

In diesem Leitfaden erfahren Sie:- Wann man Daten in Tulip und wann in einem externen System speichern sollte- Wie man Daten aus anderen Systemen bezieht- Was man für die Integration eines Systems in Tulip benötigt
Operationen beziehen oft Daten aus mehreren Quellen, in Tulip und extern. Für externe Datenquellen müssen Sie eine Verbindung über Tulip herstellen.
Establishing secure data connections may require IT personnel.
Wann speichert man Daten in Tulip und wann in einem externen System?
In Tulip können Sie Daten an zwei Stellen speichern:
- In den Tabellen
- Abschlüsse
Tulip-Daten (z.B. Prozessdaten, Arbeitsanweisungen, Betriebsmittel) werden direkt aus Ihren digitalen Vorgängen aktualisiert.
Aber was ist mit Daten, auf die Sie in der Produktion Bezug nehmen und die anderswo gespeichert sind? Dazu können gehören:
- ERP/WMS-Systeme
- Ältere MES
- Datenbanken
- PLM (z. B. für Stücklisten)
- Qualitätsmanagement-System (QMS)
Sie können mit externen Daten auf verschiedene Weise interagieren, je nachdem, wofür Sie die Daten verwenden (z. B. Lesen und Schreiben von Daten in eine API/SQL-Datenbank oder Anzeigen von Managementdaten als Produktionsreferenz).
Eine einzige Wahrheitsquelle ist eine wesentliche Komponente für genaue Echtzeitdaten. Eine einzige Wahrheitsquelle stellt sicher, dass Daten nicht doppelt oder an mehreren Stellen dargestellt werden.
Sowohl Tulip-Daten als auch externe Daten sind entsprechende Wahrheitsquellen, und keine von beiden sollte ersetzt oder repliziert werden:- Ein externes System liefert klare Anforderungen, Geschäftsmetriken oder Kundendaten für den digitalen Workflow-Kontext- Tulip-Daten enthalten Betriebs- und Prozessdaten für Echtzeitberichte
Dieses Diagramm zeigt die Trennung von Daten aus Tulip und einem ERP: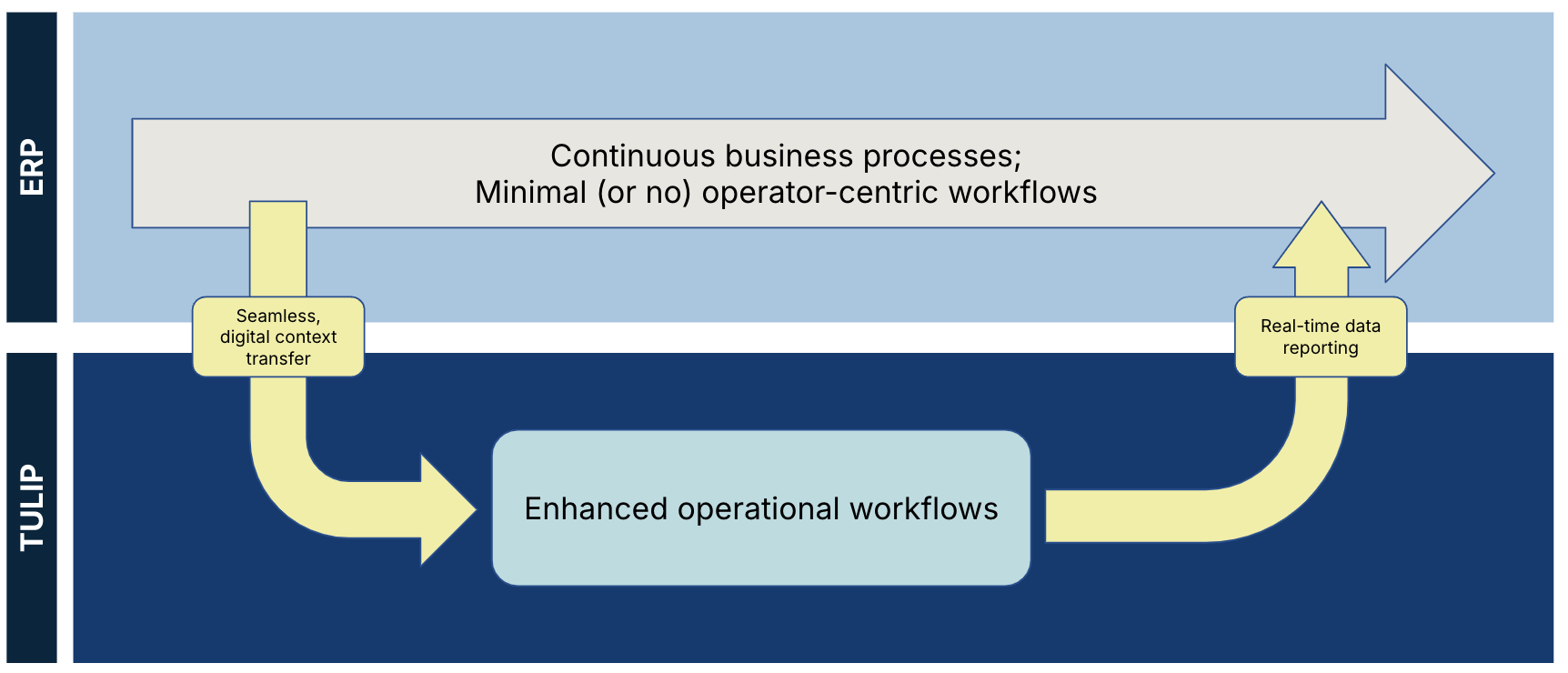
Sie sollten Daten aus externen Quellen nur bei Bedarf verwenden. Diese Praxis bedeutet, dass ein anderes System kontextuelle Informationen für die Produktion liefern kann, während Tulip-Daten die Informationen aus einer externen Quelle ergänzen.
Woher wissen Sie, ob Sie externe Daten verwenden sollten?- Erhalten Sie einen minimalen Wert aus der Lösung ohne Integration?- Können Sie die Integration schnell durchführen (weniger als einen Monat)?
Integrationen sollten eine Reihe von Werten freisetzen, sind aber in der Regel für den potenziellen Wert nicht unbedingt erforderlich.
Beispiel: Arbeitsaufträge aus einem ERP
- Arbeitsaufträge werden in einem ERP gespeichert
- Eine Tulip-Management-App holt den Arbeitsauftrag aus dem ERP
- Die Management-App erstellt einen Datensatz des Arbeitsauftrags in einer Tulip-Tabelle, um Produktionsdaten zu speichern
- Arbeitsanweisungen und Montage-Apps erfassen Produktionsdaten in der Arbeitsauftragstabelle und konforme Prozessdaten in Abschlüssen
Offenes Ökosystem
Ein offenes Ökosystem nutzt mehrere, miteinander verbundene Lösungen, um die individuellen Anforderungen eines Unternehmens zu erfüllen. Anstatt ein einziges System für alles zu verwenden, priorisiert der offene Ökosystem-Ansatz von Tulip die Composability gegenüber der Top-down-Kontrolle.
Das unten stehende Diagramm zeigt, wie die digitalen Möglichkeiten von Tulip mit anderen Systemen integriert werden.
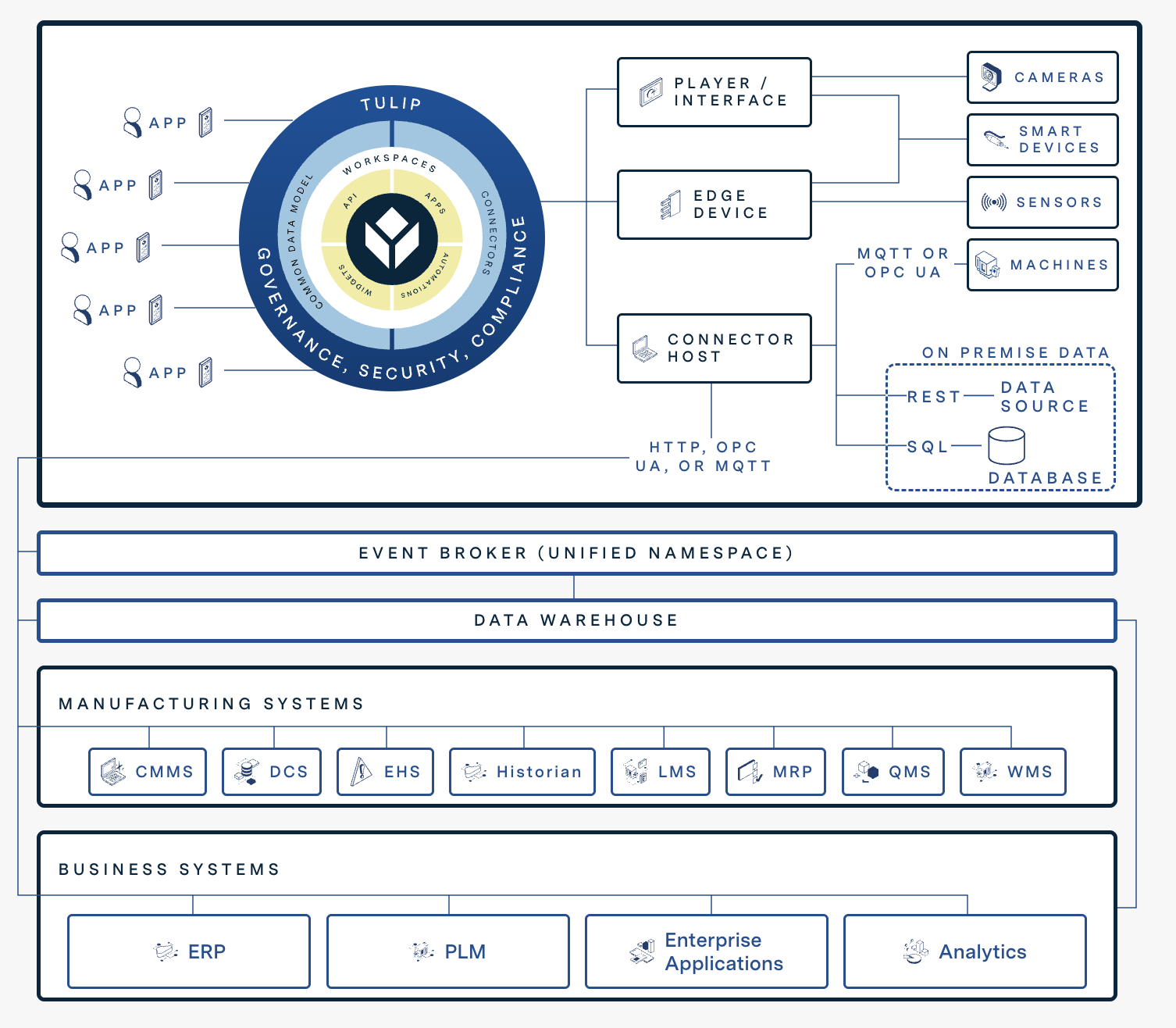
System-Integration
Systemintegrationen müssen in der Regel nicht der erste Schritt bei der Implementierung sein. Tulip empfiehlt Ihnen, zunächst Ihr minimal wertvolles Produkt ohne Systemintegration zu bauen und dann nach Bedarf Anpassungen vorzunehmen. Der Grund dafür ist, dass die Einrichtung von Systemintegrationen bis zu mehreren Monaten dauern kann.
Bei einer Systemintegration mit Tulip spielen in der Regel 3 Faktoren eine Rolle:- die Fähigkeiten und Parameter des Systems selbst- die Komplexität der IT-Umgebung Ihres Unternehmens- die Fähigkeiten Ihres IT-Teams für die Arbeit mit dem System
Bei der Integration geht es nicht um alles oder nichts - Sie sollten sich darauf konzentrieren, die minimalen Daten zu definieren, die benötigt werden, um einen operativen Kontext in einer App zu liefern.
Das folgende Diagramm zeigt eine typische ERP-Integration mit Tulip: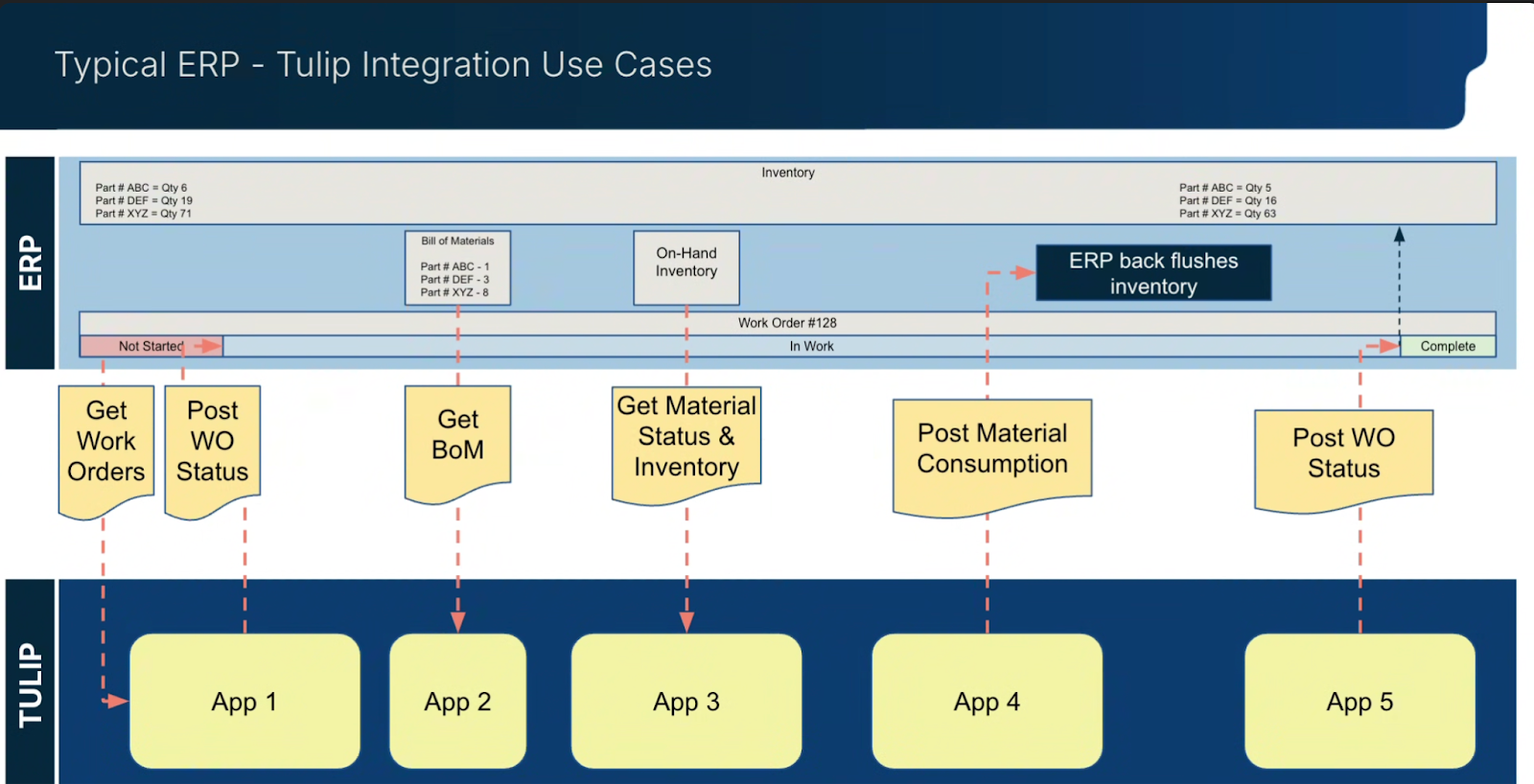
Erfahren Sie hier mehr darüber, wie man eine Integration plant.
Datenfluss der Integration
Die Art und Weise, wie Tulip mit einem externen System "spricht", ist wie folgt aufgebaut:* Ein Connector verwendet sichere Parameter, um "Zugang" zum System zu erhalten* Eine Connector-Funktion befiehlt die Informationen zum/vom System* Eine Trigger-Aktion (erstellt im App-Editor) führt die Connector-Funktion aus (z.B. beim Drücken einer Taste)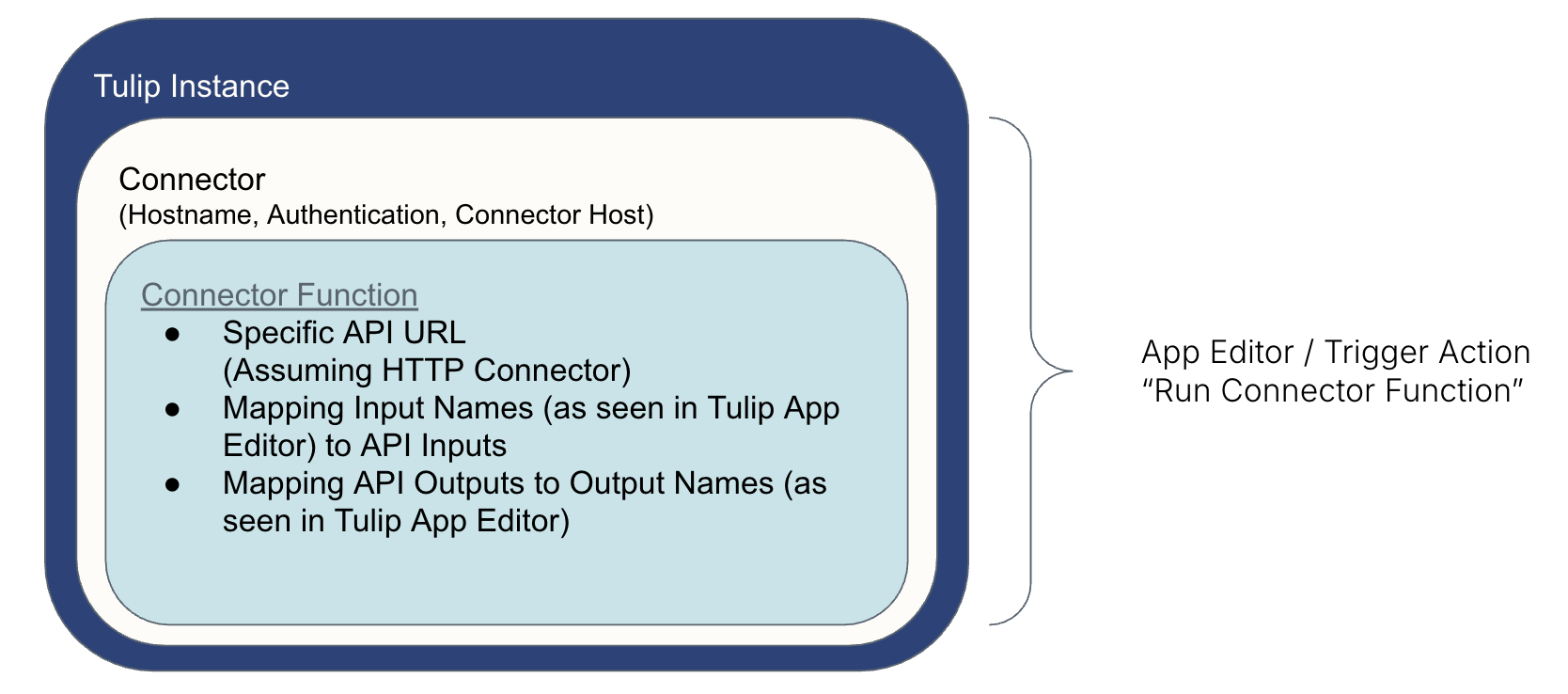
Wie stellt man eine Verbindung zu einem System her?
Schauen wir uns die Funktionen an, die diese Verbindungen möglich machen.
Konnektoren
Konnektoren sind der Rahmen von Tulip für die Erstellung von Verbindungen zwischen Tulip und Systemen von Drittanbietern. Sie sind leistungsstarke Integrationen zum Anzeigen, Verwalten und Interagieren mit Daten aus externen Systemen in Anwendungen.
Wofür man Konnektoren verwendet
Konnektoren sind die Art und Weise, wie Tulip mit externen Systemen kommuniziert. Die Werkzeuge in Ihrem Stack und der Grad der Integration, der in Ihren Anwendungen erforderlich ist, bestimmen, wie Sie Konnektoren verwenden.
Einige Anwendungsfälle für Konnektoren sind:* Abrufen von Informationen aus einer Quelle der Wahrheit (z.B. Arbeitsaufträge aus Ihrem ERP)* Verbuchen von Materialverbrauch (z.B. in Ihrem ERP)* Senden einer Slack-Nachricht
Wie Konnektoren funktionieren
Konnektoren stellen eine Verbindung zwischen Tulip und einem Fremdsystem her. Sie sorgen für die Richtung und die Authentifizierung, so dass Daten ausgetauscht werden können.
Die Transaktion von Daten wird durch einen Connector Host ermöglicht. Connector Hosts ermöglichen es Tulip, sich mit externen Systemen zu verbinden, indem sie als direkte Verbindung zwischen den beiden fungieren. Tulip stellt einen Cloud Connector Host zur Verfügung, aber Sie können auch einen On-Premise Connector Host verwenden.
Mehr über Connector Hosts erfahren Sie hier.
Während der Connector-Host die Verbindung herstellt, sorgen die Connector-Funktionen dafür, dass Ihre Konnektoren Dinge wie das Abrufen von Informationen, das Schreiben in Tabellen und das Bearbeiten vorhandener Daten tun. Connector-Funktionen fordern Aktionen vom Drittsystem an, die über den Connector-Host laufen.
Sie können auch Änderungen an Ihrer Funktion vornehmen, wie Abfrageparameter und Antworten, die die zurückgegebenen Daten bestimmen. Während Vorkenntnisse über JSON nicht erforderlich sind, sind Kenntnisse über Aspekte wie Dot Notation und die allgemeine Datenstruktur nützlich, um Ihre Konnektorfunktionen besser zu verstehen.
Arten von Konnektoren
Um die verschiedenen Systeme zu verstehen, mit denen Sie sich verbinden können, ist es wichtig zu wissen, dass es drei verschiedene Arten von Konnektoren gibt, die Informationen aus verschiedenen Quellen extrahieren:
HTTP
HTTP-Konnektoren greifen auf Daten von externen APIs zu. Sie sind die am häufigsten verwendeten Konnektoren. HTTP-Konnektoren können mit den meisten Arten von HTTP-APIs verbunden werden, einschließlich REST und SOAP.
HTTP-Konnektor-Funktionen können die folgenden Arten von API Call ausführen:
- GET
- HEAD
- POST
- PUT
- BATCH
- DELETE
SQL
SQL-Konnektoren greifen auf Daten aus externen Datenbanken zu. Mit einem SQL-Konnektor können Sie Tabellendaten ändern, Daten abrufen und einen bestehenden Datensatz manipulieren.
Tulip unterstützt die folgenden SQL-Konnektoren:
- Microsoft SQL Server
- PostgreSQL
- MySQL
- Oracle
Zugriff auf HTTP- und SQL-Konnektoren über die Seite Konnektoren in Ihrer Instanz.
MQTT
Verbinden Sie sich mit MQTT-Brokern für die Maschinenüberwachung. Tulip kann Daten aus seinem Produkt nativ an Ihren MQTT-Broker veröffentlichen und sich so nahtlos in einen Unified Namespace oder einen Enterprise Event Bus integrieren.
Die folgenden Felder können für eine MQTT-Connector-Funktion definiert werden:- Quality of Service- Topic- Retain Message- Payload- User Defined Inputs
Edge-Konnektivität
Einige dieser Geräte umfassen Edge Devices, über die Sie hier mehr erfahren können:
Tabelle API
Mit Hilfe von Konnektoren kann eine Tulip-Anwendung eine HTTP- oder SQL-Abfrage initiieren. Mit der Tulip-API können Sie mit Tulip kommunizieren und Tulip aus externen Systemen integrieren. Diese API funktioniert, indem sie Daten aus einem anderen System in Tulip bringt und es Ihnen ermöglicht, in diese anderen Systeme zu schreiben. Die Tabellen-API hat verschiedene Möglichkeiten, darunter:* Aktualisieren eines Tabellendatensatzes* Erstellen einer Tabelle* Suchen der Anzahl der Tabellendatensätze
Die Tulip API funktioniert derzeit nur mit Tulip-Tabellen. Um die Tabellen-API nutzen zu können, müssen Sie ein grundlegendes Verständnis für die Funktionsweise von APIs haben.
Die Tulip API-Dokumentation finden Sie hier.
Um die Verwendung der Tabellen-API zu üben, besuchen Sie den Tulip University Kurs: Vertiefung der Funktionen: Tabellen-API.
Nächste Schritte
Erfahren Sie mehr über Integrationen und beginnen Sie mit der Verbindung:* Wie man einen Connector erstellt* Wie man Quick Connectors einrichtet
Haben Sie gefunden, wonach Sie gesucht haben?
Auf community.tulip.co können Sie Ihre Frage stellen oder sehen, ob andere eine ähnliche Frage hatten!