Tulipe OCR avec AWS Textract
- 31 Jan 2024
- 5 Minutes à lire
- Contributeurs




- Impression
Tulipe OCR avec AWS Textract
- Mis à jour le 31 Jan 2024
- 5 Minutes à lire
- Contributeurs
- Impression
Article Summary
Share feedback
Thanks for sharing your feedback!
:::(Warning) (Note) Avec Frontline Coplilot™, le texte peut être extrait directement des images et des documents, ce qui simplifie considérablement le processus d'OCR des images dans Tulip. C'est l'approche recommandée pour l'avenir :: :
Cet article vous guidera dans l'installation du connecteur AWS Textract sur Tulip.
AWS Textract est un service en nuage fourni par Amazon Web Services (AWS) qui utilise une technologie d'apprentissage automatique pour extraire du texte et des données de divers types de documents. Textract peut analyser des documents numérisés, des PDF, des images et d'autres fichiers pour en extraire automatiquement le contenu textuel, les tableaux, les formulaires et les paires clé-valeur.
Les principales caractéristiques et capacités d'AWS Textract sont les suivantes :
- Reconnaissance optique de caractères (OCR): Textract utilise l'OCR pour extraire le texte des documents et images numérisés, même s'ils sont rédigés dans des langues différentes ou si leur mise en page est complexe.
- Extraction de paires clé-valeur: Textract peut extraire des paires clé-valeur de documents, tels que des factures ou des reçus, en identifiant la relation entre les étiquettes et leurs valeurs associées.
- Extraction de tableaux: Textract peut détecter et extraire des données tabulaires à partir de documents, en préservant la structure du tableau, les lignes et les colonnes.
- Extraction de texte basée sur des requêtes: Textract vous permet d'extraire des informations spécifiques à partir de documents en utilisant des requêtes en langage naturel.
- Prise en charge de plusieurs formats de documents: Textract prend en charge un large éventail de formats de documents, notamment PDF, JPEG, PNG et TIFF.
- Extraction de formulaires (bientôt disponible): Textract peut identifier automatiquement les champs de formulaire, tels que les cases à cocher, les boutons radio et les champs de texte, et extraire les données correspondantes.
Conditions préalables
- Une station de travail Tulip Vision fonctionnelle avec une caméra pour l'inspection visuelle.
- Contactez le support Tulip pour obtenir le connecteur AWS Textract et la clé API (l'application Textract sera bientôt disponible dans la bibliothèque Tulip ).
- Pour l'extraction de fichiers PDF, créer un connecteur URL de connexion.
Configuration du connecteur Tulip
Dans votre instance Tulip, sélectionnez Connecteurs dans le menu Apps.
Sélectionnez le connecteur AWS et assurez-vous qu'il est en ligne, ou configurez-en un avec les détails de connexion suivants :
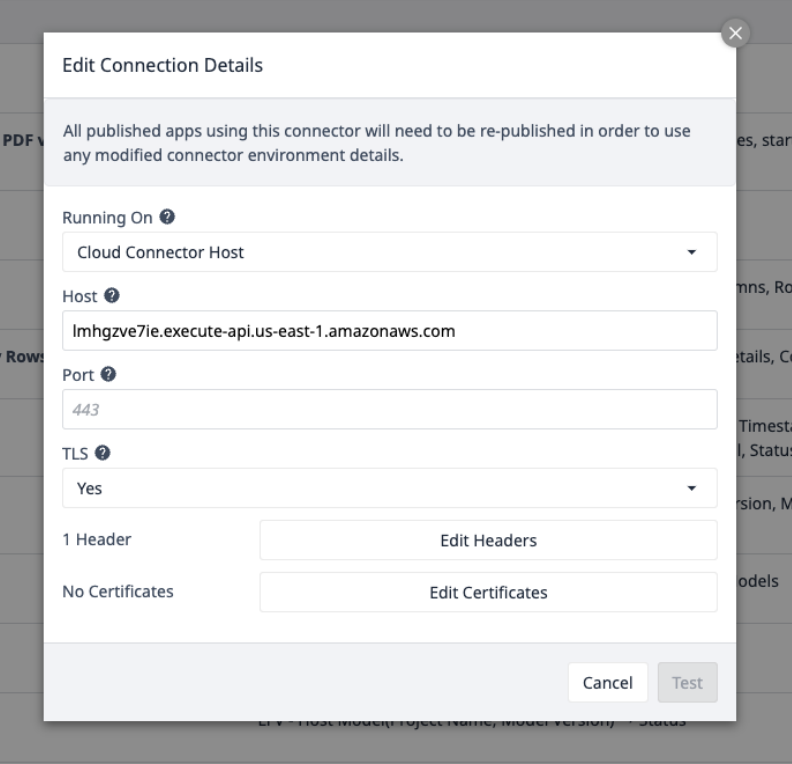
Sélectionnez Edit Headers et mettez à jour la clé X-API, fournie par Tulip.
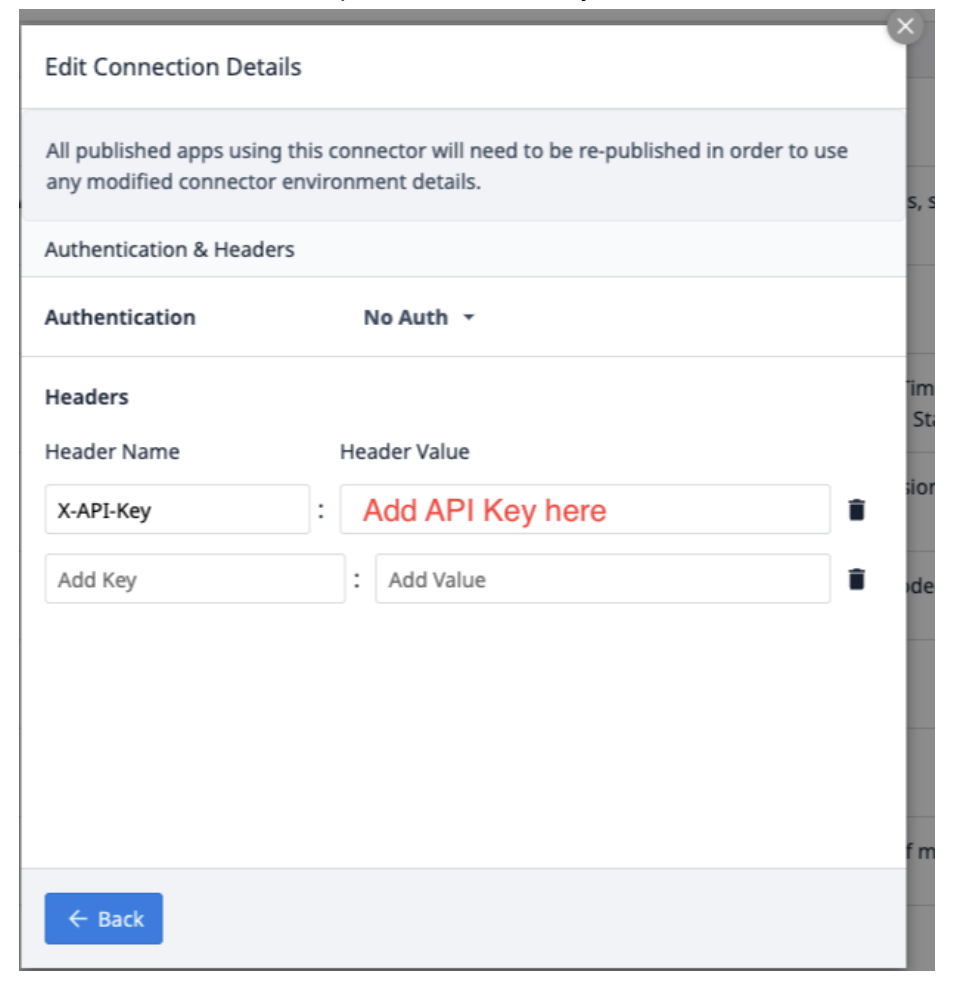
Sélectionnez Retour et cliquez sur Test.
Textract dans une application Tulip pour les paires clé-valeur (extraction à partir d'un PDF)
Dans cet exemple, nous allons voir comment utiliser Textract dans une application pour extraire des paires clé-valeur d'un PDF. Vous devrez créer et configurer une fonction de connecteur dans le connecteur AWS, ainsi qu'utiliser une logique de déclenchement pour exécuter le connecteur et extraire les données que nous voulons.
Détails de la fonction de connecteur
Créez une nouvelle fonction de connecteur dans le connecteur AWS. Utilisez les informations suivantes pour définir les Input et les Output.
Inputs File_url (Text) - URL du fichier PDF téléchargé sur Tulip Start_page (Int) - la première page du fichier PDF à extraire End_page (Int) - la dernière page du fichier PDF à extraire
Résultats desortie(objets) - une liste d'objets de paires de clés et de valeurs.
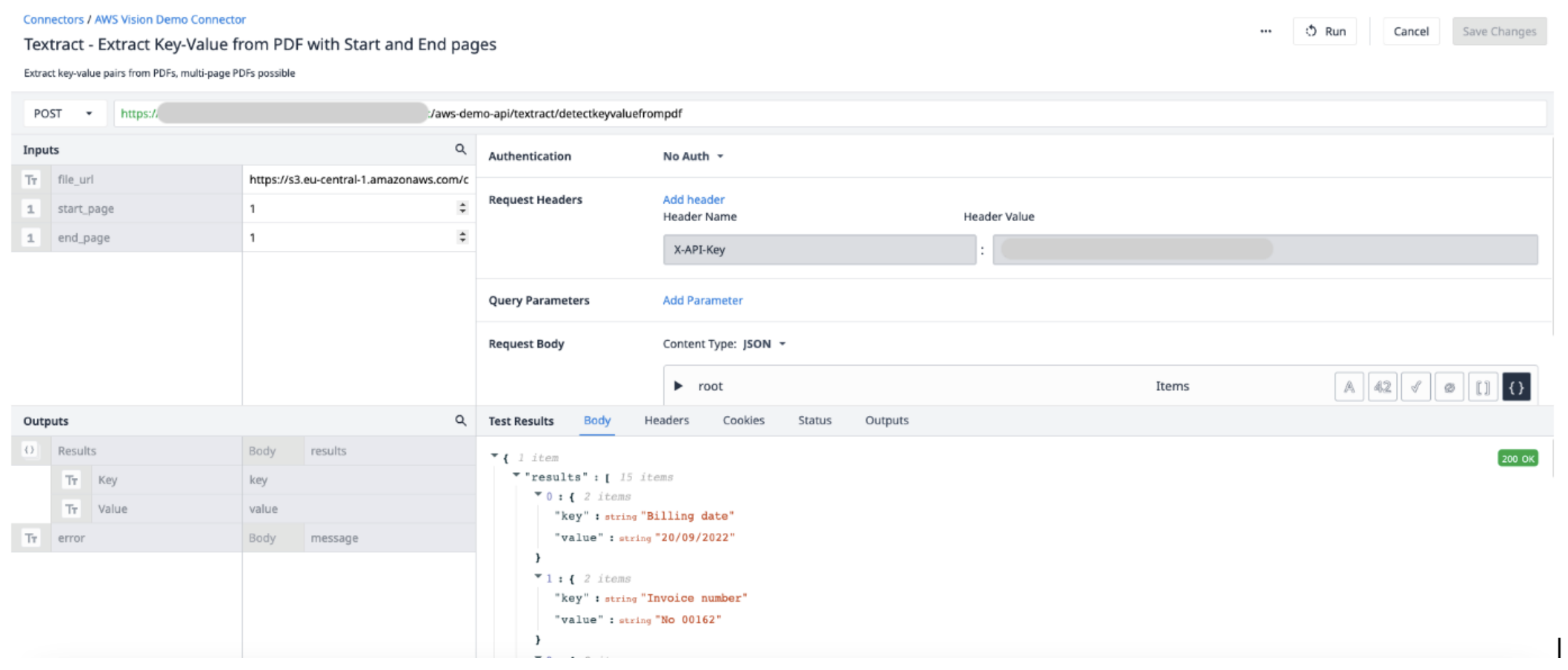
Déclencheur d'application
Dans votre application, les déclencheurs appelleront la fonction du connecteur à s'exécuter.
Créez un nouveau déclencheur avec les actions suivantes :
- Exécuter le connecteur de signature d'URL avec la fonction Signer l'URL. Le fichier d'entrée doit être une variable texte. Utilisez l'expression FILETOTEXT (variable.File), où "File" est le nom de la variable, pour convertir le nom du fichier en une chaîne de texte. Enregistrez la sortie dans une variable et nommez-la ("SignedURL").
- Exécutez la fonction de connecteur AWS Textract Key-Value Pairs avec l'URL signée en entrée (file_url) ainsi que les pages de début et de fin du PDF à extraire. Sauvegarder la sortie dans un nouveau tableau.
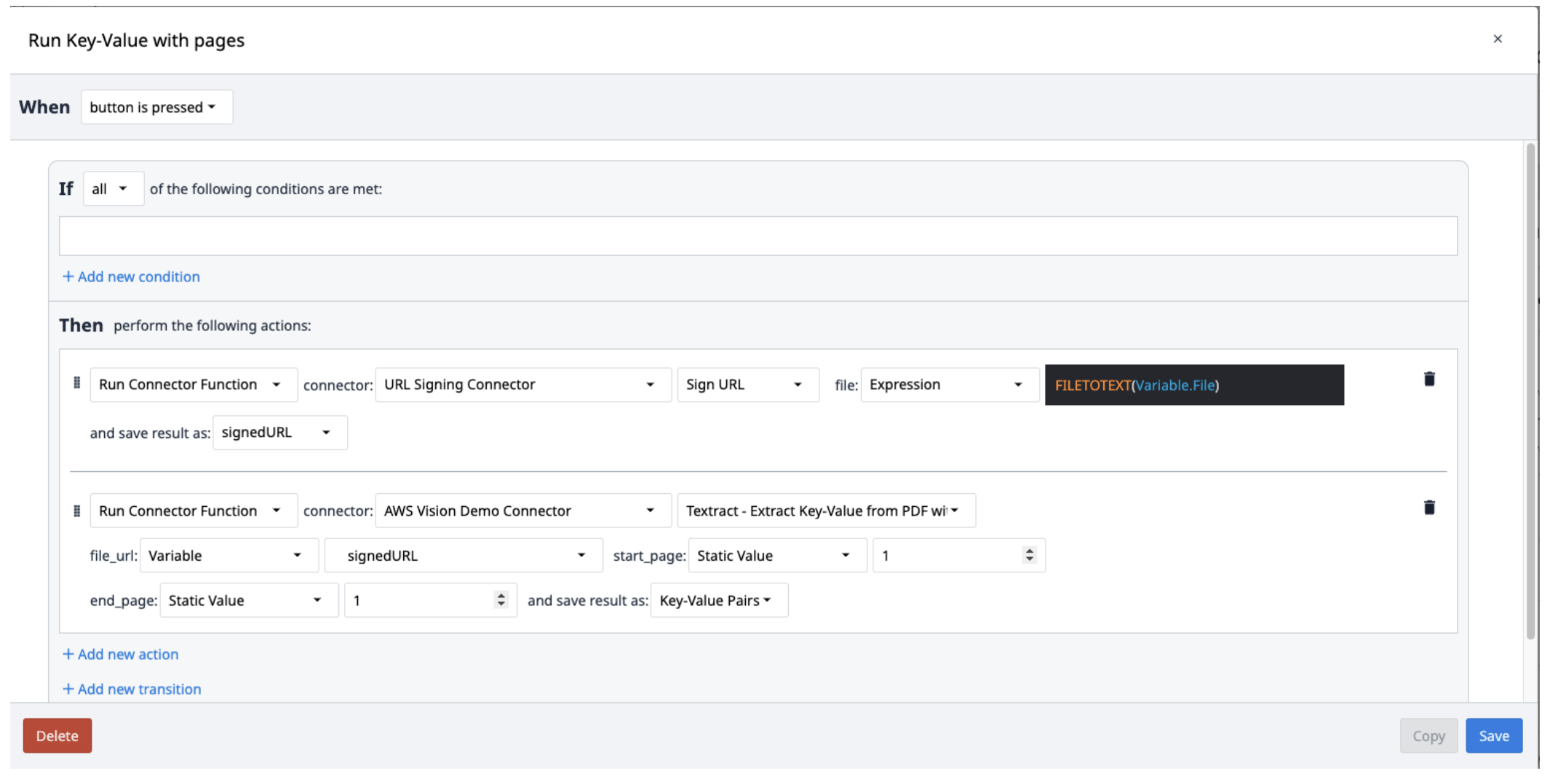
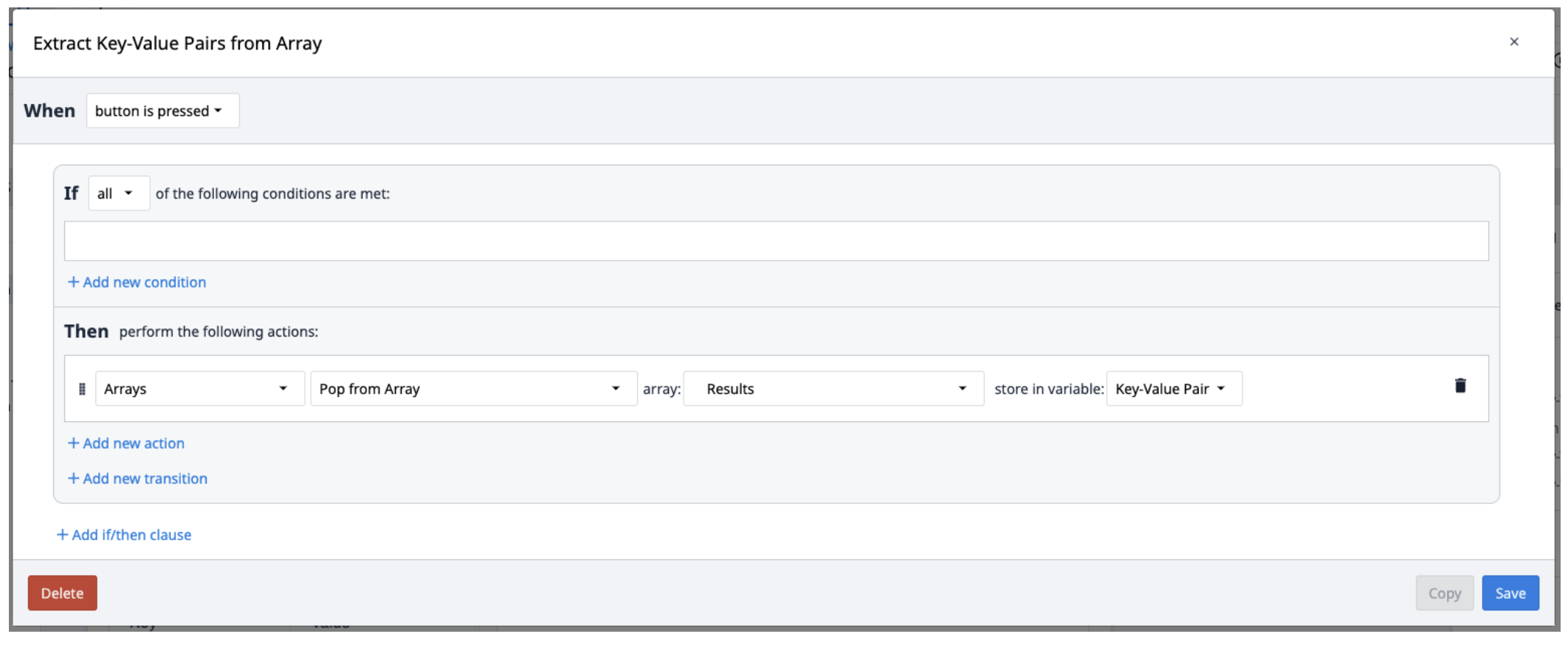
Les résultats de Textract sont enregistrés dans un tableau d'objets contenant des paires clé-valeur. Pour les extraire du tableau, créez un nouveau déclencheur qui répète l'extraction des paires du tableau au fur et à mesure des besoins.
Vous pouvez envisager d'utiliser le Looping Customer Widget pour extraire plusieurs objets du tableau.
Textract dans une application Tulip pour les requêtes (extraction à partir d'un PDF)
Dans cet exemple, nous allons voir comment utiliser Textract dans une application pour interroger des données extraites d'un PDF. Vous devrez créer et configurer une nouvelle fonction de connecteur dans le connecteur AWS, ainsi qu'utiliser une logique de déclenchement pour exécuter le connecteur. L'interrogation des données vous permet de comprendre ou de modifier les données reçues.
Détails de la fonction de connecteur
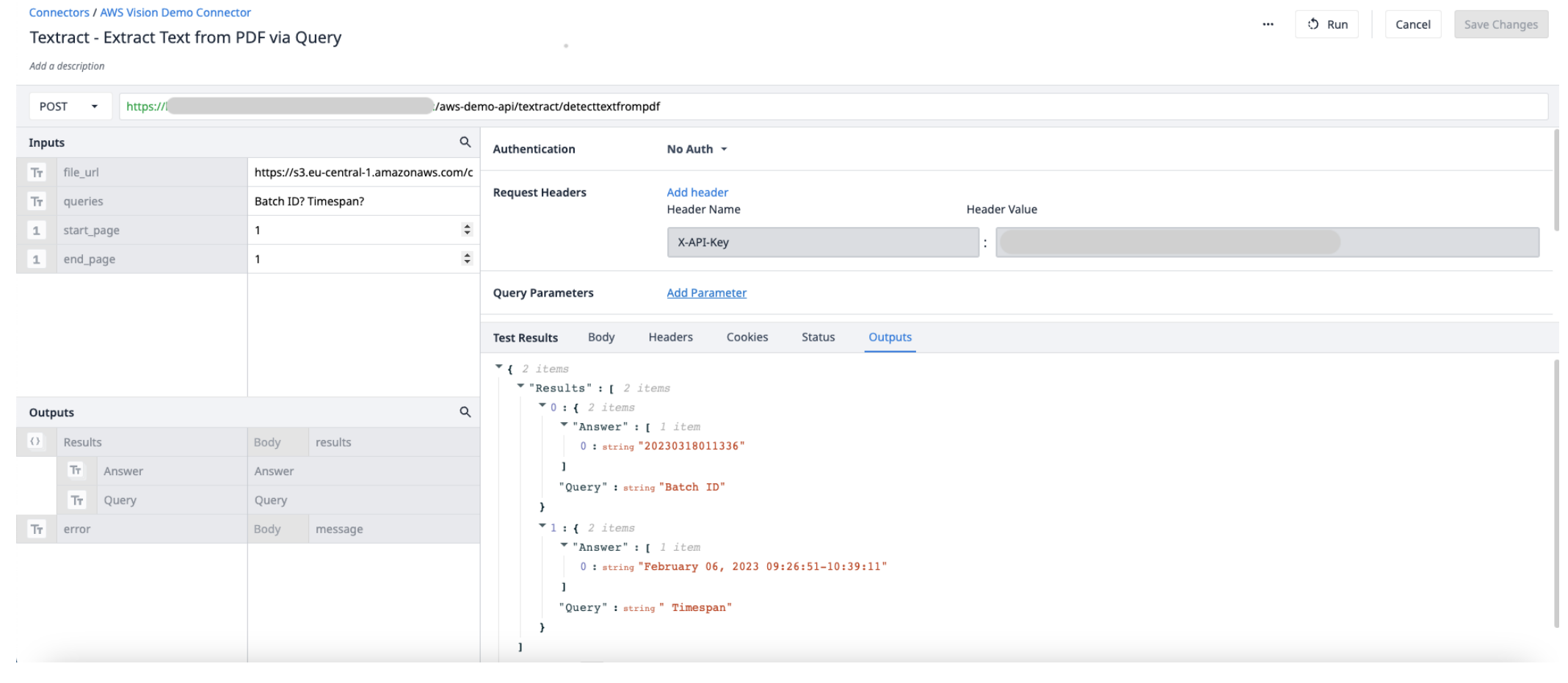
Créez une nouvelle fonction de connecteur dans le connecteur AWS. Utilisez les informations suivantes pour définir les Input et les Output.
Inputs File_url (Text) - URL du fichier PDF téléchargé sur Tulip Start_page (Int) - la première page du fichier PDF à extraire End_page (Int) - la dernière page du fichier PDF à extraire
Résultats desortie(objets) - une liste d'objets de réponses et de requêtes.
Déclencheur d'application
Dans votre application, les déclencheurs appelleront la fonction du connecteur à s'exécuter.
Créez un nouveau déclencheur avec les actions suivantes :
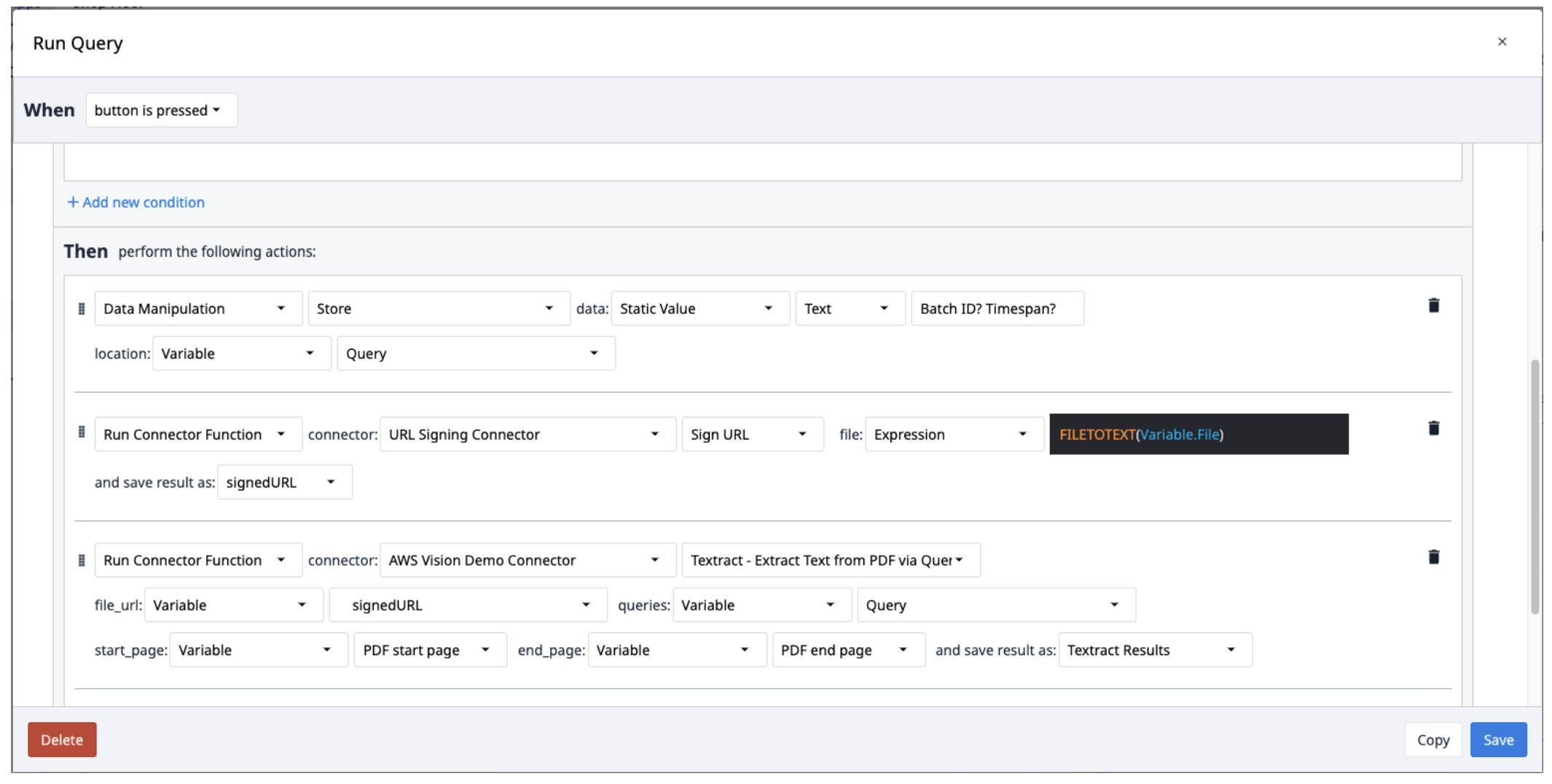
- Enregistrez les requêtes dans une variable texte séparée par des points d'interrogation (?).
- Exécutez le connecteur de signature d'URL avec la fonction Signer l'URL. Le fichier d'entrée doit être une variable texte. Utilisez l'expression FILETOTEXT (variable.File), où "File" est le nom de la variable, pour convertir le nom du fichier en une chaîne de texte. Enregistrez la sortie dans une variable et nommez-la ("SignedURL").
- Exécutez AWS Textract en extrayant le texte d'un PDF via la fonction de connecteur de requête avec l'URL de signature en entrée (file_url), la variable queries et les pages de début et de fin du PDF. Enregistrez la sortie dans un nouveau tableau.
Avez-vous trouvé ce que vous cherchiez ?
Vous pouvez également vous rendre sur community.tulip.co pour poser votre question ou voir si d'autres personnes ont rencontré une question similaire !
Cet article vous a-t-il été utile ?