Tulip OCR с AWS Textract
- 31 Jan 2024
- 4 Минуты для чтения
- Авторы




- Распечатать
Tulip OCR с AWS Textract
- Обновление 31 Jan 2024
- 4 Минуты для чтения
- Авторы
- Распечатать
Article Summary
Share feedback
Thanks for sharing your feedback!
:::(Warning) (Примечание) С помощью Frontline Coplilot™ текст можно извлекать непосредственно из изображений и документов, что значительно упрощает процесс OCR изображений в Tulip. В дальнейшем рекомендуется использовать именно этот подход:
В этой статье мы расскажем вам о настройке коннектора AWS Textract на Tulip.
AWS Textract - это облачный сервис, предоставляемый Amazon Web Services (AWS), который использует технологию машинного обучения для извлечения текста и данных из различных типов документов. Textract может анализировать отсканированные документы, PDF-файлы, изображения и другие файлы для автоматического извлечения текстового содержимого, таблиц, форм и пар ключ-значение.
Основные функции и возможности AWS Textract включают:
- Оптическое распознавание символов (OCR): Textract использует OCR для извлечения текста из отсканированных документов и изображений, даже если они написаны на разных языках или имеют сложную компоновку.
- Извлечение пар ключ-значение: Textract может извлекать пары ключ-значение из документов, таких как счета или квитанции, определяя взаимосвязь между метками и связанными с ними значениями.
- Извлечение таблиц: Textract может обнаруживать и извлекать табличные данные из документов, сохраняя структуру таблицы, строки и столбцы.
- Извлечение текста на основе запросов: Textract позволяет извлекать конкретную информацию из документов с помощью запросов на естественном языке.
- Поддержка нескольких форматов документов: Textract поддерживает широкий спектр форматов документов, включая PDF, JPEG, PNG и TIFF.
- Извлечение форм (скоро появится): Textract может автоматически определять поля формы, такие как флажки, радиокнопки и текстовые поля, и извлекать соответствующие данные.
Необходимые условия
- Рабочая станция Tulip Vision с камерой для визуального контроля
- Обратитесь в службу поддержки Tulip, чтобы получить коннектор AWS Textract и ключ API (приложение Textract скоро появится в библиотеке Tulip ).
- Для извлечения PDF-файлов создайте коннектор Sign-in URL
Настройка коннектора Tulip
В вашем экземпляре Tulip выберите Connectors в меню Apps.
Выберите коннектор AWS и убедитесь, что он находится в сети, или настройте его с помощью следующих сведений о подключении:
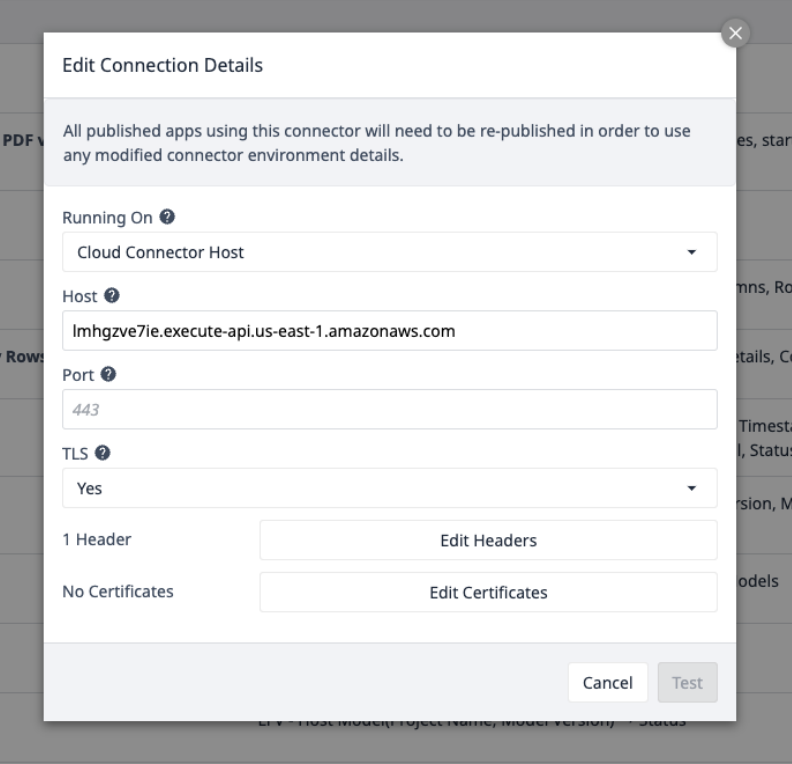
Выберите Edit Headers и обновите X-API-Key, предоставленный Tulip.
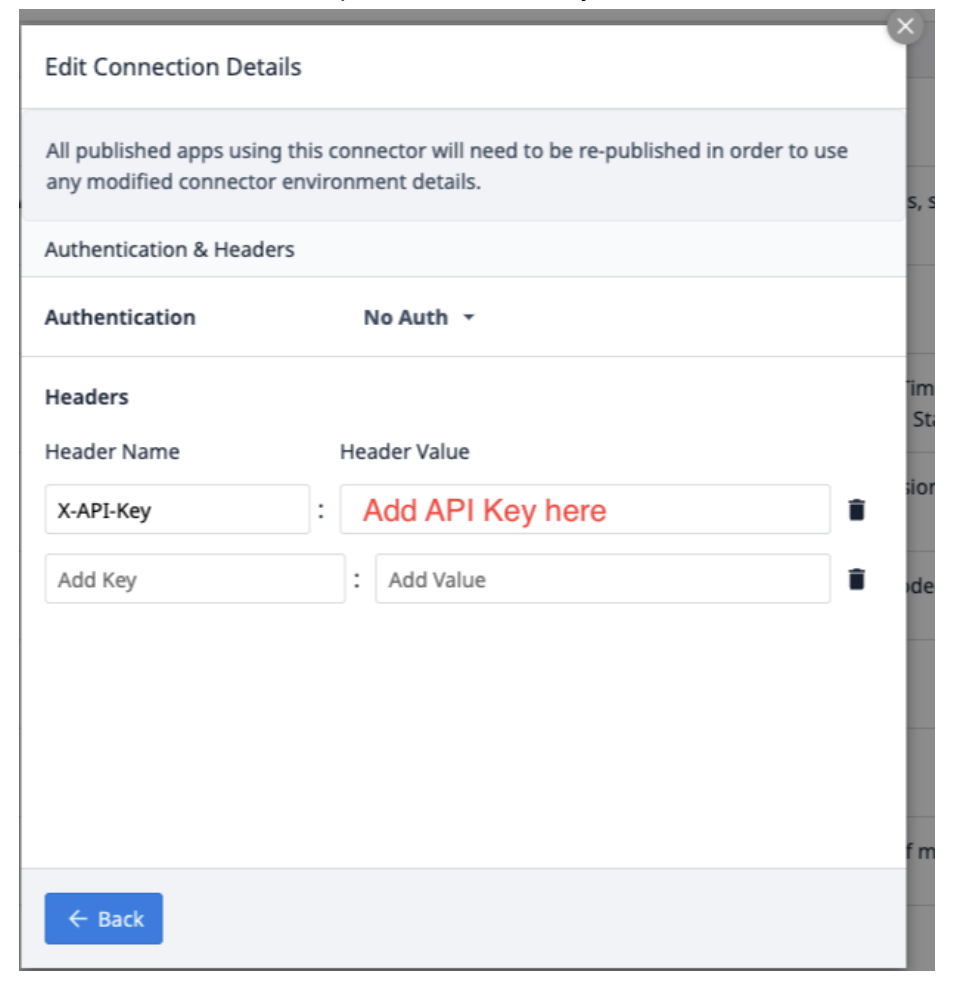
Выберите Back и нажмите Test.
Textract в приложении Tulip для пар ключ-значение (извлечение из PDF)
В этом примере мы рассмотрим, как использовать Textract в приложении для получения пар ключ-значение из PDF. Вам потребуется создать и настроить функцию коннектора в коннекторе AWS, а также использовать триггерную логику для запуска коннектора и извлечения нужных нам данных.
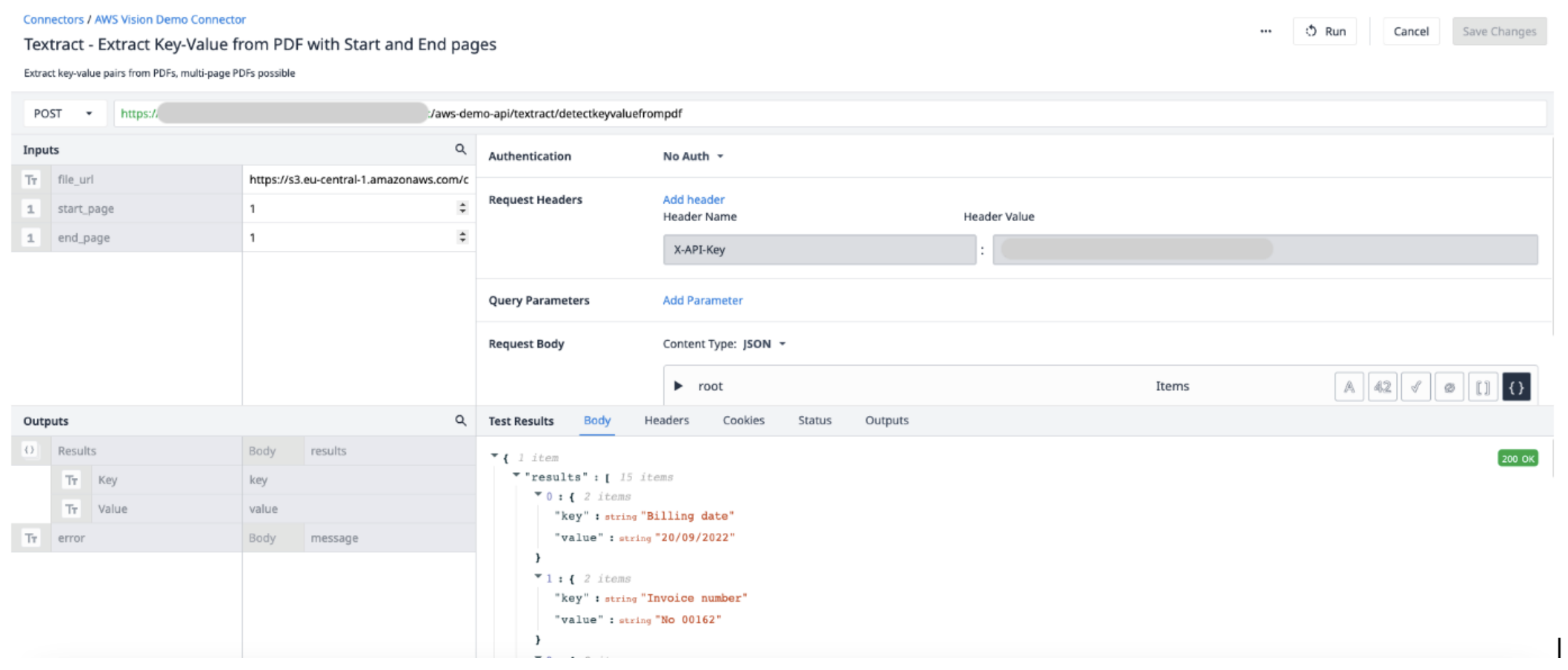
Детали функции коннектора
Создайте новую функцию коннектора в коннекторе AWS. Используйте следующую информацию, чтобы задать Input и Output.
Входные данные File_url (Text) - URL-адрес PDF-файла, загруженного в Tulip Start_page (Int) - первая страница PDF-файла для извлечения из End_page (Int) - последняя страница PDF-файла для извлечения из него.
OutputResults (Objects) - список объектов, состоящий из пар Key и Value.
Триггер приложения
В вашем приложении триггеры будут вызывать функцию коннектора для выполнения.
Создайте новый триггер со следующими действиями:
- Запустите коннектор подписи URL с функцией Sign URL. В качестве входного файла должна быть текстовая переменная. Используйте выражение FILETOTEXT (variable.File), где "File" - это имя переменной, чтобы преобразовать имя файла в текстовую строку. Сохраните полученный результат в переменной и назовите ее ("SignedURL").
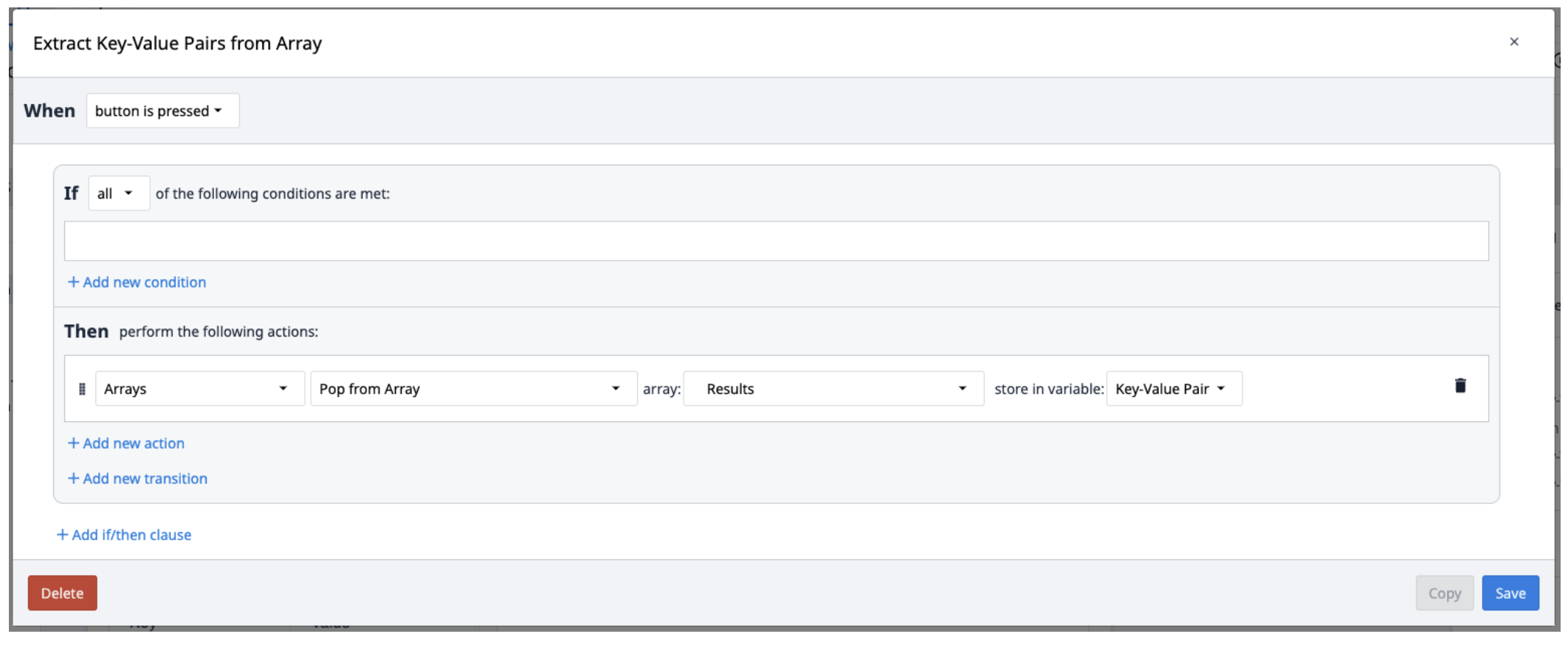
- Запустите функцию коннектора AWS Textract Key-Value Pairs с входным URL-адресом подписи (file_url), а также начальной и конечной страницами PDF-файла, которые необходимо извлечь. Сохраните результаты в новом массиве.
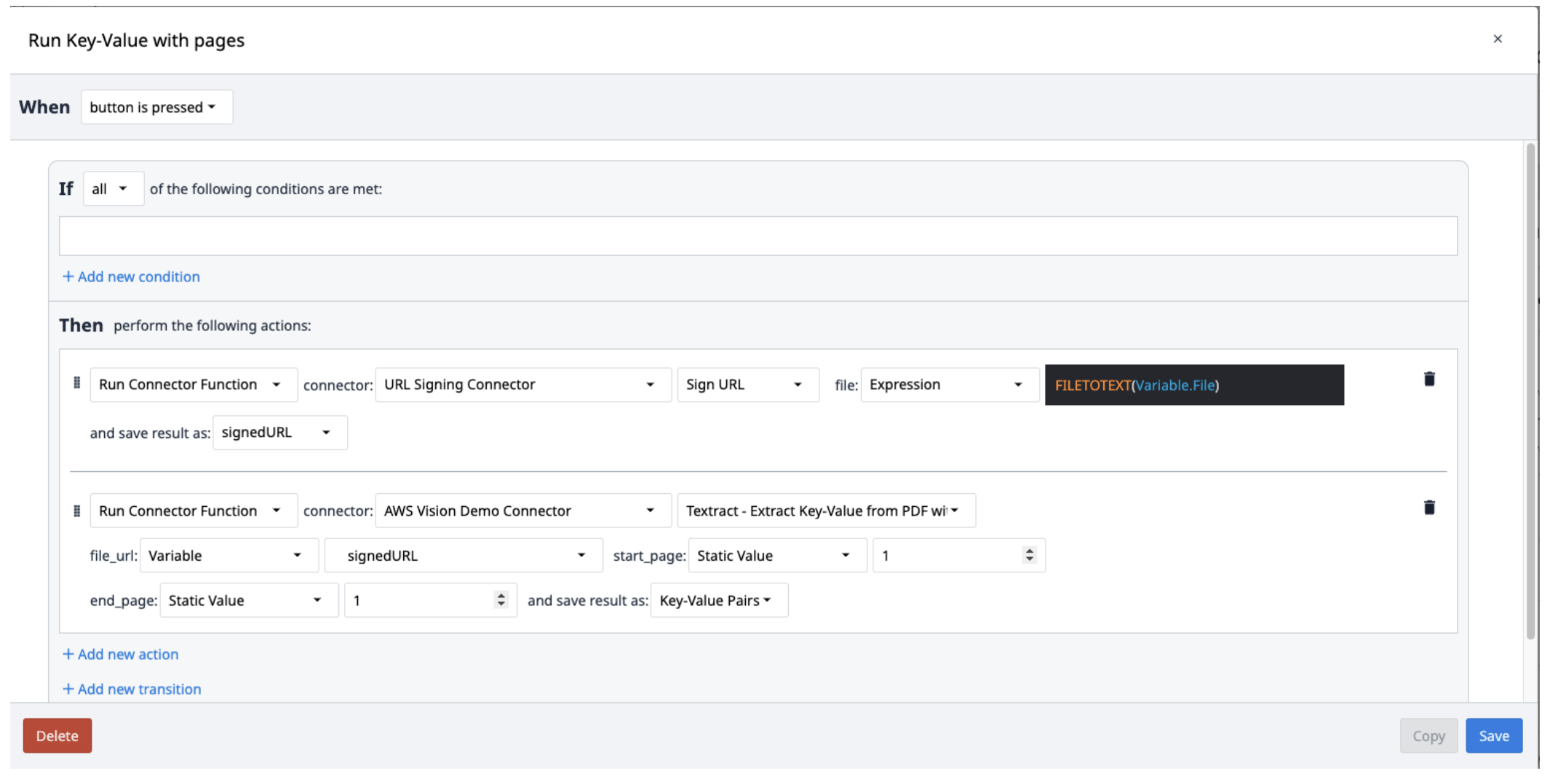
Результаты Textract сохраняются в массиве объектов, содержащих пары ключ-значение. Чтобы извлечь их из массива, создайте новый триггер, который будет повторять выборку пар из массива по мере необходимости.
Возможно, вы захотите использовать виджет Looping Customer для извлечения нескольких объектов из массива.
Textract в приложении Tulip для запроса (извлечение из PDF)
В этом примере мы рассмотрим, как использовать Textract в приложении для запроса данных, извлеченных из PDF. Вам нужно будет создать и настроить новую функцию коннектора в коннекторе AWS, а также использовать логику триггера для запуска коннектора. Запрос данных позволяет понять или изменить полученные данные.
Детали функции коннектора
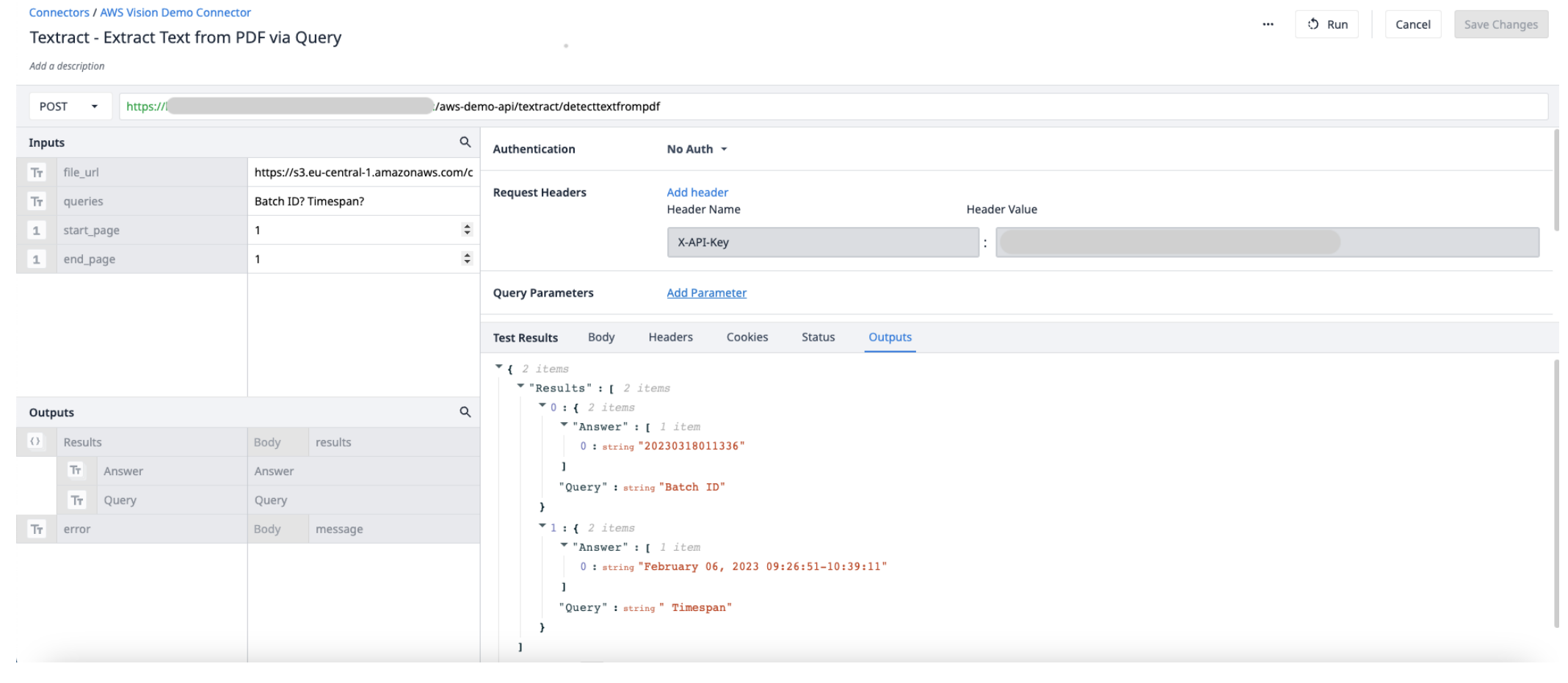
Создайте новую функцию коннектора в коннекторе AWS. Используйте следующую информацию, чтобы задать Input и Output.
Входные данные File_url (Text) - URL-адрес PDF-файла, загруженного в Tulip Start_page (Int) - первая страница PDF-файла для извлечения из End_page (Int) - последняя страница PDF-файла для извлечения из него.
Выходныерезультаты (объекты) - список объектов, содержащих ответы и запросы
Триггер приложения
В вашем приложении триггеры будут вызывать функцию коннектора для выполнения.
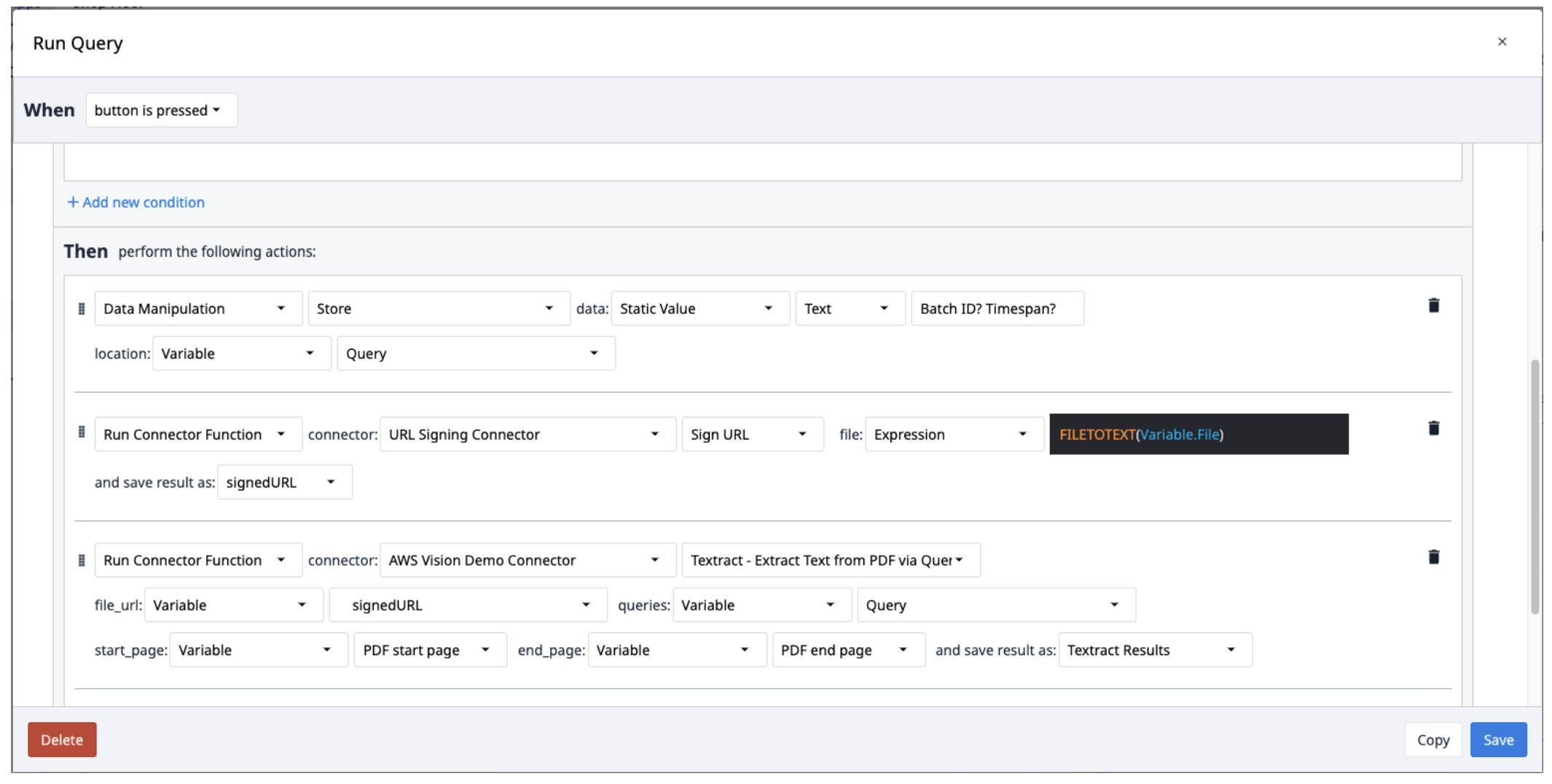
Создайте новый триггер со следующими действиями:
- Сохраните запросы в текстовой переменной, разделив их вопросительными знаками (?).
- Запустите коннектор подписи URL с помощью функции Sign URL. В качестве входного файла должна быть текстовая переменная. Используйте выражение FILETOTEXT (variable.File), где "File" - это имя переменной, чтобы преобразовать имя файла в текстовую строку. Сохраните полученный результат в переменной и назовите ее ("SignedURL").
- Запустите AWS Textract, извлекая текст из PDF-файла с помощью функции коннектора запросов с входным URL-адресом подписи (file_url), переменной queries, начальной и конечной страницами PDF-файла. Сохраните выходные данные в новый массив.
Нашли то, что искали?
Вы также можете зайти на community.tulip.co, чтобы задать свой вопрос или узнать, сталкивались ли другие с подобным вопросом!
Была ли эта статья полезной?