OCR de tulipas com o AWS Textract
- 31 Jan 2024
- 5 Minutos para Ler
- Contribuintes




- Impressão
OCR de tulipas com o AWS Textract
- Atualizado em 31 Jan 2024
- 5 Minutos para Ler
- Contribuintes
- Impressão
Article Summary
Share feedback
Thanks for sharing your feedback!
:::(Warning) (Observação) Com o Frontline Coplilot™, o texto pode ser extraído diretamente de imagens e documentos, simplificando significativamente o processo de OCR em imagens no Tulip. A partir de agora, essa é a abordagem recomendada :::
Este artigo o guiará na configuração do AWS Textract Connector no Tulip.
O AWS Textract é um serviço baseado em nuvem fornecido pela Amazon Web Services (AWS) que usa tecnologia de aprendizado de máquina para extrair texto e dados de vários tipos de documentos. O Textract pode analisar documentos digitalizados, PDFs, imagens e outros arquivos para extrair automaticamente conteúdo textual, tabelas, formulários e pares de valores-chave.
Os principais recursos e capacidades do AWS Textract incluem:
- Reconhecimento óptico de caracteres (OCR): O Textract usa OCR para extrair texto de documentos e imagens digitalizados, mesmo que estejam em idiomas diferentes ou tenham layouts complexos.
- Extração de pares chave-valor: O Textract pode extrair pares de valores-chave de documentos, como faturas ou recibos, identificando a relação entre rótulos e seus valores associados.
- Extração detabelas: O Textract pode detectar e extrair dados tabulares de documentos, preservando a estrutura, as linhas e as colunas da tabela.
- Extração detexto baseada em consulta: O Textract permite que você recupere informações específicas de documentos usando consultas de linguagem natural.
- Suporte a vários formatos de documentos: O Textract é compatível com uma ampla variedade de formatos de documentos, incluindo PDF, JPEG, PNG e TIFF.
- Extração de formulários (em breve): O Textract pode identificar automaticamente campos de formulário, como caixas de seleção, botões de rádio e campos de texto, e extrair os dados correspondentes.
Pré-requisitos
- Uma estação de trabalho Tulip Vision em funcionamento com uma câmera para inspeção visual
- Entre em contato com o Tulip Support para obter o AWS Textract Connector e a chave de API (o aplicativo Textract chegará à Tulip Library em breve).
- Para extração de arquivos PDF, crie um conector de URL de login
Configuração do conector Tulip
Em sua instância do Tulip, selecione Connectors (Conectores ) no menu Apps.
Selecione o conector AWS e verifique se ele está on-line ou configure um com os seguintes detalhes de conexão:
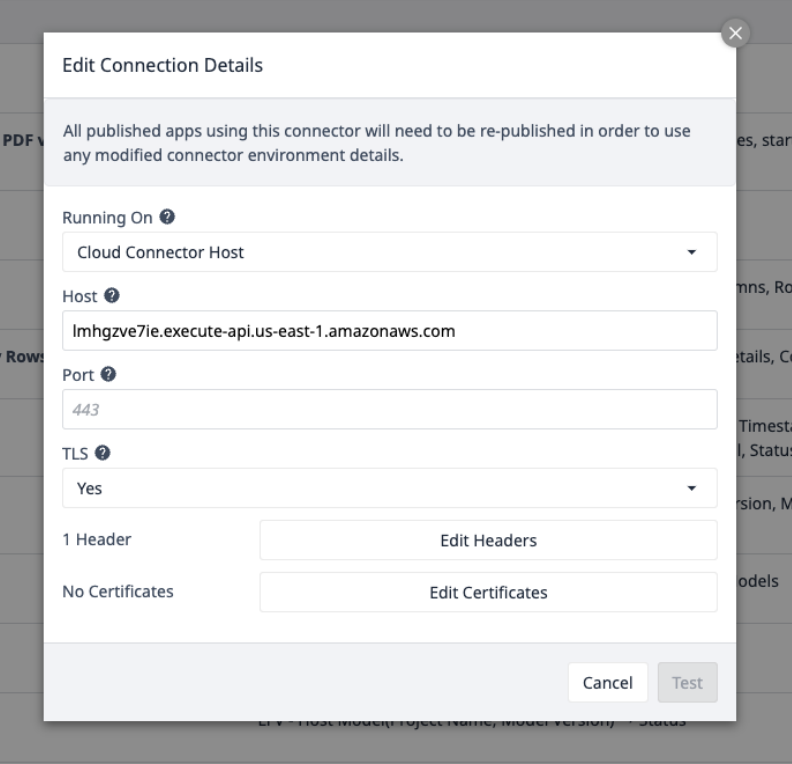
Selecione Edit Headers (Editar cabeçalhos ) e atualize a X-API-Key, fornecida pela Tulip.
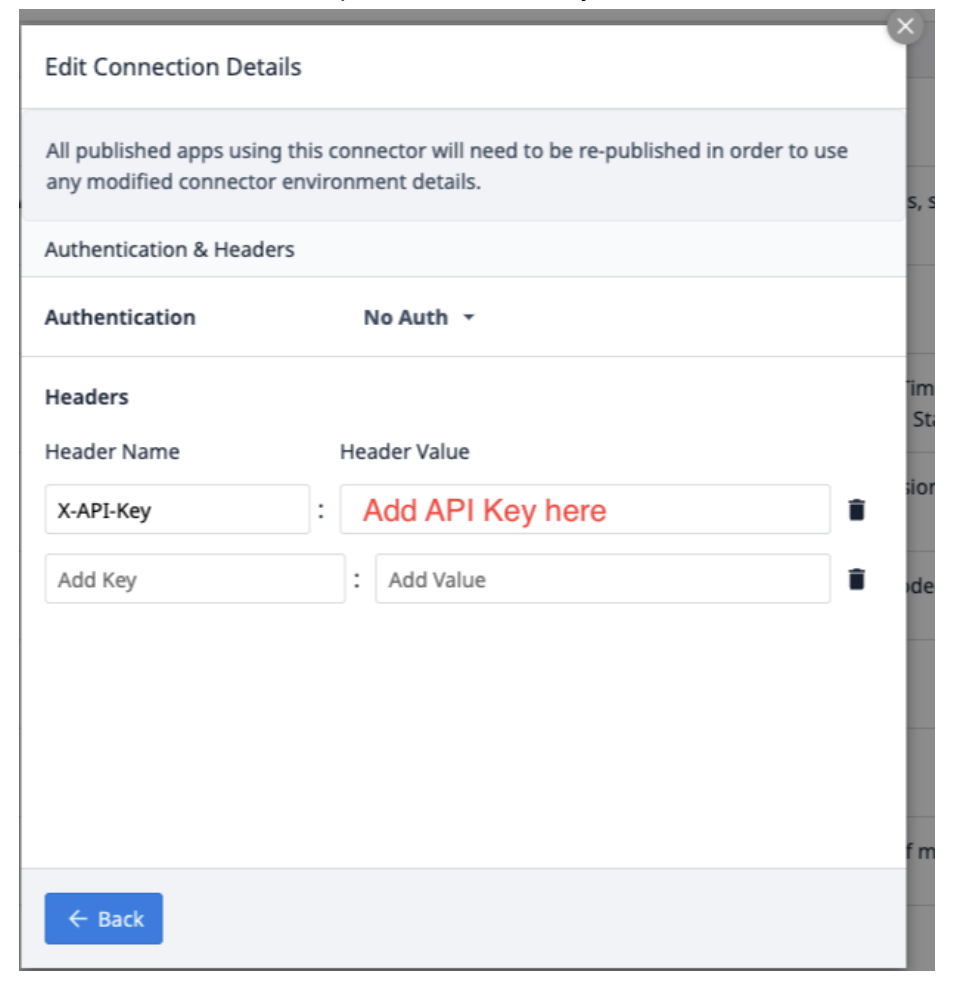
Selecione Back (Voltar ) e clique em Test (Testar).
Textract em um aplicativo Tulip para pares de chave-valor (extração de um PDF)
Neste exemplo, mostraremos como usar o Textract em um aplicativo para obter pares de valores-chave de um PDF. Você precisará criar e configurar uma função de conector no conector do AWS, bem como usar a lógica de acionamento para executar o conector e extrair os dados que desejamos.
Detalhes da função do conector
Crie uma nova função de conector no AWS Connector. Use as seguintes informações para definir os Inputs e Outputs.
Inputs File_url (Text) - URL do arquivo PDF carregado no Tulip Start_page (Int) - a primeira página do arquivo PDF a ser extraída End_page (Int) - a última página do arquivo PDF a ser extraída
OutputResults (Objects) - uma lista de objetos de pares de chave e valor.
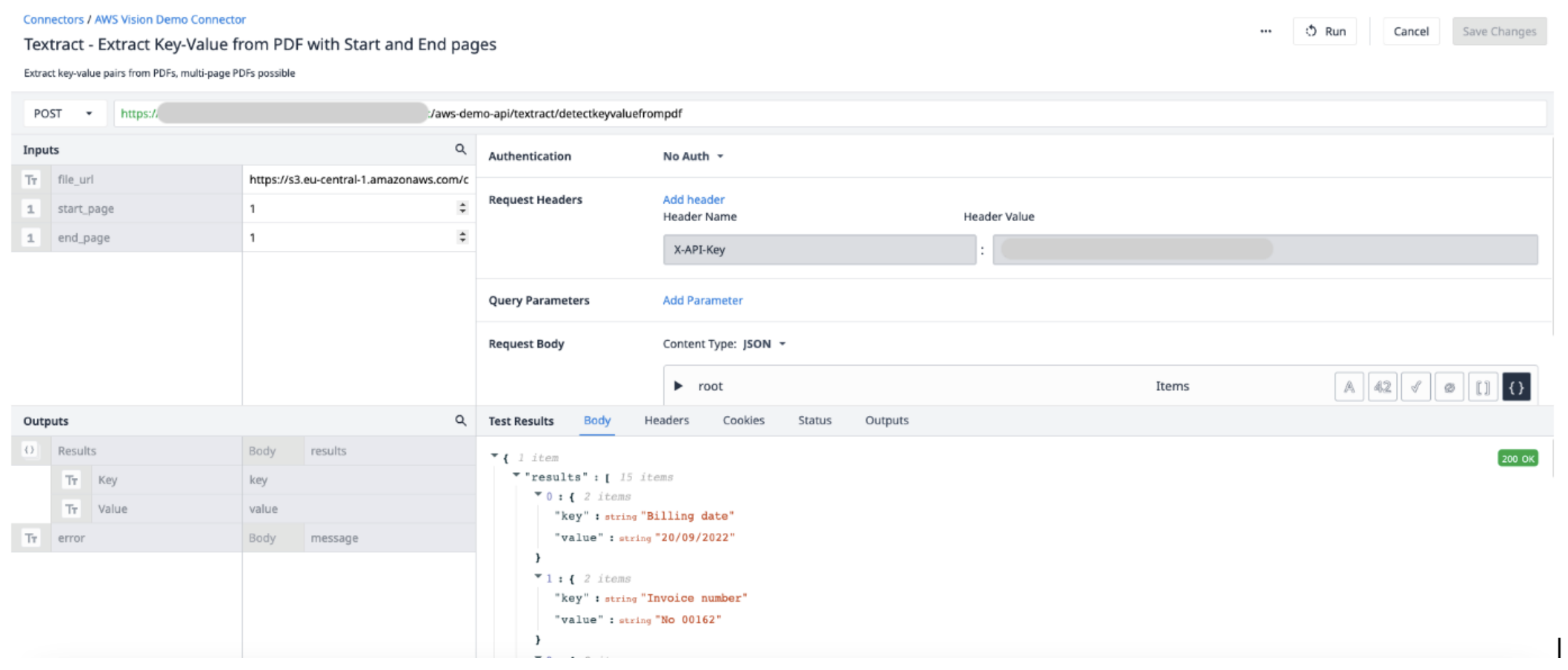
Acionador de aplicativo
Em seu aplicativo, os Triggers chamarão a função do conector para execução.
Crie um novo acionador com as seguintes ações:
- Executar o conector de assinatura de URL com a função Sign URL. A entrada do arquivo deve ser uma variável de texto. Use a expressão FILETOTEXT (variable.File), em que "File" é o nome da variável, para converter o nome do arquivo em uma cadeia de texto. Salve a saída em uma variável e nomeie-a ("SignedURL").
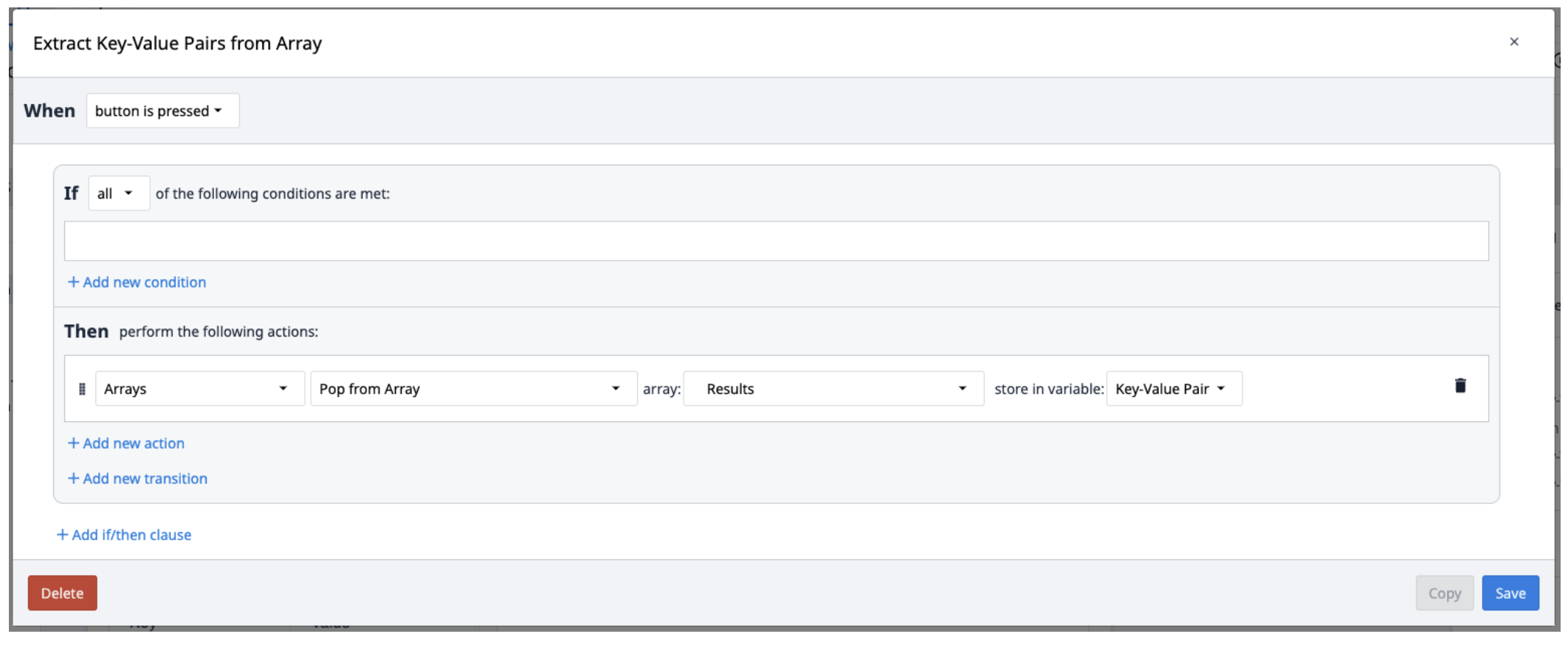
- Execute a função do conector AWS Textract Key-Value Pairs com a entrada de URL de sinal (file_url), bem como as páginas inicial e final do PDF a ser extraído. Salve a saída em uma nova matriz.
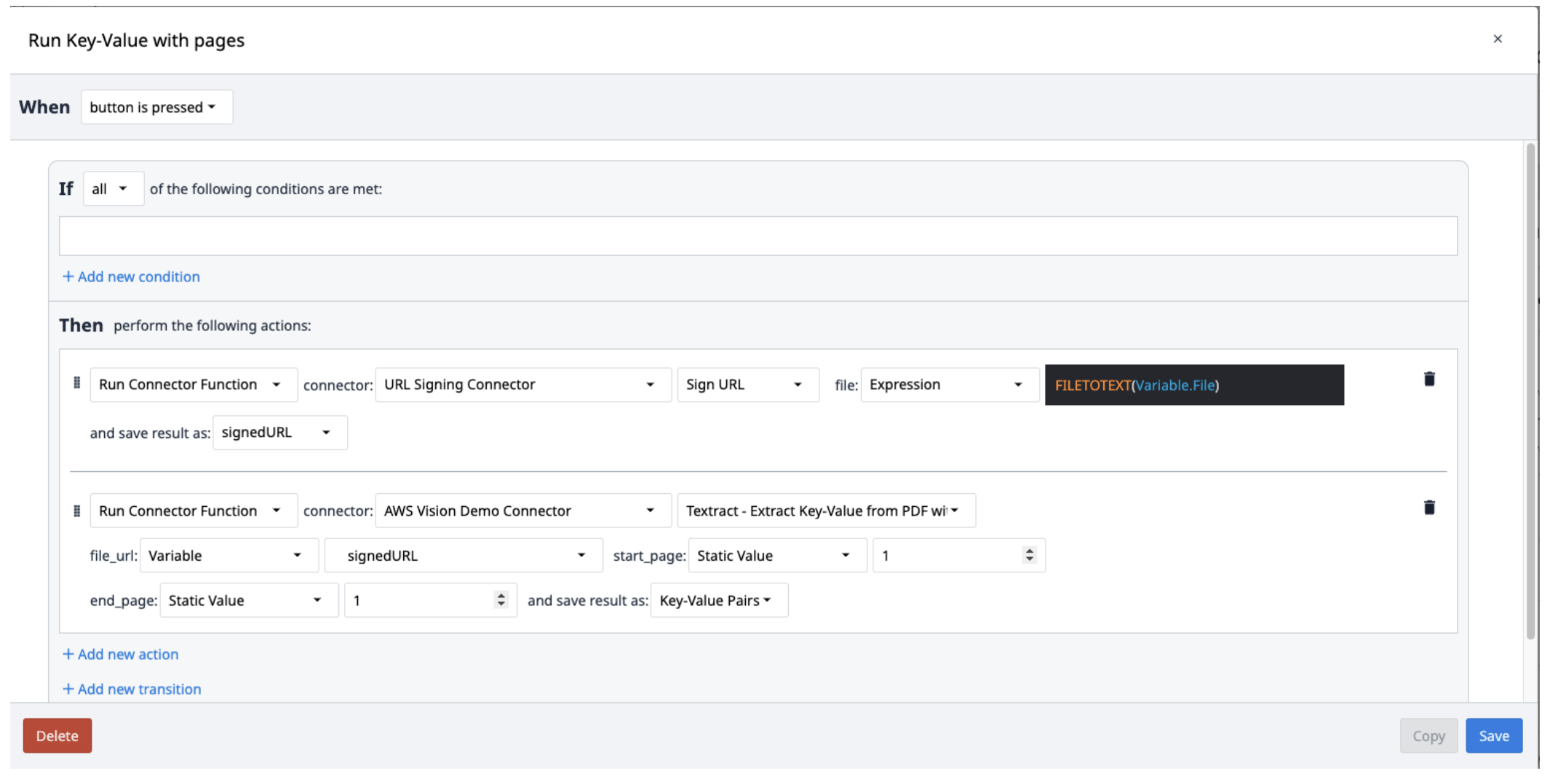
Os resultados do Textract são salvos em uma matriz de objetos contendo pares de chave-valor. Para extraí-los da matriz, crie um novo acionador que repita a extração dos pares da matriz conforme necessário.
Talvez você queira considerar o uso do Looping Customer Widget para extrair vários objetos da matriz.
Textract em um aplicativo Tulip para consulta (extração de um PDF)
Neste exemplo, mostraremos como usar o Textract em um aplicativo para consultar dados extraídos de um PDF. Você precisará criar e configurar uma nova função de conector no conector do AWS, bem como usar a lógica de acionamento para executar o conector. A consulta de dados permite que você entenda ou altere os dados recebidos.
Detalhes da função do conector
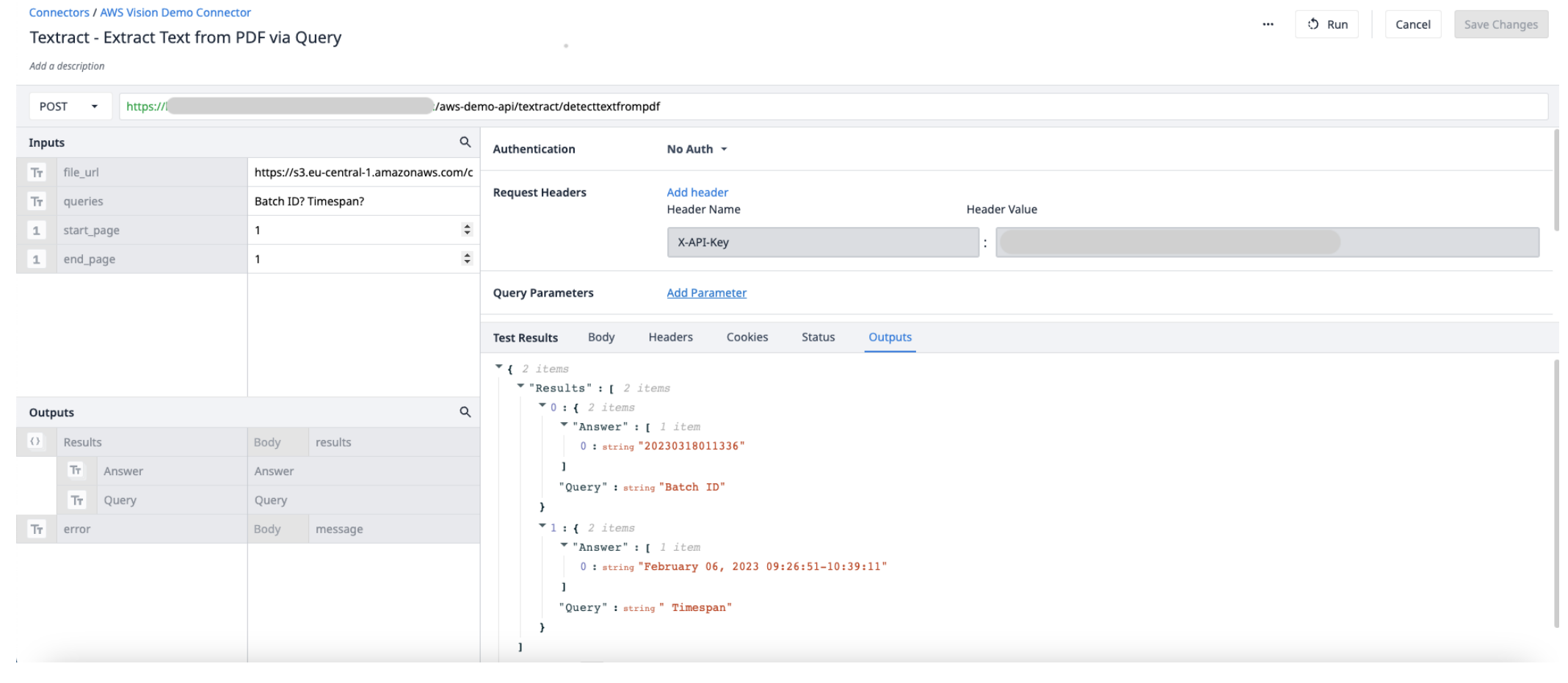
Crie uma nova função de conector no AWS Connector. Use as seguintes informações para definir os Inputs e Outputs.
Inputs File_url (Text) - URL do arquivo PDF carregado na Tulip Start_page (Int) - a primeira página do arquivo PDF a ser extraída End_page (Int) - a última página do arquivo PDF a ser extraída
OutputResults (objects) - uma lista de objetos de respostas e consultas
Acionador de aplicativo
Em seu aplicativo, os Triggers chamarão a função do conector para execução.
Crie um novo acionador com as seguintes ações:
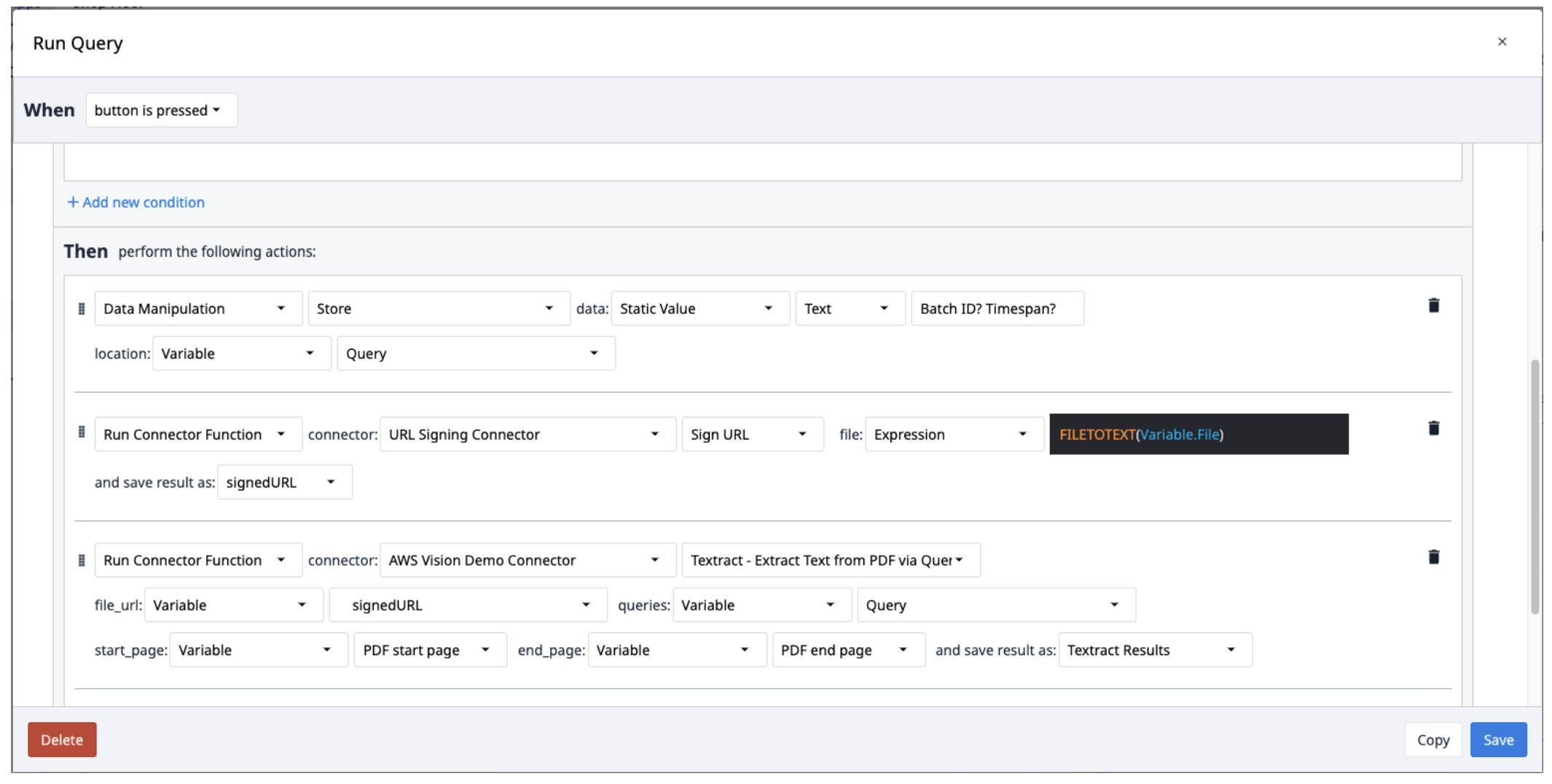
- Salve as consultas em uma variável de texto separada por pontos de interrogação (?).
- Execute o conector de assinatura de URL com a função Sign URL. A entrada do arquivo deve ser uma variável de texto. Use a expressão FILETOTEXT (variable.File), em que "File" é o nome da variável, para converter o nome do arquivo em uma cadeia de caracteres de texto. Salve a saída em uma variável e nomeie-a ("SignedURL").
- Execute o AWS Textract extraindo texto de um PDF por meio da função de conector de consulta com a entrada de URL de sinal (file_url), a variável de consulta e as páginas inicial e final do PDF. Salve a saída em uma nova matriz.
Encontrou o que estava procurando?
Você também pode acessar community.tulip.co para publicar sua pergunta ou ver se outras pessoas tiveram uma pergunta semelhante!
Este artigo foi útil?