Streamline fetching data from Tulip to AWS for broader analytics and integrations opportunities
Purpose
This guide walks through step by step how to fetch Tulip Tables data AWS via a Lambda function.
The lambda function can be triggered via a variety of resources such as Event Bridge timers or an API Gateway
An example architecture is listed below:
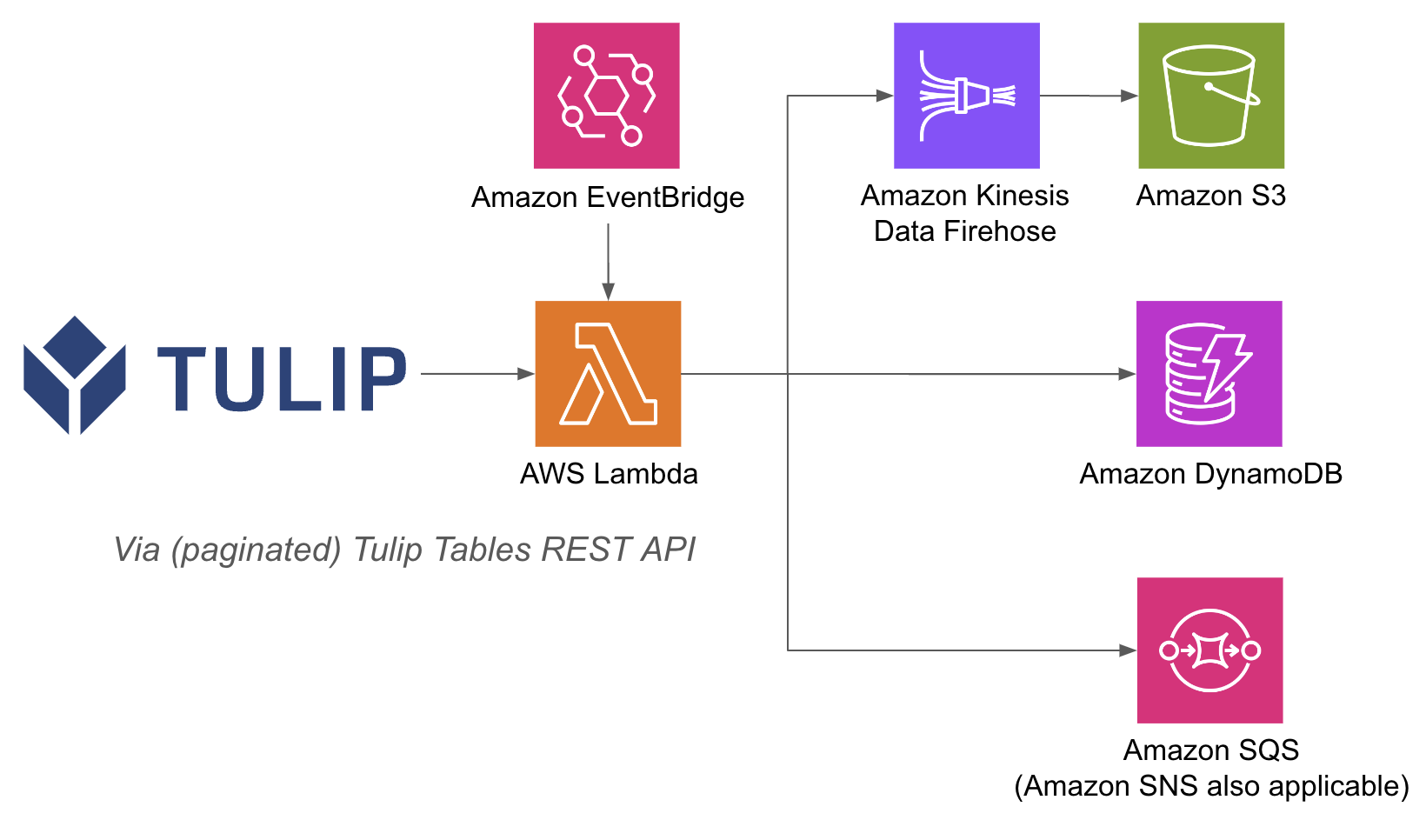
Performing AWS operations inside of a lambda function can be easier, because with API Gateway and Lambda functions, you don't need to authenticate databases with username and password on the Tulip side; you can rely on the IAM authentication methods inside of AWS. This also streamlines how to leverage other AWS services such as Redshift, DynamoDB, and more.
Setup
This example integration requires the following:
- Usage of Tulip Tables API (Get API Key and Secret in Account Settings)
- Tulip Table (Get the Table Unique ID
High-level steps:
- Create an AWS Lambda function with the relevant trigger (API Gateway, Event Bridge Timer, etc.)
- Fetch the Tulip table data with the example below
import json
import pandas as pd
import numpy as np
import requests
# NOTE the pandas layer from AWS will need
# to be added to the Lambda function
def lambda_handler(event, context):
auth_header = OBTAIN FROM API AUTH
header = {'Authorization' : auth_header}
base_url = 'https://[INSTANCE].tulip.co/api/v3'
offset = 0
function = f'/tables/[TABLE_ID]/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all'
r = requests.get(base_url+function, headers=header)
df = pd.DataFrame(r.json())
length = len(r.json())
while length > 0:
offset += 100
function = f'/tables/[TABLE_ID]/records?limit=100&offset{offset}&includeTotalCount=false&filterAggregator=all'
r = requests.get(base_url+function,
headers=cdm_header)
length = len(r.json())
df_append = pd.DataFrame(r.json())
df = pd.concat([df, df_append], axis=0)
df.shape
# this appends 100 records to a dataframe and can then be used for S3, Firehose, etc.
# use the data variable to write to S3, Firehose,
# databases, and more
- The trigger can run on a timer or triggered via a URL
- Note the Pandas layer required in the image below
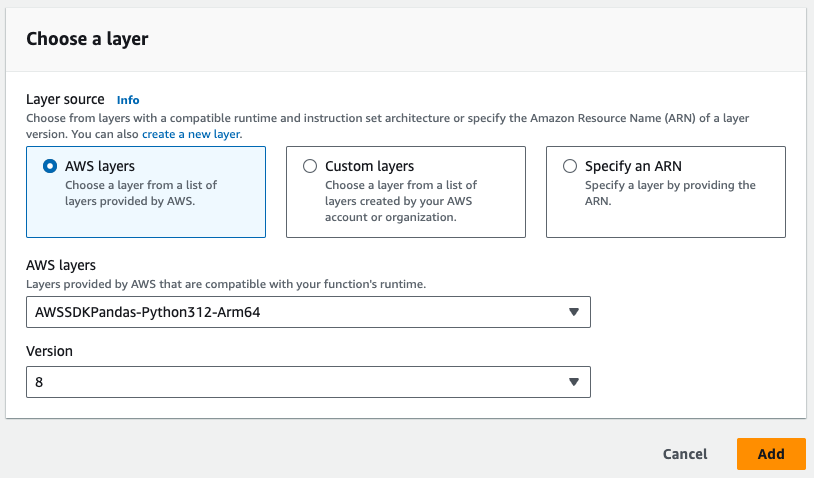
- Finally, add in whatever integrations are required. You can write the data to a database, S3, or a notification service from lambda functions
Use Cases and Next Steps
Once you have finalized the integration with lambda, you can easily analyze the data with a sagemaker notebook, QuickSight, or a variety of other tools.
1. Defect prediction
- Identify production defects before they happen and increase right first time.
- Identify core production drivers of quality in order to implement improvements
2. Cost of quality optimization
- Identify opportunities to optimize product design without impact customer satisfaction
3. Production energy optimization
- Identify production levers to optimal energy consumption
4. Delivery and planning prediction and optimization
- Optimize production schedule based on customer demand and real time order schedule
5. Global Machine / Line Benchmarking
- Benchmark similar machines or equipment with normalization
6. Global / regional digital performance management
- Consolidated data to create real time dashboards