使用 AWS Textract 的郁金香 OCR
- 31 Jan 2024
- 1 分钟阅读
- 贡献者




- 打印
使用 AWS Textract 的郁金香 OCR
- 更新于 31 Jan 2024
- 1 分钟阅读
- 贡献者
- 打印
Article Summary
Share feedback
Thanks for sharing your feedback!
:::(Warning) (注)使用Frontline Coplilot™,可直接从图像和文档中提取文本,大大简化了在 Tulip 中对图像进行 OCR 的过程。今后建议采用这种方法:
本文将指导你在 Tulip 上设置 AWS Textract 连接器。
AWS Textract 是亚马逊网络服务(AWS)提供的一项基于云的服务,它使用机器学习技术从各种类型的文档中提取文本和数据。Textract 可以分析扫描文档、PDF、图像和其他文件,自动提取文本内容、表格、表单和键值对。
AWS Textract 的主要特点和功能包括
- **光学字符识别 (OCR):**Textract 使用 OCR 从扫描的文档和图像中提取文本,即使这些文档和图像使用不同的语言或具有复杂的布局。
- 键值对提取:Textract 可从发票或收据等文档中提取键值对,方法是识别标签与其相关值之间的关系。
- 表格提取:Textract 可以从文档中检测和提取表格数据,并保留表格结构、行和列。
- 基于查询的文本提取:Textract 允许你使用自然语言查询从文档中检索特定信息。
- 支持多种文档格式:Textract 支持多种文档格式,包括 PDF、JPEG、PNG 和 TIFF。
- 表单提取(即将推出):Textract 可自动识别复选框、单选按钮和文本字段等表单字段,并提取相应数据。
前提条件
- 工作中的Tulip Vision工作站,配有用于视觉检测的摄像头
- 联系 Tulip 支持部门获取 AWS Textract 连接器和 API 密钥(Textract 应用程序即将在Tulip Library中推出)
- 为提取 PDF 文件创建一个登录 URL连接器
设置 Tulip 连接器
在你的 Tulip 实例中,从 "应用程序"菜单中选择 "连接器"。
选择AWS 连接器并确保其在线,或使用以下连接详细信息进行设置:
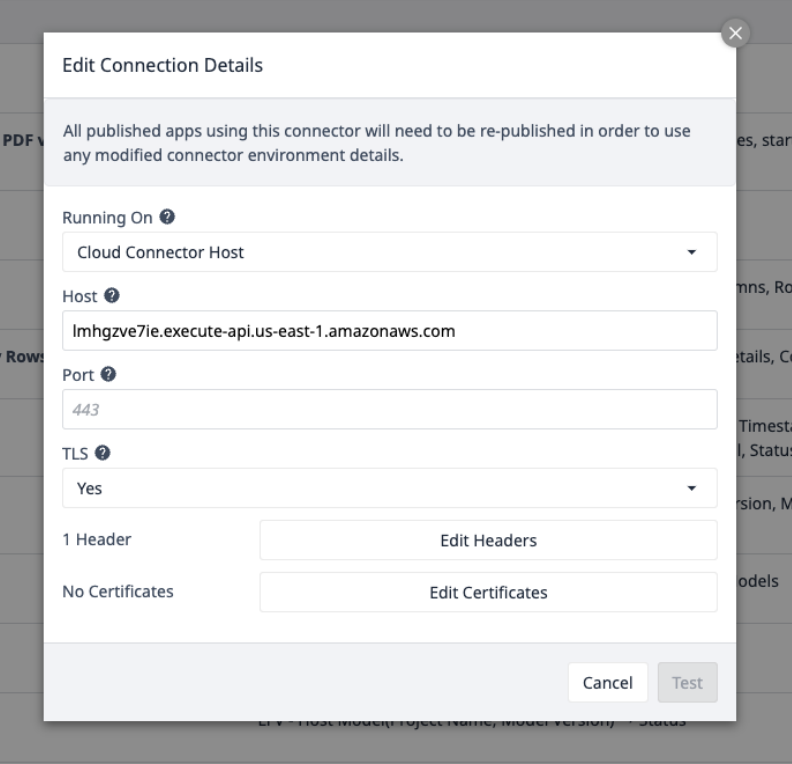
选择 "编辑标头",更新 Tulip 提供的 X-API 密钥。
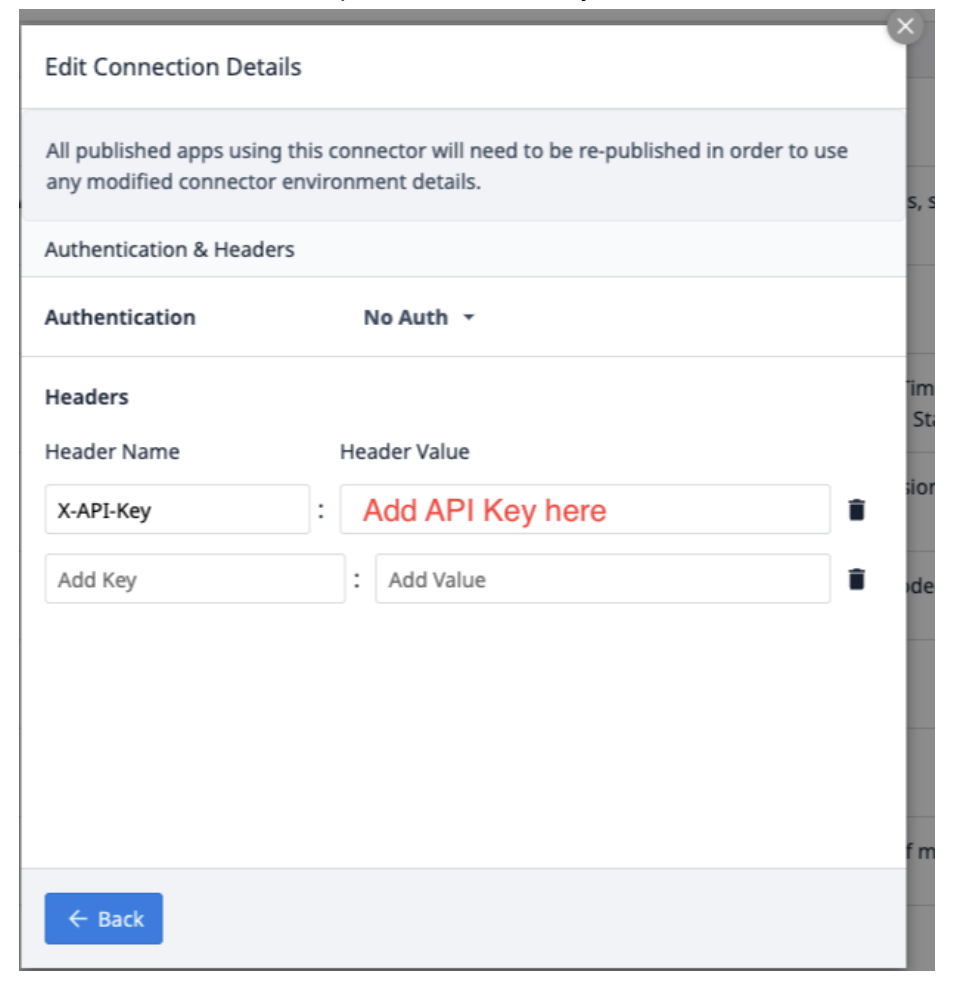
选择 "返回",然后点击 "测试"。
Tulip 应用程序中的键值对 Textract(从 PDF 中提取)
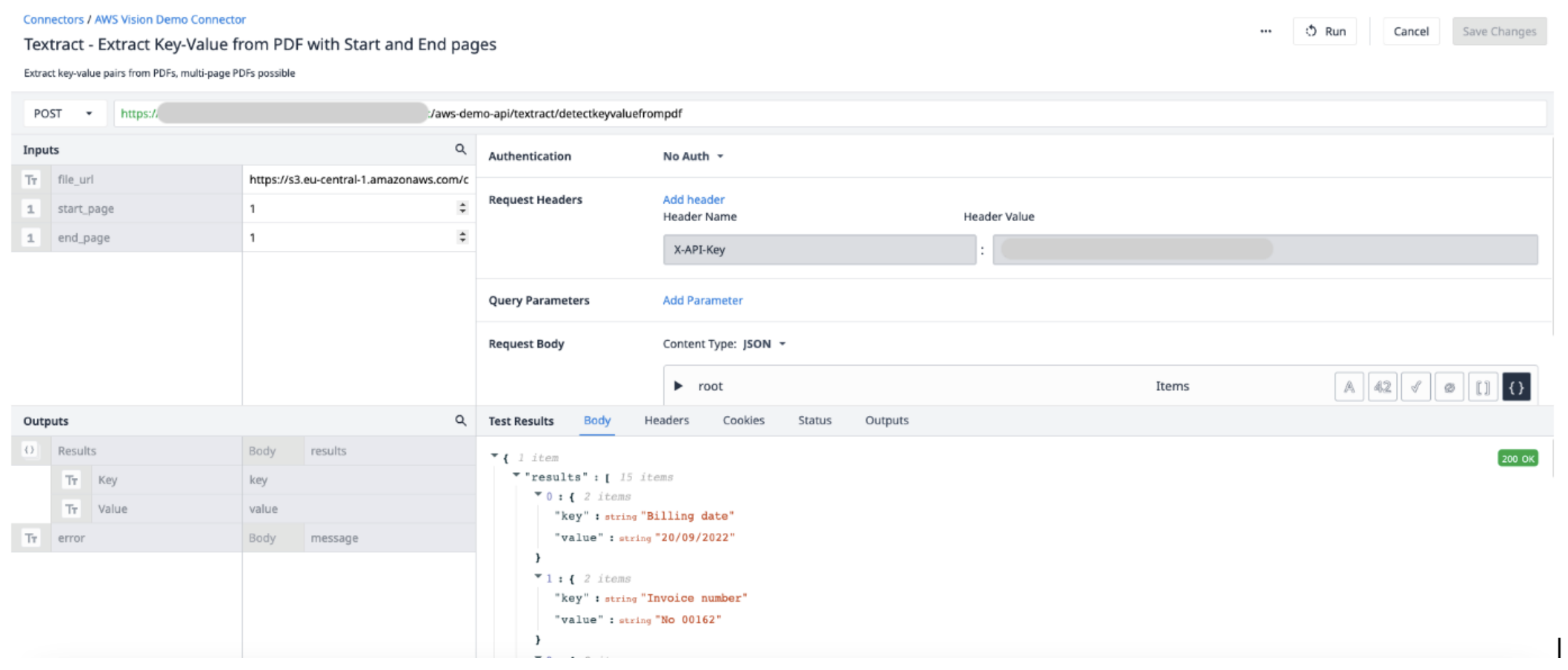
在本示例中,我们将演示如何在应用程序中使用 Textract 从 PDF 中获取键值对。您需要在 AWS 连接器中创建和配置一个连接器函数,并使用触发逻辑来运行连接器并提取我们想要的数据。
连接器函数详细信息
在 AWS 连接器中创建一个新的连接器函数。使用以下信息设置 Input 和 Output。
输入File_url(文本)-- 上传到郁金香的 PDF 文件的 URL Start_page(Int)-- 要提取的 PDF 文件的第一页 End_page(Int)-- 要提取的 PDF 文件的最后一页
输出结果(对象) - 包含键和值对的对象列表。
应用程序触发器
在应用程序中,触发器将调用连接器函数来运行。
创建具有以下操作的新触发器:
- 使用 Sign URL 功能运行 URL 签名连接器。文件输入应为文本变量。使用 FILETOTEXT (variable.File) 表达式,其中 "File "为变量名,将文件名转换为文本字符串。将输出保存到一个变量并命名为("SignedURL")。
- 运行 AWS Textract Key-Value Pairs 连接器函数,输入签名 URL (file_url),以及要提取的 PDF 的起始页和结束页。将输出保存到一个新数组。
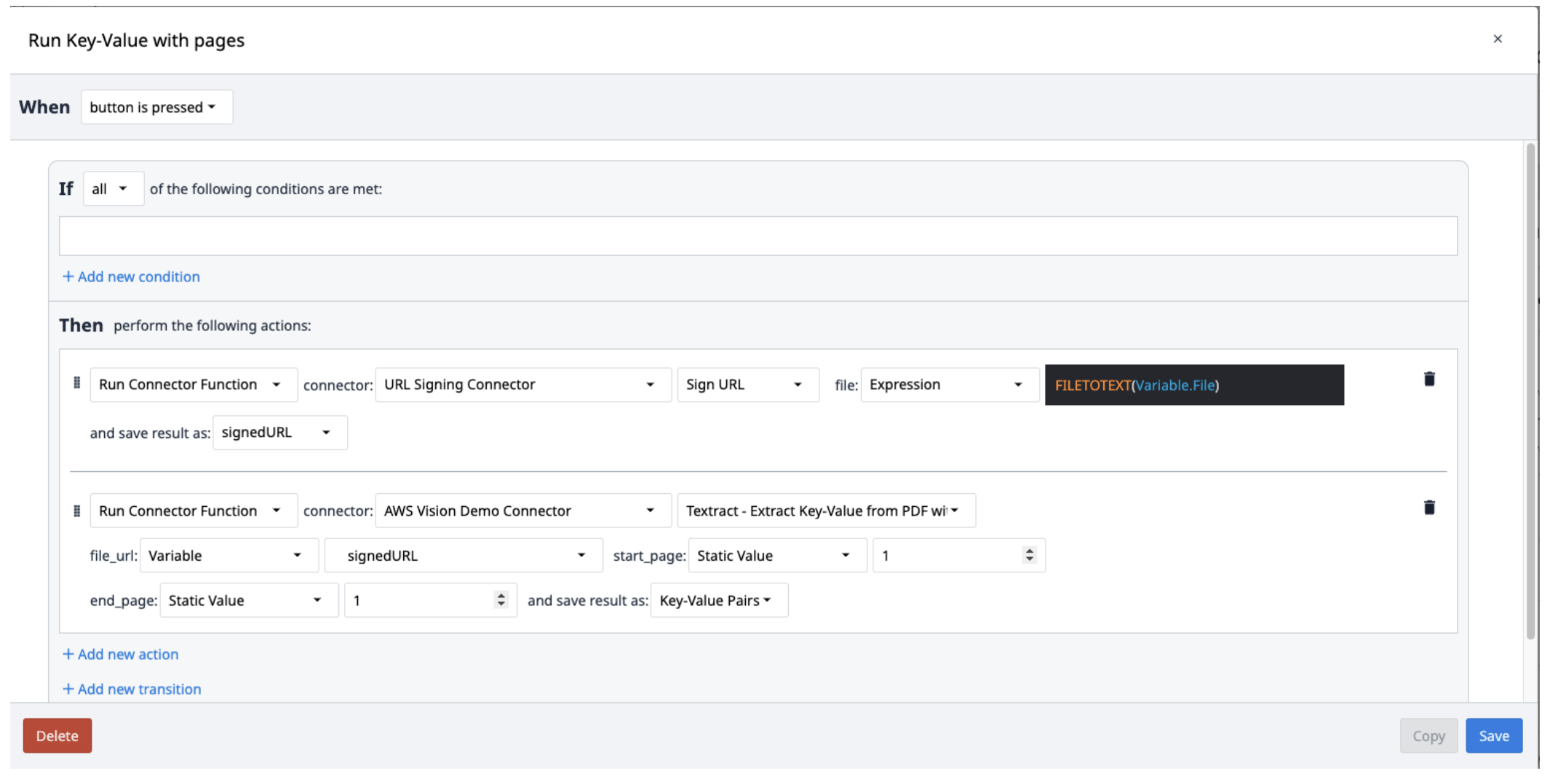
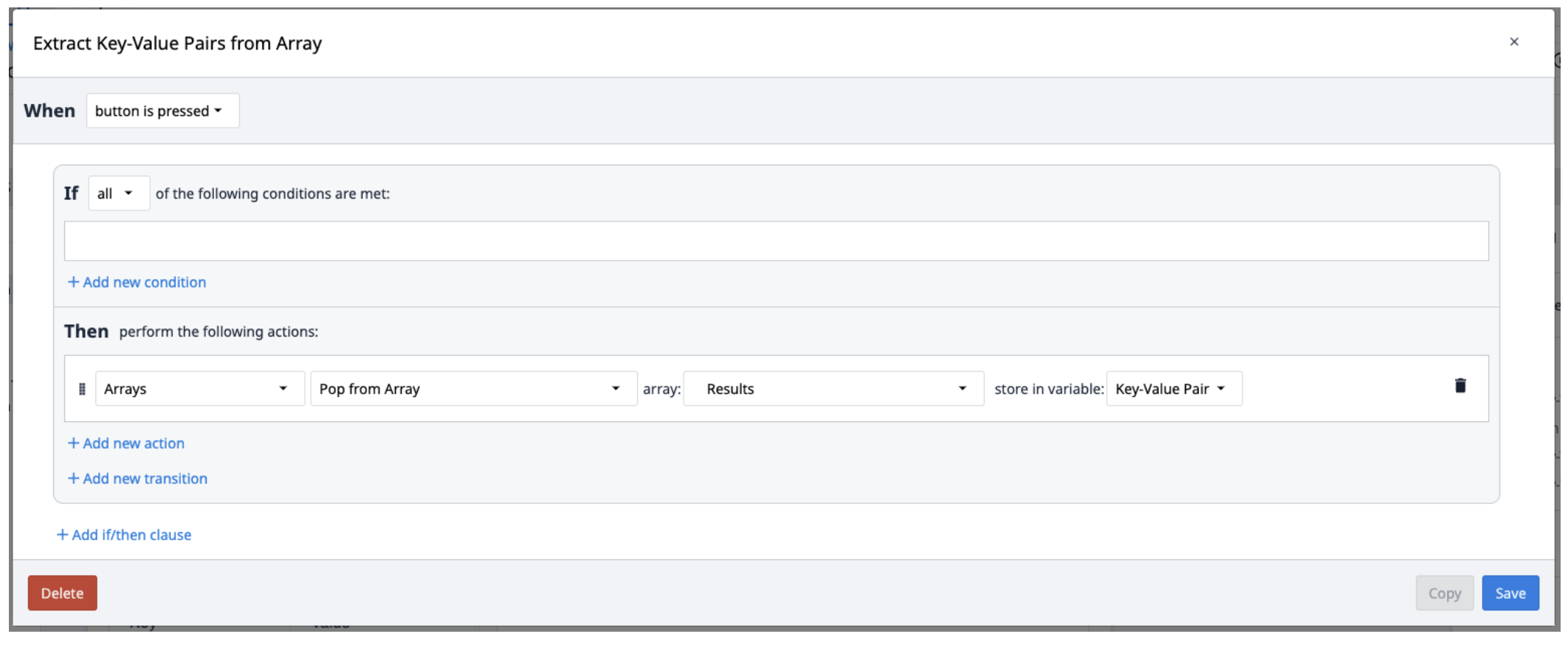
Textract 结果保存在包含键值对的对象数组中。要从数组中提取这些结果,需要创建一个新的触发器,根据需要从数组中重复弹出键值对。
你可以考虑使用循环客户小工具,从数组中弹出多个对象。
在郁金香应用程序中使用 Textract 进行查询(从 PDF 中提取)
在本示例中,我们将演示如何在应用程序中使用 Textract 查询从 PDF 中提取的数据。您需要在 AWS 连接器中创建和配置一个新的连接器函数,并使用触发逻辑运行连接器。通过查询数据,您可以了解或更改接收到的数据。
连接器函数详细信息
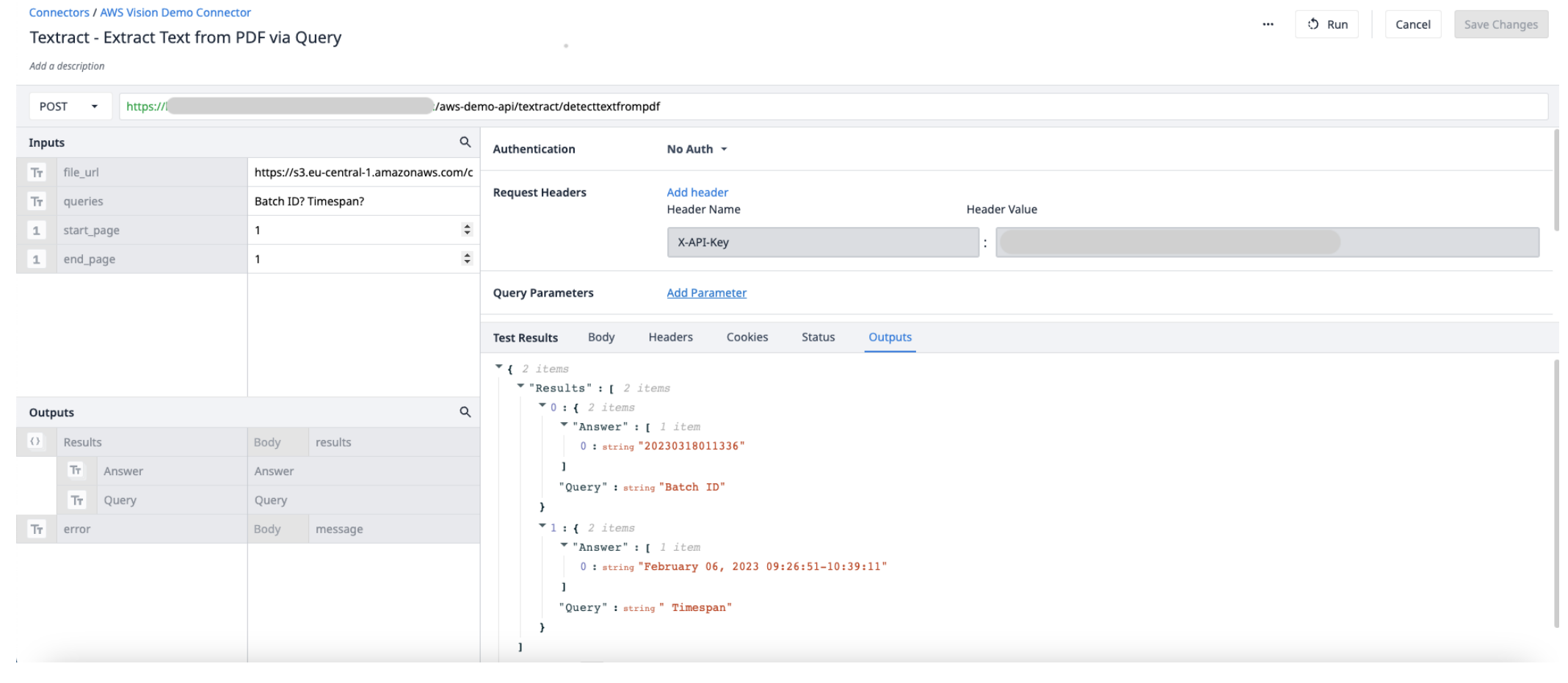
在 AWS 连接器中创建一个新的连接器功能。使用以下信息设置 Inputs 和 Outputs 。
输入File_url(文本)-- 上传到郁金香的 PDF 文件的 URL Start_page(Int)-- 要提取的 PDF 文件的第一页 End_page(Int)-- 要提取的 PDF 文件的最后一页
输出结果(对象) - 答案和查询的对象列表
应用程序触发器
在应用程序中,触发器将调用连接器函数运行。
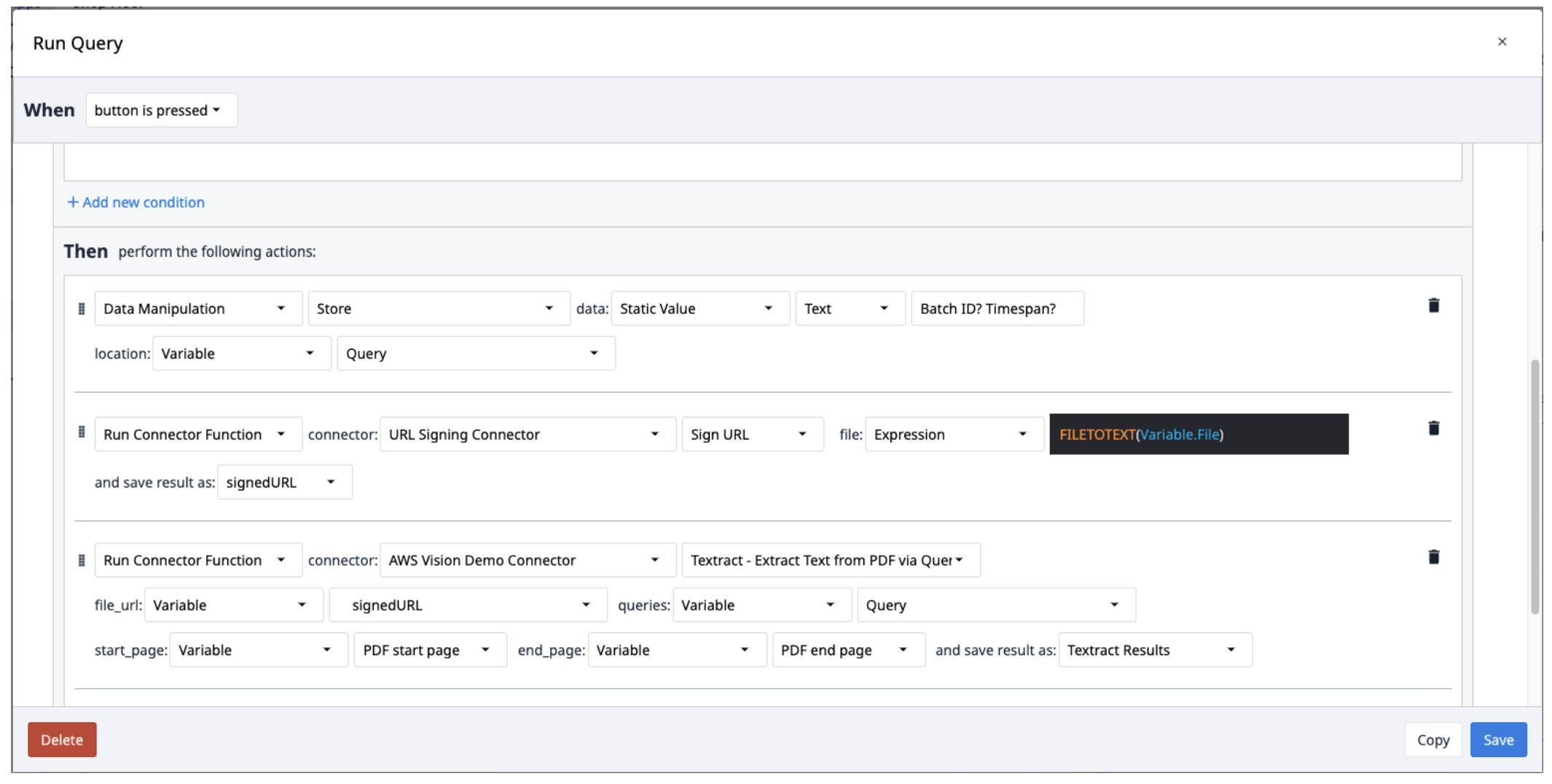
创建具有以下操作的新触发器:
- 将查询保存到一个文本变量中,用问号(?)分隔。
- 使用 Sign URL 功能运行 URL 签名连接器。文件输入应为文本变量。使用 FILETOTEXT (variable.File) 表达式,其中 "File "为变量名,将文件名转换为文本字符串。将输出保存到变量并命名为 "SignedURL"。
- 运行 AWS Textract,通过查询连接器函数从 PDF 中提取文本,并输入签名 URL(file_url)、查询变量以及 PDF 的起始页和结束页。将输出保存到一个新数组中。
找到您想要的了吗?
你还可以前往community.tulip.co发布你的问题,或者看看其他人是否也遇到过类似问题!
本文对您有帮助吗?