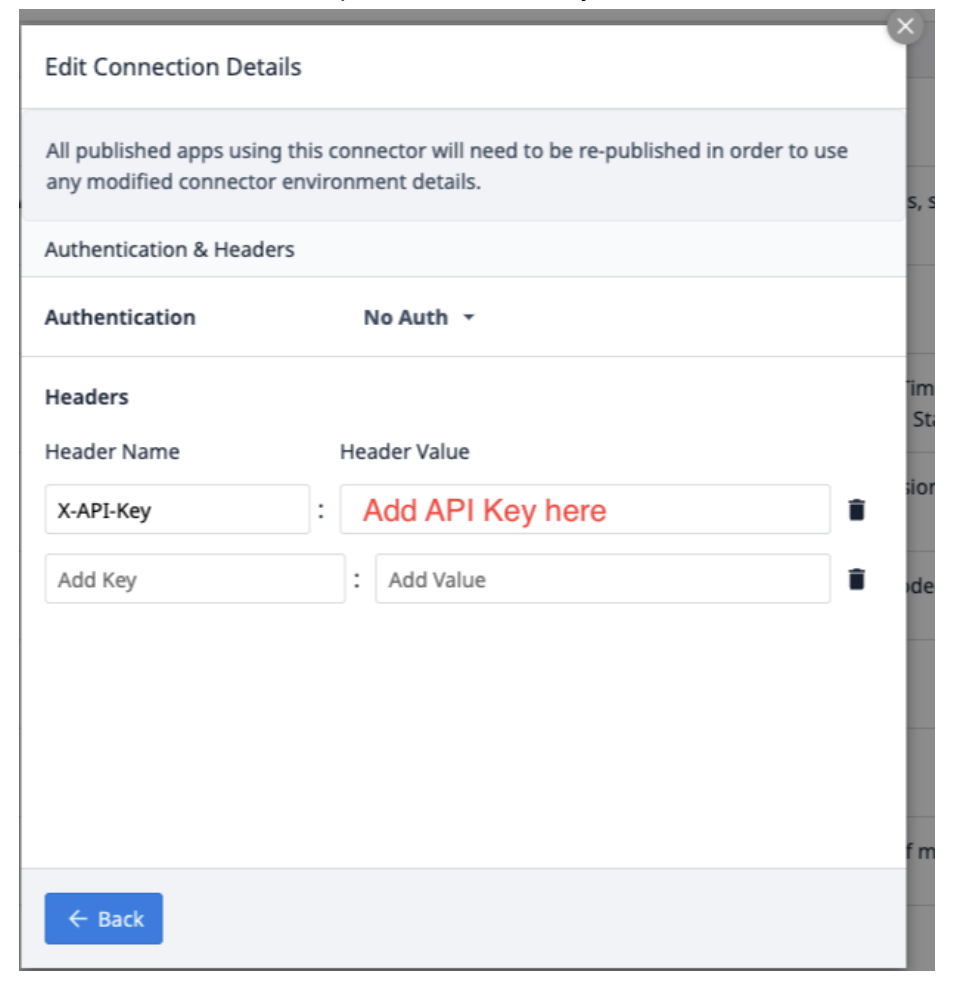
Wählen Sie Zurück und klicken Sie dann auf Testen.
Textract in einer Tulip-Anwendung für Key-Value-Paare (Extraktion aus einem PDF)
In diesem Beispiel wird gezeigt, wie Textract in einer Anwendung verwendet werden kann, um Schlüssel-Wert-Paare aus einem PDF-Dokument zu erhalten. Sie müssen eine Konnektorfunktion im AWS-Konnektor erstellen und konfigurieren sowie eine Triggerlogik verwenden , um den Konnektor auszuführen und die gewünschten Daten zu extrahieren.
Details zur Connector-Funktion
Erstellen Sie eine neue Connector-Funktion im AWS-Connector. Verwenden Sie die folgenden Informationen, um die Inputs und Outputs festzulegen.
Inputs File_url (Text) - URL der in Tulip hochgeladenen PDF-Datei Start_page (Int) - die erste Seite in der PDF-Datei, aus der extrahiert werden soll End_page (Int) - die letzte Seite in der PDF-Datei, aus der extrahiert werden soll
OutputResults (Objects) - eine Objektliste mit Schlüssel- und Wertepaaren.
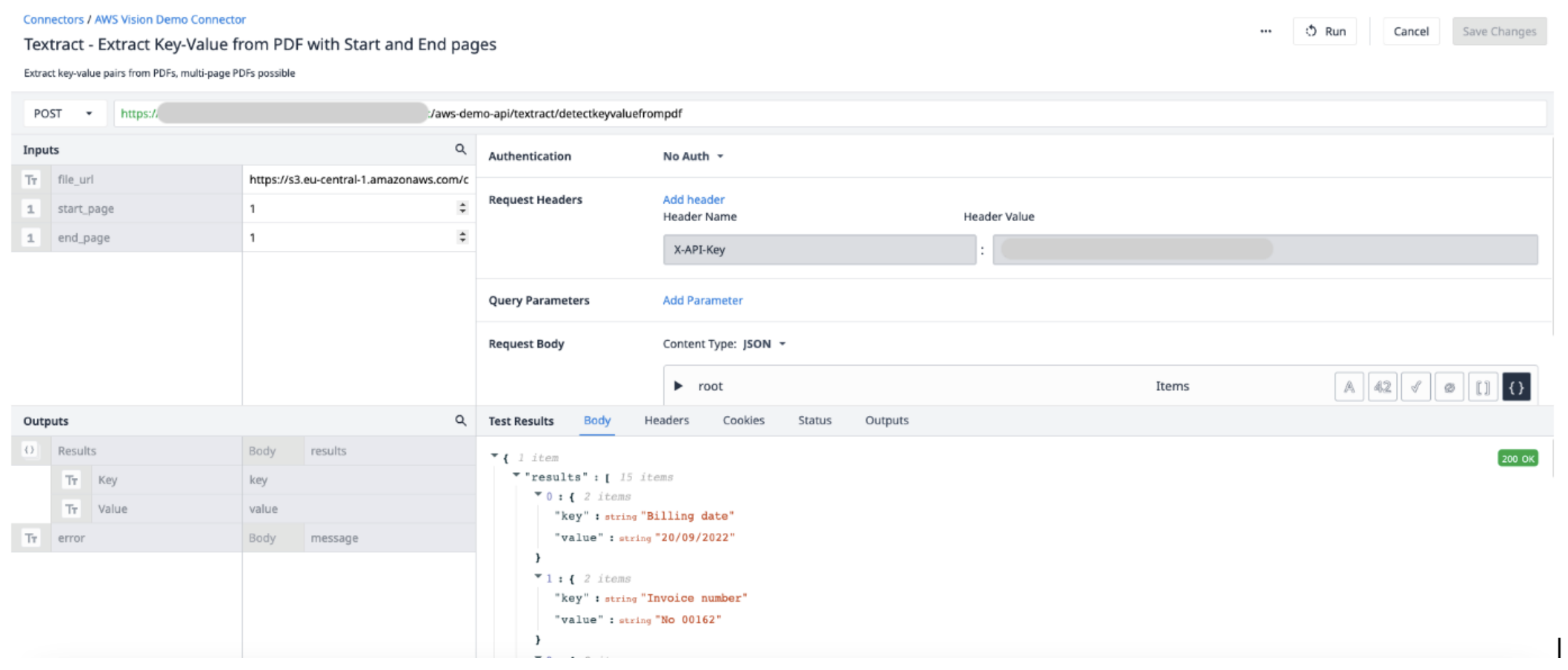
Anwendungs-Trigger
In Ihrer Anwendung werden die Trigger die Konnektorfunktion zur Ausführung aufrufen.
Erstellen Sie einen neuen Trigger mit den folgenden Aktionen:
- Führen Sie den URL Signing Connector mit der Funktion Sign URL aus. Die Dateieingabe sollte eine Textvariable sein. Verwenden Sie den Ausdruck FILETOTEXT (variable.File), wobei "File" der Name der Variablen ist, um den Dateinamen in einen Textstring zu konvertieren. Speichern Sie die Ausgabe in einer Variablen und benennen Sie sie ("SignedURL").
- Führen Sie die Konnektorfunktion AWS Textract Key-Value Pairs mit der signierten URL-Eingabe (file_url) sowie den Anfangs- und Endseiten der zu extrahierenden PDF-Datei aus. Speichern Sie die Ausgabe in einem neuen Array.
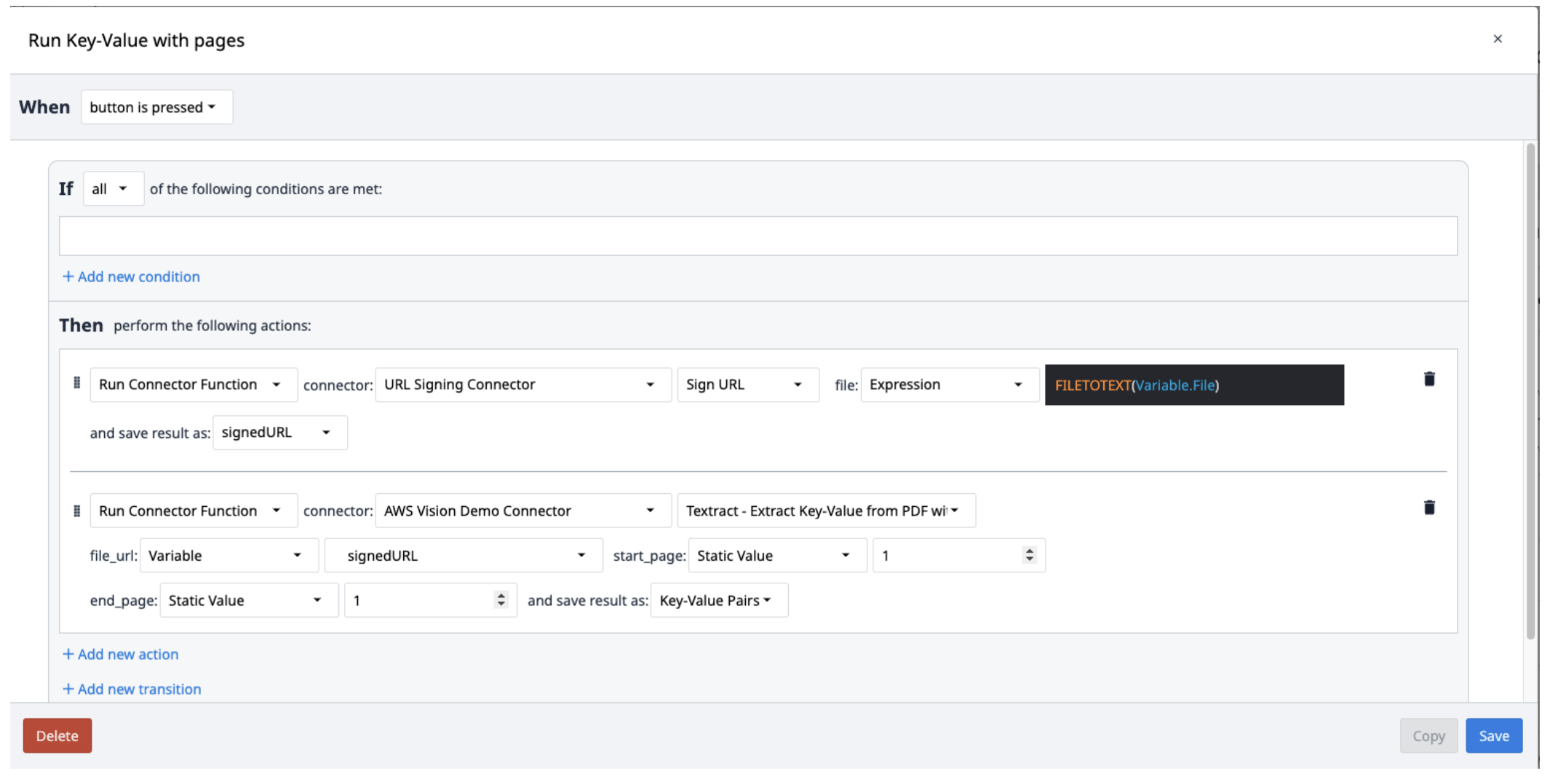
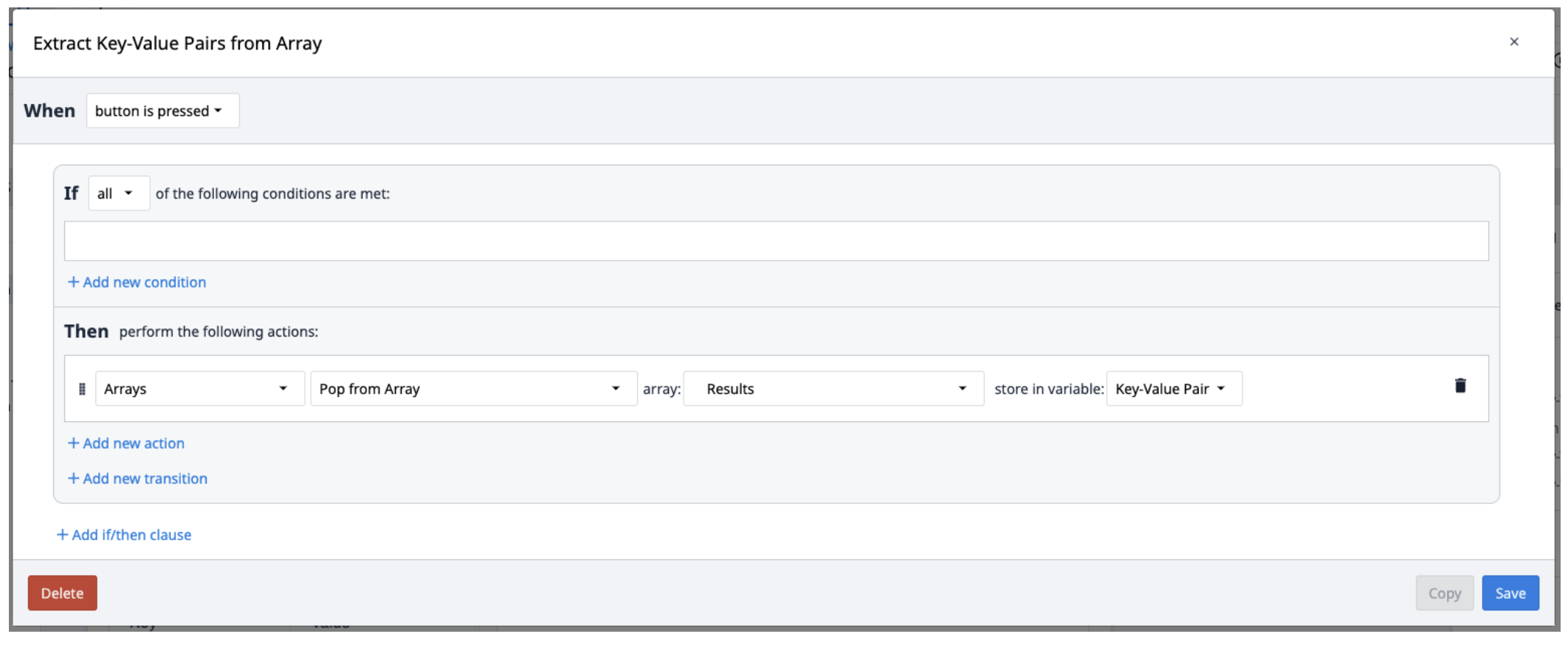
Die Textract-Ergebnisse werden in einem Array von Objekten gespeichert, die Schlüssel-Wert-Paare enthalten. Um sie aus dem Array zu extrahieren, erstellen Sie einen neuen Trigger, der die Paare nach Bedarf wiederholt aus dem Array ausliest.
Sie können das Looping Customer Widget verwenden, um mehrere Objekte aus dem Array zu entnehmen.
Textract in einer Tulip-Anwendung zur Abfrage (Extraktion aus einer PDF-Datei)
In diesem Beispiel wird gezeigt, wie Textract in einer Anwendung zur Abfrage von Daten aus einer PDF-Datei verwendet werden kann. Sie müssen eine neue Konnektor-Funktion im AWS-Konnektor erstellen und konfigurieren sowie eine Trigger-Logik verwenden , um den Konnektor auszuführen. Die Abfrage von Daten ermöglicht es Ihnen, die empfangenen Daten zu verstehen oder zu ändern.
Details zur Connector-Funktion
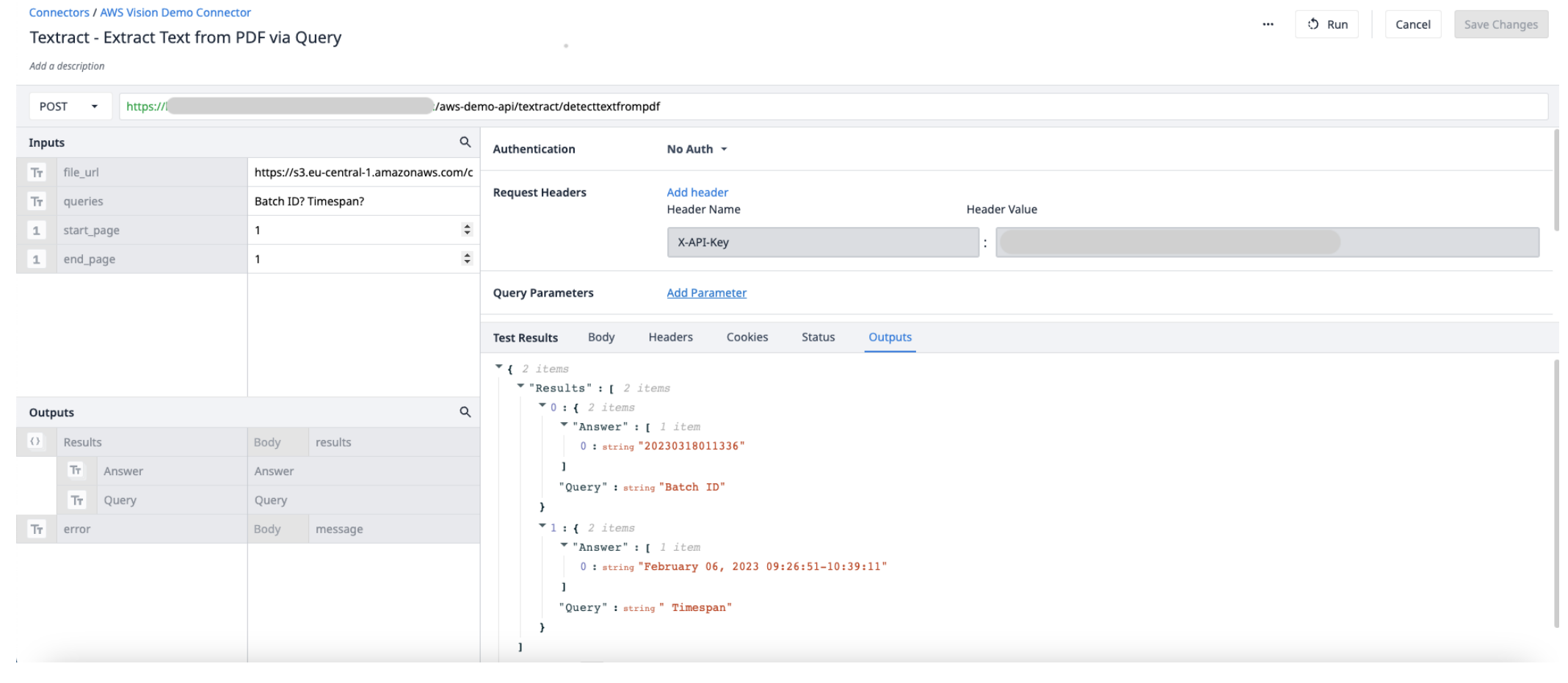
Erstellen Sie eine neue Connector-Funktion im AWS Connector. Verwenden Sie die folgenden Informationen, um die {{Glossar.Input}}s und {{Glossar.Output}}s festzulegen.
Inputs File_url (Text) - URL der in Tulip hochgeladenen PDF-Datei Start_page (Int) - die erste Seite in der PDF-Datei, aus der extrahiert werden soll End_page (Int) - die letzte Seite in der PDF-Datei, aus der extrahiert werden soll
OutputResults (objects) - eine Objektliste mit Antworten und Abfragen
Anwendungs-Trigger
In Ihrer Anwendung werden die Trigger die Konnektorfunktion zur Ausführung aufrufen.
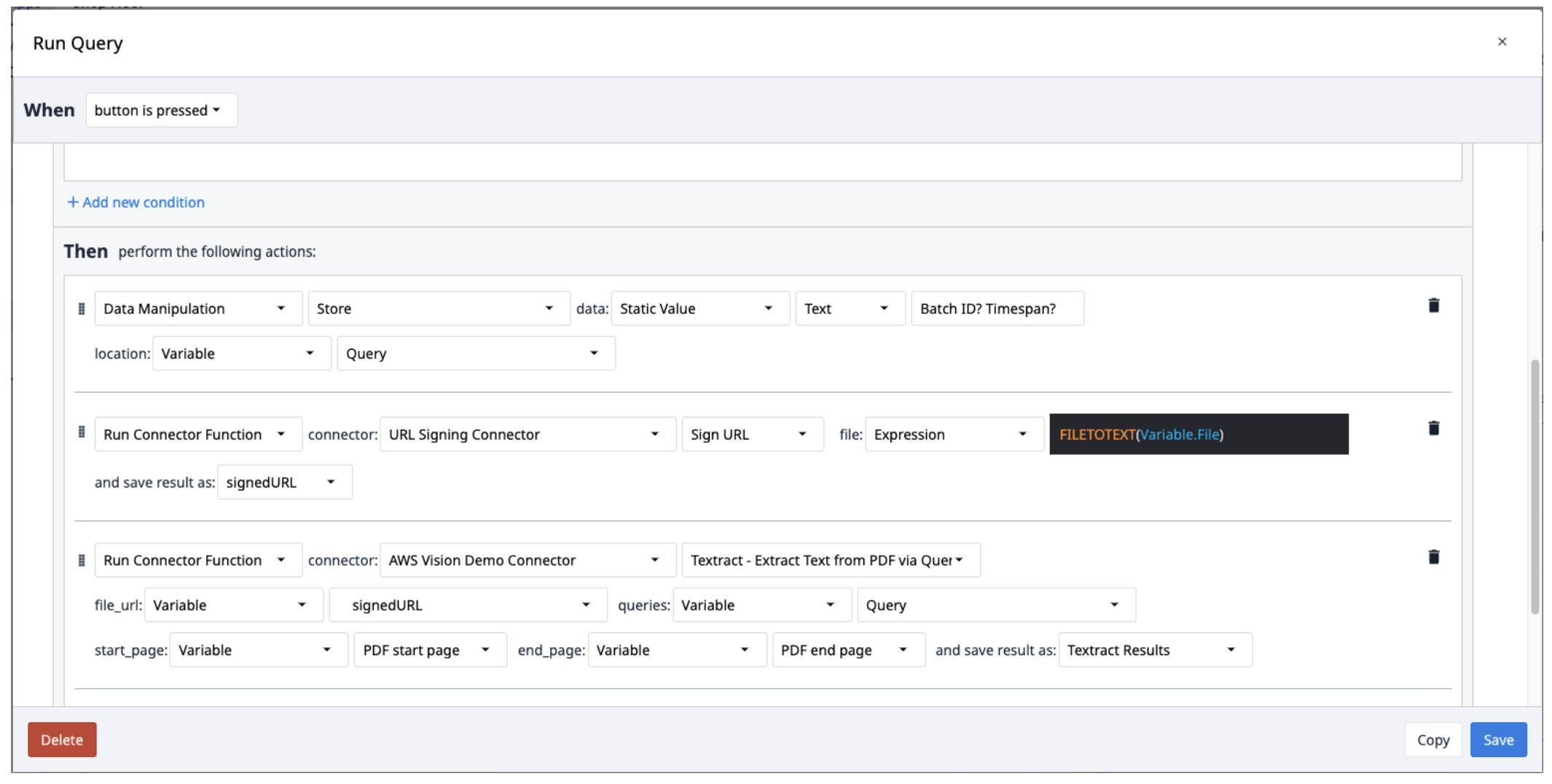
Erstellen Sie einen neuen Trigger mit den folgenden Aktionen:
- Speichern Sie die Abfragen in einer Textvariablen, getrennt durch Fragezeichen (?).
- Führen Sie den URL Signing Connector mit der Funktion Sign URL aus. Die Dateieingabe sollte eine Textvariable sein. Verwenden Sie den Ausdruck FILETOTEXT (variable.File), wobei "File" der Name der Variablen ist, um den Dateinamen in eine Textzeichenfolge zu konvertieren. Speichern Sie die Ausgabe in einer Variablen und benennen Sie sie ("SignedURL").
- Führen Sie AWS Textract aus, indem Sie Text aus einer PDF-Datei über die Query-Connector-Funktion mit der signierten URL-Eingabe (file_url), der Queries-Variable und den Anfangs- und Endseiten der PDF-Datei extrahieren. Speichern Sie die Ausgabe in einem neuen Array.
Haben Sie gefunden, wonach Sie gesucht haben?
Sie können auch auf community.tulip.co Ihre Frage stellen oder sehen, ob andere mit einer ähnlichen Frage konfrontiert wurden!
War dieser Artikel hilfreich?