Tulip OCR with AWS Textract
- 25 Jan 2024
- 6 Minutes to read
- Contributors




- Print
Tulip OCR with AWS Textract
- Updated on 25 Jan 2024
- 6 Minutes to read
- Contributors
- Print
Article Summary
Share feedback
Thanks for sharing your feedback!
Note
With Frontline Coplilot™, Text can be extracted directly from images and documents, significantly simplifying the process to do OCR against images in Tulip. Going forward this is the recommended approach.
This article will guide you through setting up AWS Textract Connector on Tulip.
AWS Textract is a cloud-based service provided by Amazon Web Services (AWS) that uses machine learning technology to extract text and data from various types of documents. Textract can analyze scanned documents, PDFs, images, and other files to automatically extract textual content, tables, forms, and key-value pairs.
Key features and capabilities of AWS Textract include:
- Optical Character Recognition (OCR): Textract uses OCR to extract text from scanned documents and images, even if they are in different languages or have complex layouts.
- Key-Value Pair Extraction: Textract can extract key-value pairs from documents, such as invoices or receipts, by identifying the relationship between labels and their associated values.
- Table Extraction: Textract can detect and extract tabular data from documents, preserving the table structure, rows, and columns.
- Query-based text extraction: Textract allows you to retrieve specific information from documents using natural language queries.
- Support for Multiple Document Formats: Textract supports a wide range of document formats, including PDF, JPEG, PNG, and TIFF.
- Form Extraction (Coming soon): Textract can automatically identify form fields, such as checkboxes, radio buttons, and text fields, and extract the corresponding data.
Prerequisites
- A working Tulip Vision workstation with a camera for visual inspection
- Contact Tulip Support to get the AWS Textract Connector and API Key (Textract App coming to Tulip Library soon)
- For PDF file extraction create a Sign-in URL connector
Tulip Connector Setup
In your Tulip instance, select Connectors from the Apps menu.
Select the AWS Connector and ensure it's online, or set one up with the following Connection Details:
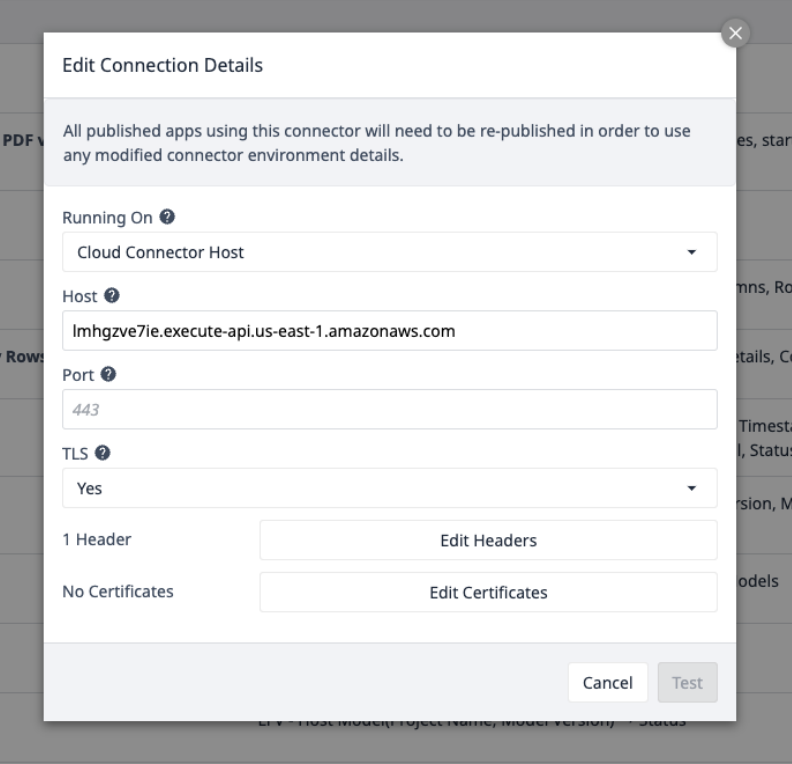
Select Edit Headers and update the X-API-Key, provided by Tulip.
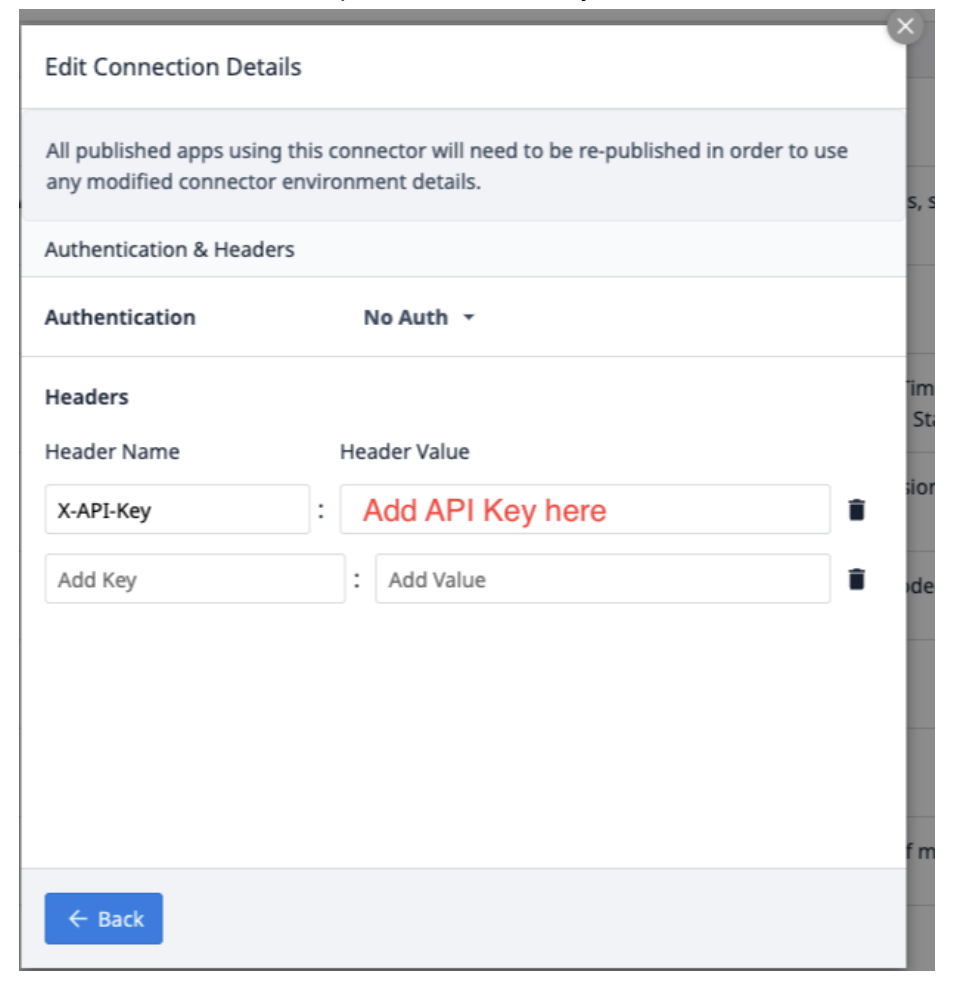
Select Back and then click Test.
Textract in a Tulip Application for Key-Value Pairs (Extraction from a PDF)
In this example, we'll walkthrough how to use Textract in an app to get key-value pairs from a PDF. You'll need to create and configure a connector function in the AWS connector, as well as use trigger logic to run the connector and extract the data we want.
Connector Function Details
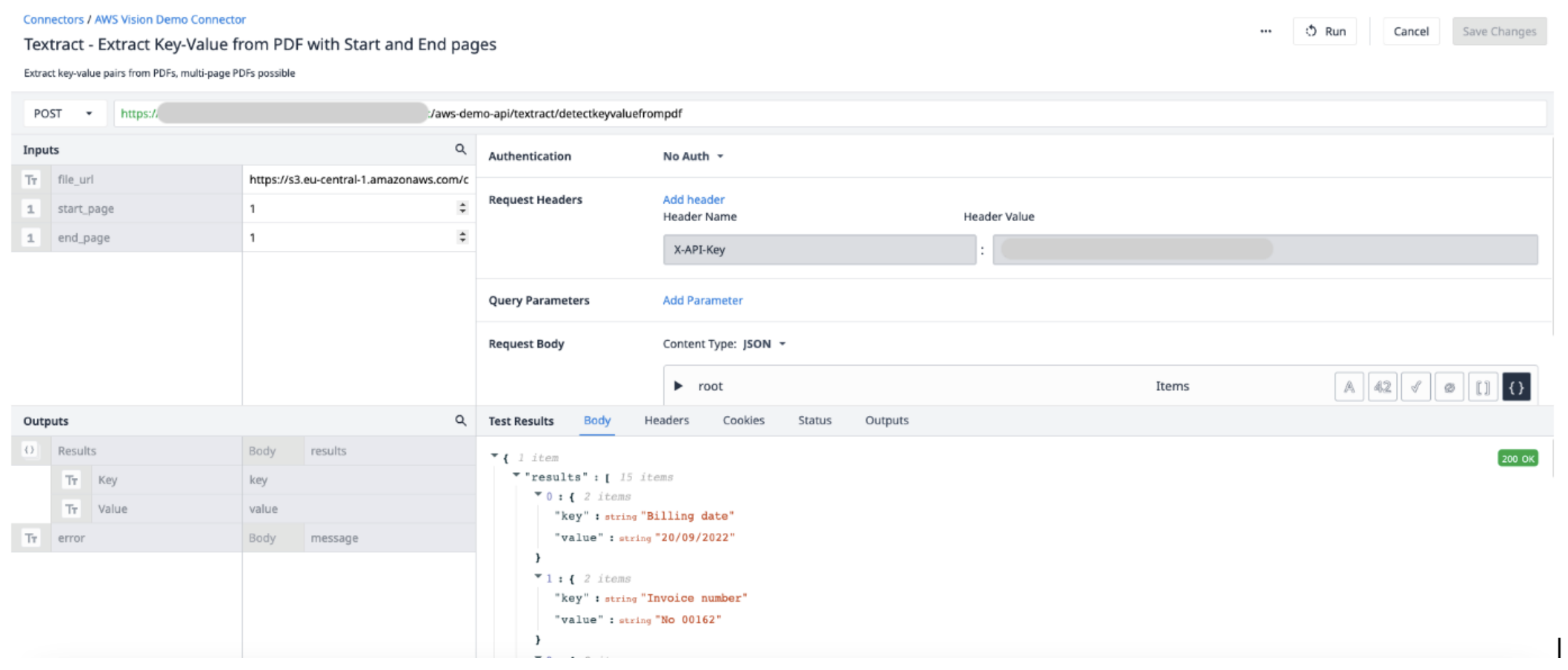
Create a new Connector Function in the AWS Connector. Use the following information to set the Inputs and Outputs.
Inputs
File_url (Text) - URL of the PDF file uploaded to Tulip
Start_page (Int) - the first page in the PDF file to extract from
End_page (Int) - the last page in the PDF file to extract from
Output
Results (Objects) - an objects list of Key and Value pairs.
Application Trigger
In your app, the Triggers will call the connector function to run.
Create a new trigger with the following actions:
- Run the URL Signing Connector with the Sign URL function. The file input should be a text Variable. Use FILETOTEXT (variable.File) expression, where "File" is the name if the variable, to convert the file name into a text string. Save the output to a variable and name it ("SignedURL").
- Run the AWS Textract Key-Value Pairs connector function with the sign URL input (file_url) as well as the start and end pages of the PDF all to be extracted. Save the output to a new Array.
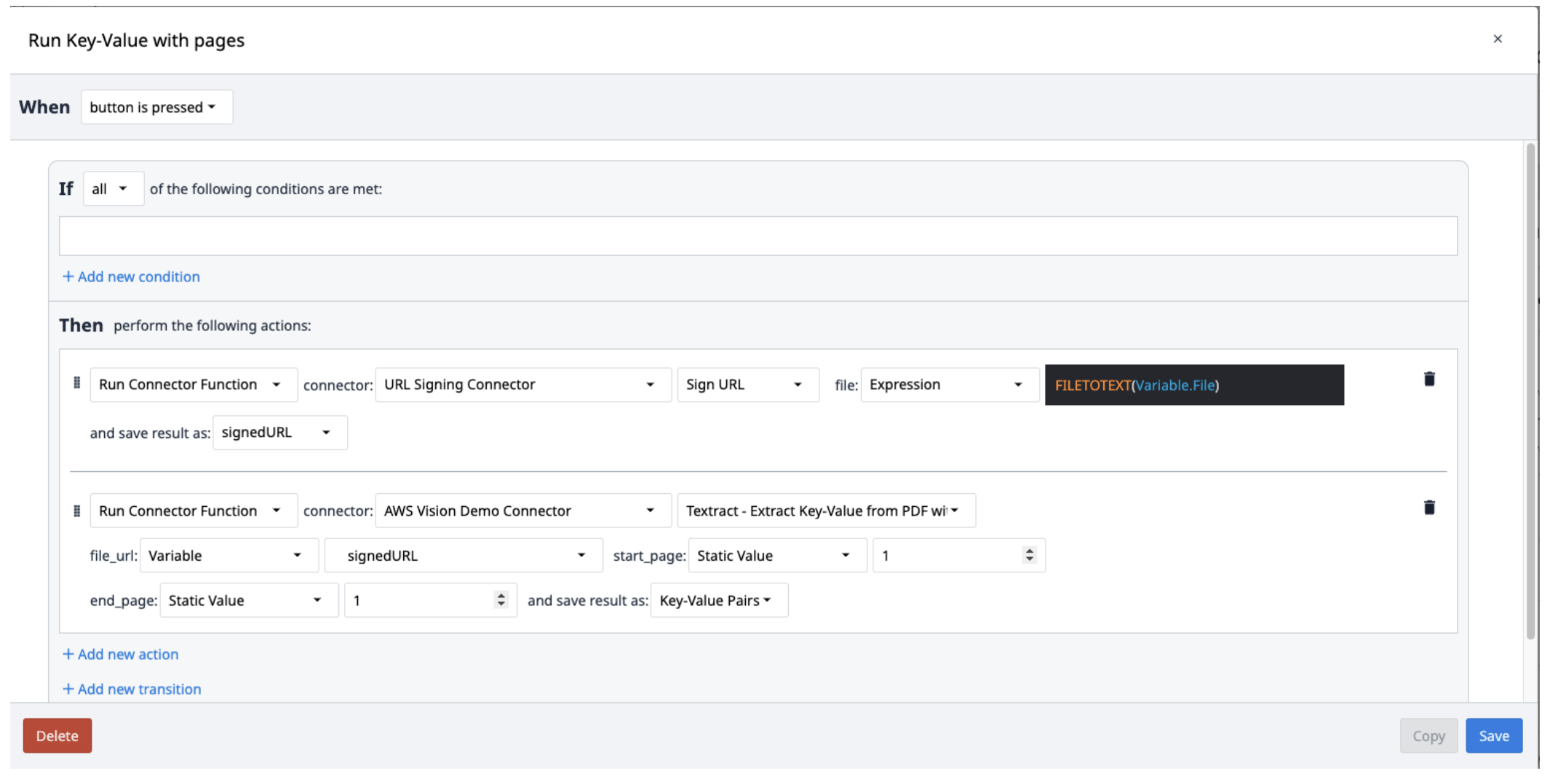
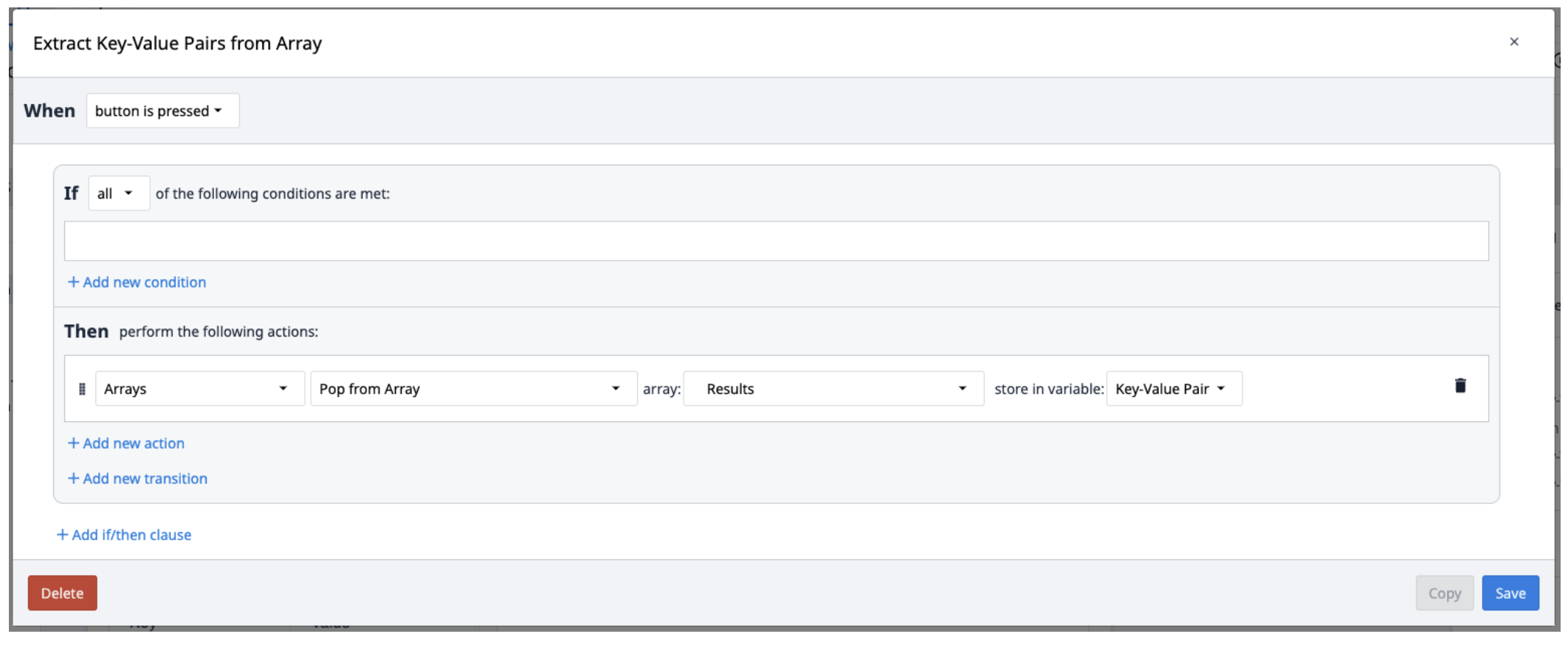
Textract results are saved in an array of objects containing Key-Value pairs. To extract them from the array, create a new trigger that repeat popping the pairs from the array as needed.
You may want to consider using the Looping Customer Widget to pop multiple objects from the array.
Textract in a Tulip Application for Querying (Extraction from a PDF)
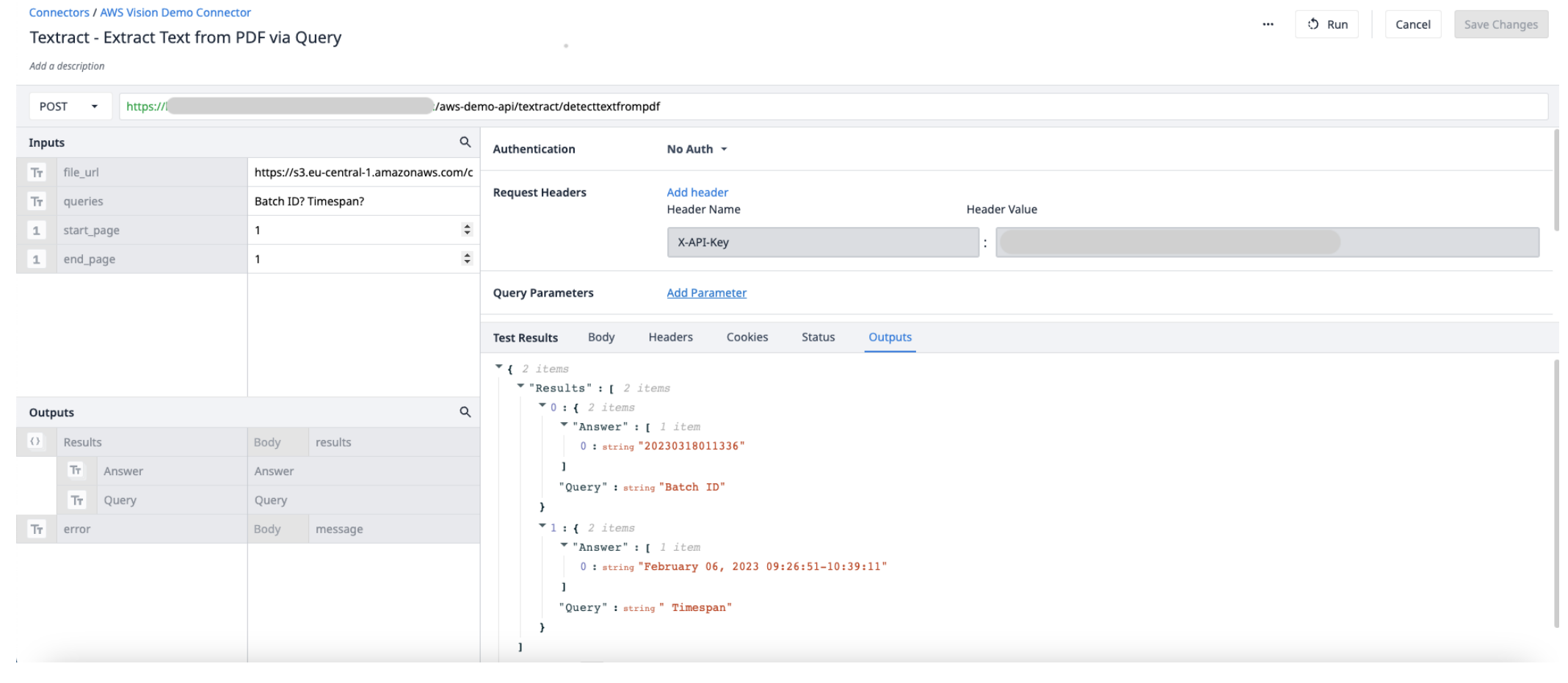
In this example, we'll walkthrough how to use Textract in an app to query data extracted from a PDF. You'll need to create and configure a new connector function in the AWS connector, as well as use trigger logic to run the connector. Querying data allows you to understand or change the received data.
Connector Function Details
Create a new Connector Function in the AWS Connector. Use the following information to set the Inputs and Outputs.
Inputs
File_url (Text) - URL of the PDF file uploaded to Tulip
Start_page (Int) - the first page in the PDF file to extract from
End_page (Int) - the last page in the PDF file to extract from
Output
Results (objects) - an objects list of Answers and Queries
Application Trigger
In your app, the Triggers will call the connector function to run.
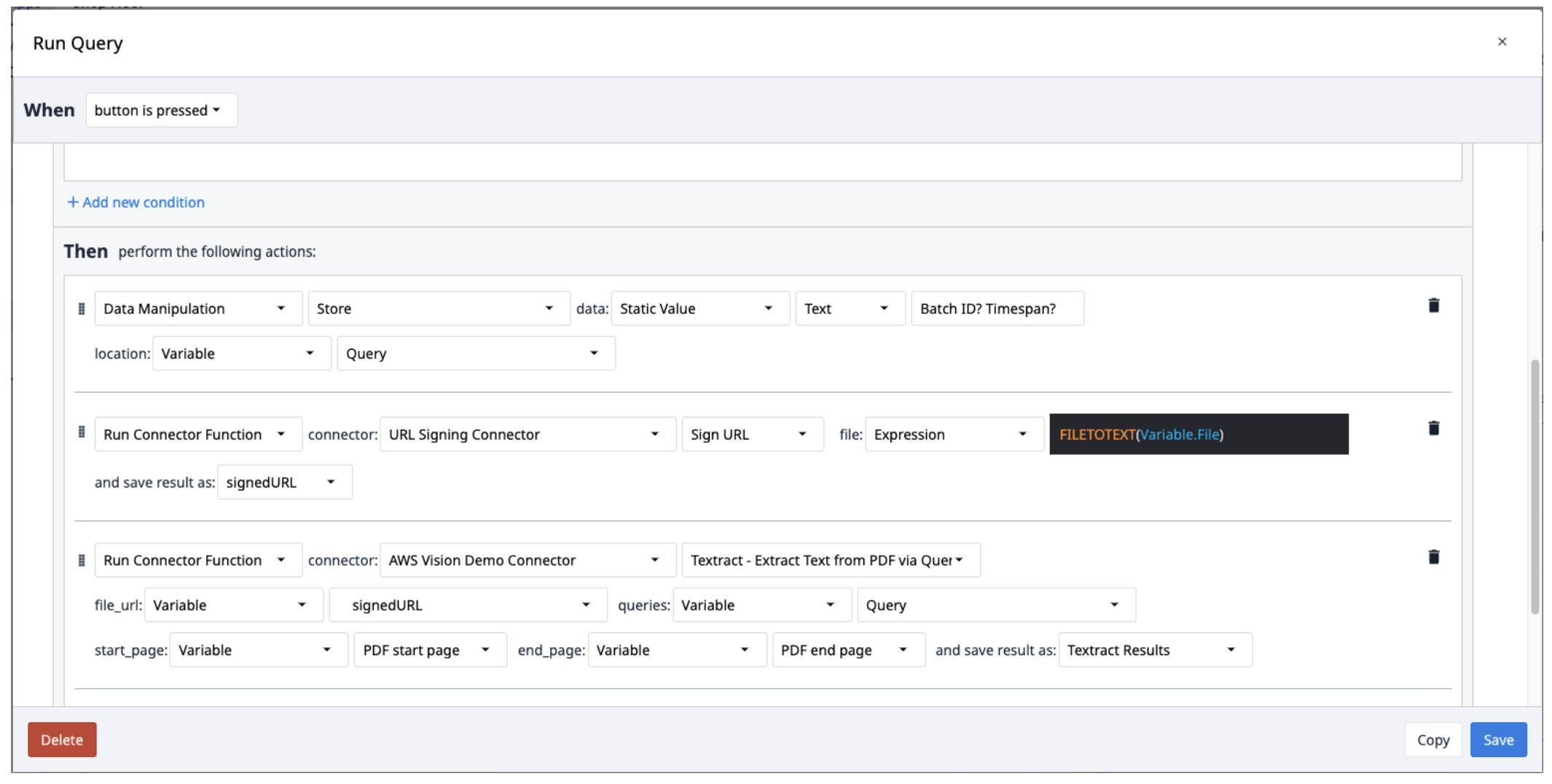
Create a new trigger with the following actions:
- Save the queries into a text variable separated by question marks (?).
- Run the URL Signing Connector with the Sign URL function. The file input should be a text variable. Use FILETOTEXT (variable.File) expression, where "File" is the name if the variable, to convert the file name into a text string. Save the output to a variable and name it ("SignedURL").
- Run the AWS Textract by extracting text from a PDF via the query connector function with the sign URL input (file_url), queries variable, and the start and end pages of the PDF. Save the output to a new array.
Did you find what you were looking for?
You can also head to community.tulip.co to post your question or see if others have faced a similar question!

.gif)
Was this article helpful?